
On November 6, 2023, during its inaugural DevDay, OpenAI unveiled GPT-4V (GPT-4 with Vision), another advanced multimodal model. This article aims to juxtapose LLaVA and GPT-4V, scrutinizing their strengths and weaknesses to better comprehend their functionalities and limitations.
LLaVA, or Large Language and Vision Assistant, represents an innovative open-source large multimodal model (LMM) that integrates a pre-trained CLIP ViT-L/14 visual encoder with the expansive language model Vicuna through a straightforward projection matrix. This fusion is designed for broad-spectrum visual and language comprehension. Developed by Microsoft Research and launched in September 2023, LLaVA stands out as the inaugural end-to-end trained LMM that showcases remarkable conversational abilities, paralleling the multifaceted nature of the multimodal GPT-4. Additionally, LLaVA offers a cost-effective solution for creating versatile, general-purpose multimodal assistants.
Comparing GPT-4V vs. LLaVA
Both LLaVA and GPT-4V are expansive language models equipped with multimodal features, capable of interpreting and generating both text and images. Yet, they exhibit distinct differences.
LLaVA, a product of Microsoft Research, is an open-source model. It’s trained on a comparatively smaller dataset of text and images but still boasts notable multimodal capabilities. LLaVA excels in tasks like visual question-answering, image captioning, and visual dialogue, performing many functions akin to GPT-4V.
On the other hand, GPT-4V is OpenAI’s proprietary model, built on an extensive dataset of text and images. This model is adept at producing realistic and coherent text, translating languages, crafting creative content, and providing informative answers. GPT-4V’s ability to process and comprehend images enables it to undertake tasks such as image captioning and visual question-answering.
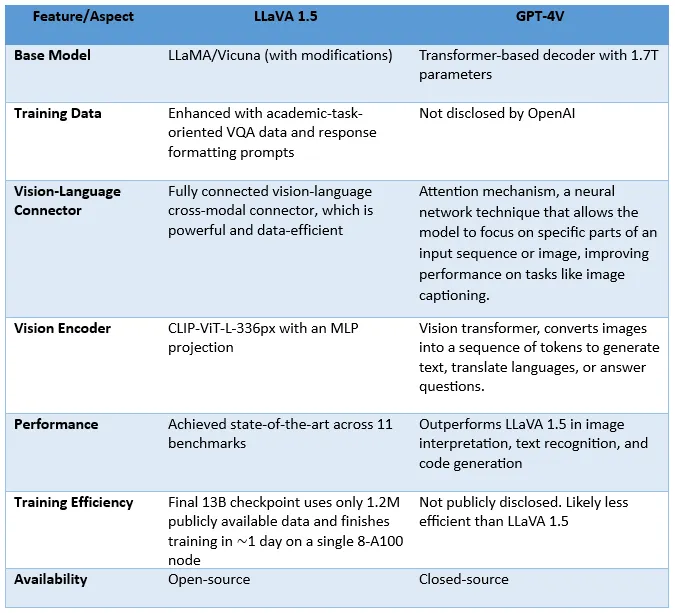
Below is a table outlining the primary distinctions between these two models.
Read related articles: