
GPT-3’s understanding of language makes it excellent at text classification. Typically, the best way to classify text with the model is GPT fine-tuning on training examples. Fine-tuned GPT-3 models can meet and exceed state-of-the-art records on text classification benchmarks. Below we list a public draft of a guide that will be added to the next revision of the OpenAI documentation.
How fine-tuning GPT-3 works
The OpenAI fine-tuning guide explains how to fine-tune your own custom version of GPT-3. You provide a list of training examples (each split into prompt and completion) and the model learns from those examples to predict the completion to a given prompt. For now you are able to fine-tune only GPT-3 model (see all models list).
Example dataset:
| Prompt | Completion |
| “burger –>” | “ edible” |
| “paper towels –>” | “ inedible” |
| “vino –>” | “ edible” |
| “bananas –>” | “ edible” |
| “dog toy –>” | “ inedible” |
In JSONL format:
{“prompt”: “burger –>”, “completion”: ” edible”}
{“prompt”: “paper towels –>”, “completion”: ” inedible”}
{“prompt”: “vino –>”, “completion”: ” edible”}
{“prompt”: “bananas –>”, “completion”: ” edible”}
{“prompt”: “dog toy –>”, “completion”: ” inedible”}
During fine-tuning, the model reads the training examples and after each token of text, it predicts the next token. This predicted next token is compared with the actual next token, and the model’s internal weights are updated to make it more likely to predict correctly in the future. As training continues, the model learns to produce the patterns demonstrated in your training examples.
After your custom model is fine-tuned, you can call it via the API to classify new examples:
| Prompt | Completion |
| “toothpaste –>” | ??? |
Example API call to get the most likely token:
api_response = openai.Completion.create(
model=”{fine-tuned model goes here, without brackets}”,
prompt=”toothpaste –>”,
temperature=0,
max_tokens=1
)
completion_text = api_response[‘choices’][0][‘text’]
if completion_text == ‘ edible’:
label = ‘edible’
elif completion_text == ‘ in’:
label = ‘inedible’
else:
label = ‘other’
As ‘ edible’ is 1 token and ‘ inedible’ is 3 tokens, in this example, we request just one completion token and count ‘ in’ as a match for ‘ inedible’.
Example API call to get probabilities for the 5 most likely tokens:
api_response = openai.Completion.create(
model=”{fine-tuned model goes here, without brackets}”,
prompt=”toothpaste –>”,
temperature=0,
max_tokens=1,
logprobs=5
)
dict_of_logprobs = api_response[‘choices’][0][‘logprobs’][‘top_logprobs’][0].to_dict()
dict_of_probs = {k: 2.718**v for k, v in dict_of_logprobs.items()}
Training data
The most important determinant of success is training data.
Your training data should be:
- Large (ideally thousands or tens of thousands of examples)
- High-quality (consistently formatted and cleaned of incomplete or incorrect examples)
- Representative (training data should be similar to the data upon which you’ll use your model)
- Sufficiently specified (i.e., containing enough information in the input to generate what you want to see in the output)
If you aren’t getting good results, the first place to look is your training data. Try following the tips below about data formatting, label selection, and quantity of training data needed. Also review our list of common mistakes.
How to format your training data
Prompts for a fine-tuned model do not typically need instructions or examples, as the model can learn the task from the training examples. Including instructions shouldn’t hurt performance, but the extra text tokens will add cost to each API call.
| Prompt | Tokens | Recommended |
| “burger –>” | 3 | ✅ |
| “Label the following item as either edible or inedible. Item: burgerLabel:” | 20 | ❌ |
| “Item: cakeCategory: edible Item: panCategory: inedible Item: burgerCategory:” | 26 | ❌ |
Instructions can still be useful when fine-tuning a single model to do multiple tasks. For example, if you train a model to classify multiple features from the same text string (e.g., whether an item is edible or whether it’s handheld), you’ll need some type of instruction to tell the model which feature you want labeled.
Example training data:
| Prompt | Completion |
| “burger –> edible:” | “ yes” |
| “burger –> handheld:” | “ yes” |
| “car –> edible:” | “ no” |
| “car –> handheld:” | “ no” |
Example prompt for unseen example:
| Prompt | Completion |
| “cheese –> edible:” | ??? |
Note that for most models, the prompt + completion for each example must be less than 2048 tokens (roughly two pages of text). For text-davinci-002, the limit is 4000 tokens (roughly four pages of text).
Separator sequences
For classification, end your text prompts with a text sequence to tell the model that the input text is done and the classification should begin. Without such a signal, the model may append additional invented text before appending a class label, resulting in outputs like:
- burger edible (accurate)
- burger and fries edible (not quite was asked for)
- burger-patterned novelty tie inedible (inaccurate)
- burger burger burger burger (no label generated)
Examples of separator sequences
| Prompt | Recommended |
| “burger” | ❌ |
| “burger –>” | ✅ |
| “burger ### “ | ✅ |
| “burger >>>” | ✅ |
| “burger Label:” | ✅ |
Be sure that the sequence you choose is very unlikely to otherwise appear in your text (e.g., avoid ‘###’ or ‘->’ when classifying Python code). Otherwise, your choice of sequence usually doesn’t matter much.
How to pick labels
One common question is what to use as class labels.
In general, fine-tuning can work with any label, whether the label has semantic meaning (e.g., “ edible”) or not (e.g., “1”). That said, in cases with little training data per label, it’s possible that semantic labels work better, so that the model can leverage its knowledge of the label’s meaning.
When convenient, we recommend single-token labels. You can check the number of tokens in a string with the OpenAI tokenizer. Single-token labels have a few advantages:
- Lowest cost
- Easier to get their probabilities, which are useful for metrics confidence scores, precision, recall
- No hassle from specifying stop sequences or post-processing completions in order to compare labels of different length
Example labels
| Prompt | Label | Recommended |
| “burger –>” | “ edible” | ✅ |
| “burger –>” | “ 1” | ✅ |
| “burger –>” | “ yes” | ✅ |
| “burger –>” | “ A burger can be eaten” | ❌ (but still works) |
One useful fact: all numbers <500 are single tokens.
If you do use multi-token labels, we recommend that each label begin with a different token. If multiple labels begin with the same token, an unsure model might end up biased toward those labels.
How much training data do you need
How much data you need depends on the task and desired performance.
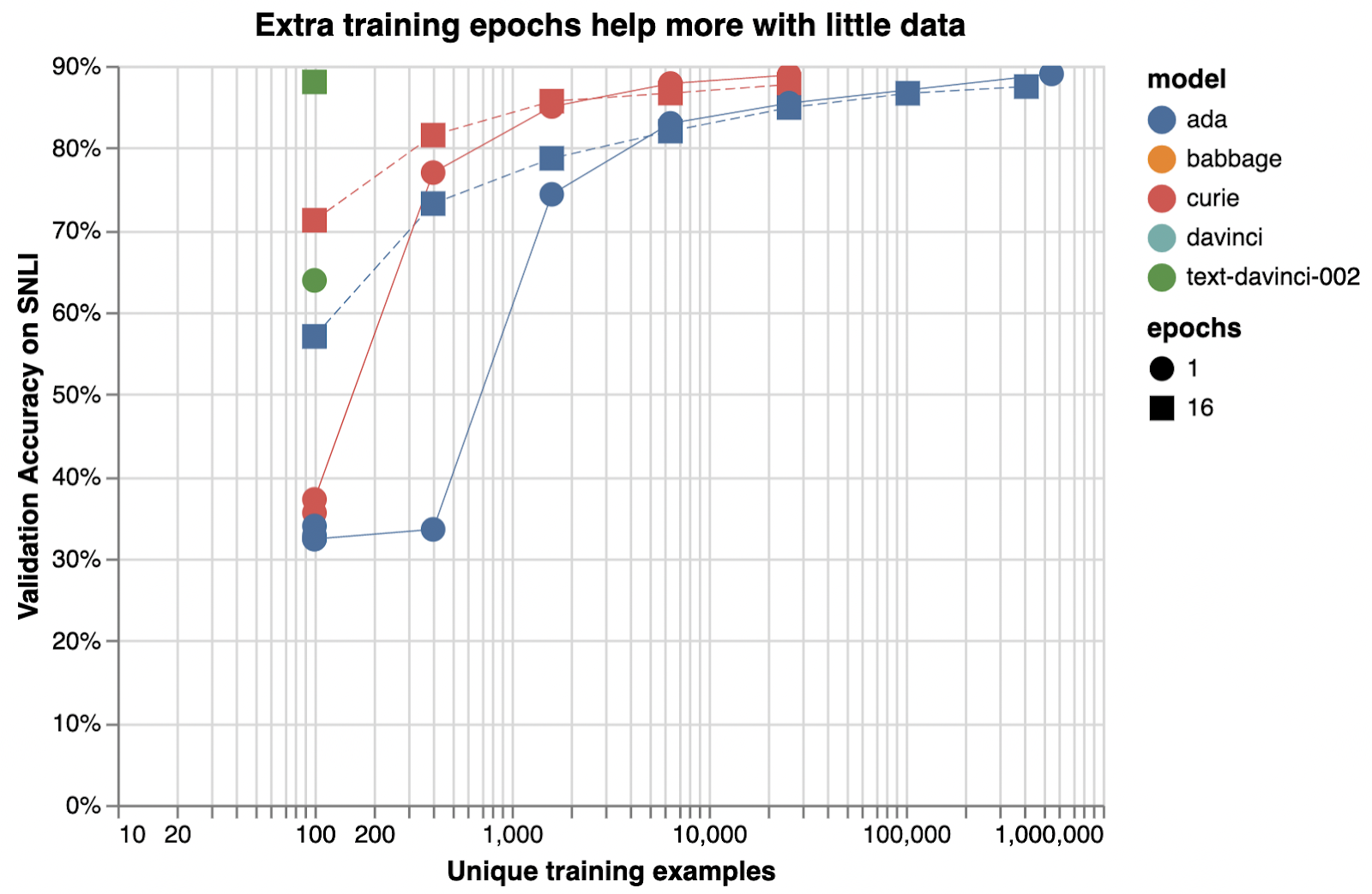
Below is an illustrative example of how adding training examples improves classification accuracy.

Illustrative examples of text classification performance on the Stanford Natural Language Inference (SNLI) Corpus, in which ordered pairs of sentences are classified by their logical relationship: either contradicted, entailed (implied), or neutral. Default fine-tuning parameters were used when not otherwise specified.
Very roughly, we typically see that a few thousand examples are needed to get good performance:
| Examples per label | Performance (rough estimate) |
| Hundreds | Decent |
| Thousands | Good |
| Tens of thousands or more | Great |
To assess the value of getting more data, you can train models on subsets of your current dataset—e.g., 25%, 50%, 100%—and then see how performance scales with dataset size. If you plot accuracy versus number of training examples, the slope at 100% will indicate the improvement you can expect from getting more data. (Note that you cannot infer the value of additional data from the evolution of accuracy during a single training run, as a model half-trained on twice the data is not equivalent to a fully trained model.)
How to evaluate your GPT fine-tuned model
Evaluating your fine-tuned model is crucial to (a) improve your model and (b) tell when it’s good enough to be deployed.
Many metrics can be used to characterize the performance of a classifier
- Accuracy
- F1
- Precision / Positive Predicted Value / False Discovery Rate
- Recall / Sensitivity
- Specificity
- AUC / AUROC (area under the receiver operator characteristic curve)
- AUPRC (area under the precision recall curve)
- Cross entropy
Which metric to use depends on your specific application and how you weigh different types of mistakes. For example, if detecting something rare but consequential, where a false negative is costlier than a false positive, you might care about recall more than accuracy.
The OpenAI API offers the option to calculate some of these classification metrics. If enabled, these metrics will be periodically calculated during fine-tuning as well as for your final model. You will see them as additional columns in your results file.
To enable classification metrics, you’ll need to:
- use single-token class labels
- provide a validation file (same format as the training file)
- set the flag –compute_classification_metrics
- for multiclass classification: set the argument –classification_n_classes
- for binary classification: set the argument –classification_positive_class
Example fine-tuning calls using the OpenAI CLI
“`
# For multiclass classification
openai api fine_tunes.create \
-t <TRAIN_FILE_ID_OR_PATH> \
-v <VALIDATION_FILE_OR_PATH> \
-m <MODEL> \
–compute_classification_metrics \
–classification_n_classes <NUMBER_OF_CLASSES>
# For binary classification
openai api fine_tunes.create \
-t <TRAIN_FILE_ID_OR_PATH> \
-v <VALIDATION_FILE_OR_PATH> \
-m <MODEL> \
–compute_classification_metrics \
–classification_n_classes 2 \
–classification_positive_class <POSITIVE_CLASS_FROM_DATASET>
“`
The following metrics will be displayed in your results file if you set –compute_classification_metrics:
For multiclass classification
- classification/accuracy: accuracy
- classification/weighted_f1_score: weighted F-1 score
For binary classification
The following metrics are based on a classification threshold of 0.5 (i.e. when the probability is > 0.5, an example is classified as belonging to the positive class.)
- classification/accuracy
- classification/precision
- classification/recall
- classification/f{beta}
- classification/auroc – AUROC
- classification/auprc – AUPRC
Note that these evaluations assume that you are using text labels for classes that tokenize down to a single token, as described above. If these conditions do not hold, the numbers you get will likely be wrong.
Example outputs
Example metrics evolution over a training run, visualized with Weights & Biases
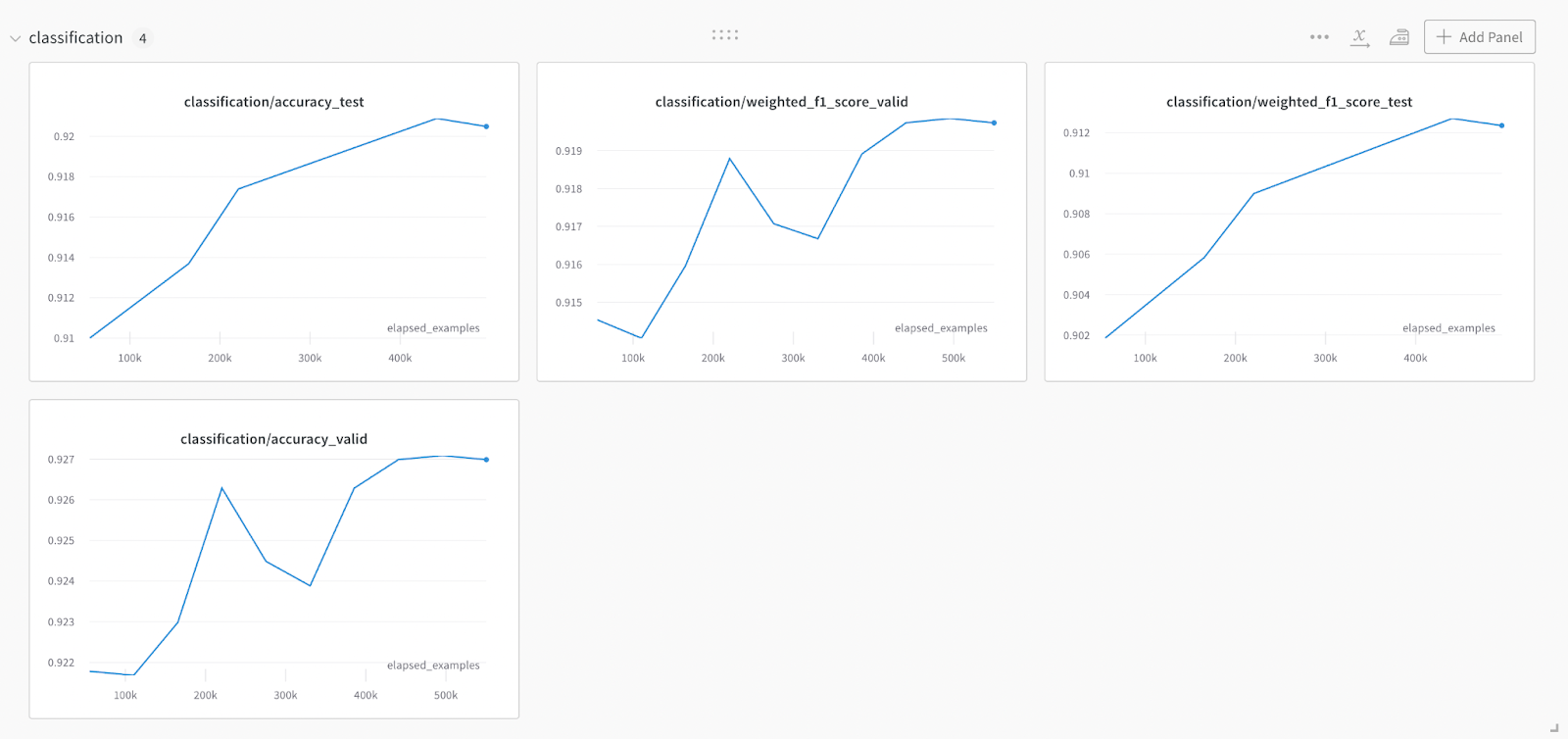
How to pick the right model
OpenAI offers fine-tuning for 5 models:
- ada (cheapest and fastest)
- babbage
- curie
- davinci
- text-davinci-002 (highest quality)
Which model to use will depend on your use case and how you value quality versus price and speed.
Generally, we see text classification use cases falling into two categories: simple and complex.
For tasks that are simple or straightforward, such as classifying sentiment, larger models offer diminishing benefit, as illustrated below:
| Model | Illustrative accuracy* | Training cost** | Inference cost** |
| ada | 89% | $0.0004 / 1K tokens (~3,000 pages per dollar) | $0.0016 / 1K tokens (~800 pages per dollar) |
| babbage | 90% | $0.0006 / 1K tokens (~2,000 pages per dollar) | $0.0024 / 1K tokens (~500 pages per dollar) |
| curie | 91% | $0.003 / 1K tokens (~400 pages per dollar) | $0.012 / 1K tokens (~100 pages per dollar) |
| davinci | 92% | $0.03 / 1K tokens (~40 pages per dollar) | $0.12 / 1K tokens (~10 pages per dollar) |
| text-davinci-002 | 93% | unreleased | unreleased |
**Pages per dollar figures assume ~800 tokens per page. OpenAI Pricing.
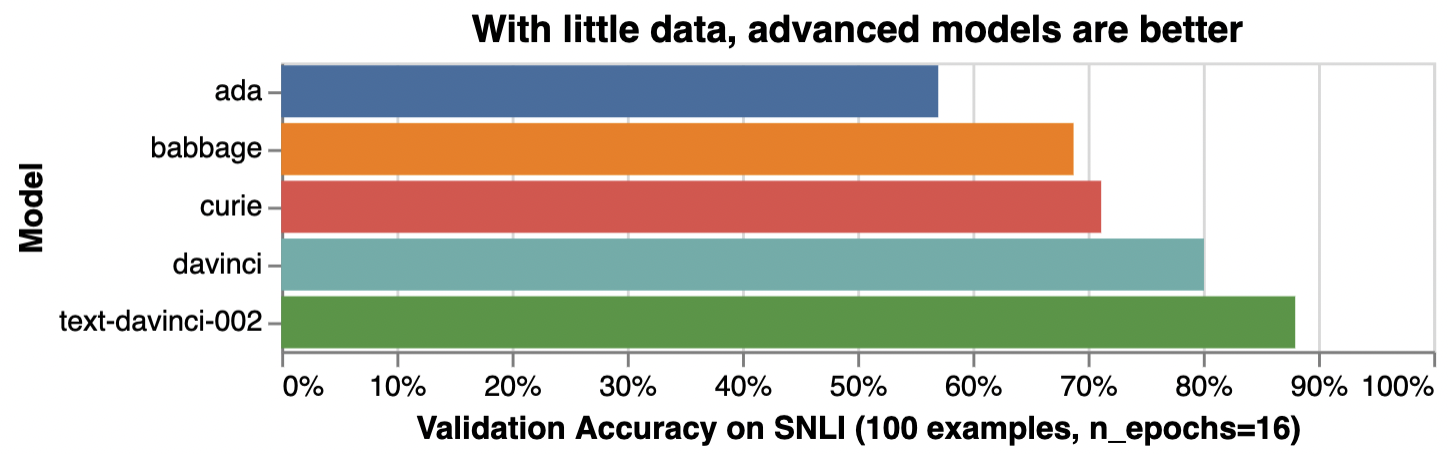

Illustrative examples of text classification performance on the Stanford Natural Language Inference (SNLI) Corpus, in which ordered pairs of sentences are classified by their logical relationship: either contradicted, entailed (implied), or neutral. Default fine-tuning parameters were used when not otherwise specified.
For complex tasks, requiring subtle interpretation or reasoning or prior knowledge or coding ability, the performance gaps between models can be larger, and better models like curie or text-davinci-002 could be the best fit.
A single project might end up trying all models. One illustrative development path might look like this:
Test code using the cheapest & fastest model (ada)
Run a few early experiments to check whether your dataset works as expected with a middling model (curie)
Run a few more experiments with the best model to see how far you can push performance (text-davinci-002)
Once you have good results, do a training run with all models to map out the price-performance frontier and select the model that makes the most sense for your use case (ada, babbage, curie, davinci, text-davinci-002)
Another possible development path that uses multiple models could be:
Starting with a small dataset, train the best possible model (text-davinci-002)
Use this fine-tuned model to generate many more labels and expand your dataset by multiples
Use this new dataset to train a cheaper model (ada).
How to pick training hyperparameters
GPT Fine-tuning can be adjusted with various parameters. Typically, the default parameters work well and adjustments only result in small performance changes.
| Parameter | Default | Recommendation |
| n_epochscontrols how many times each example is trained on | 4 | For classification, we’ve seen good performance with numbers like 4 or 10. Small datasets may need more epochs and large datasets may need fewer epochs. If you see low training accuracy, try increasing n_epochs. If you see high training accuracy but low validation accuracy (overfitting), try lowering n_epochs. You can get training and validation accuracies by setting compute_classification_metrics to True and passing a validation file with labeled examples not in the training data. You can see graphs of these metrics evolving during fine-tuning with a Weights & Biases account. |
| batch_sizecontrols the number of training examples used in a single training pass | null(which dynamically adjusts to 0.2% of training set, capped at 256) | We’ve seen good performance in the range of 0.01% to 2%, but worse performance at 5%+. In general, larger batch sizes tend to work better for larger datasets. |
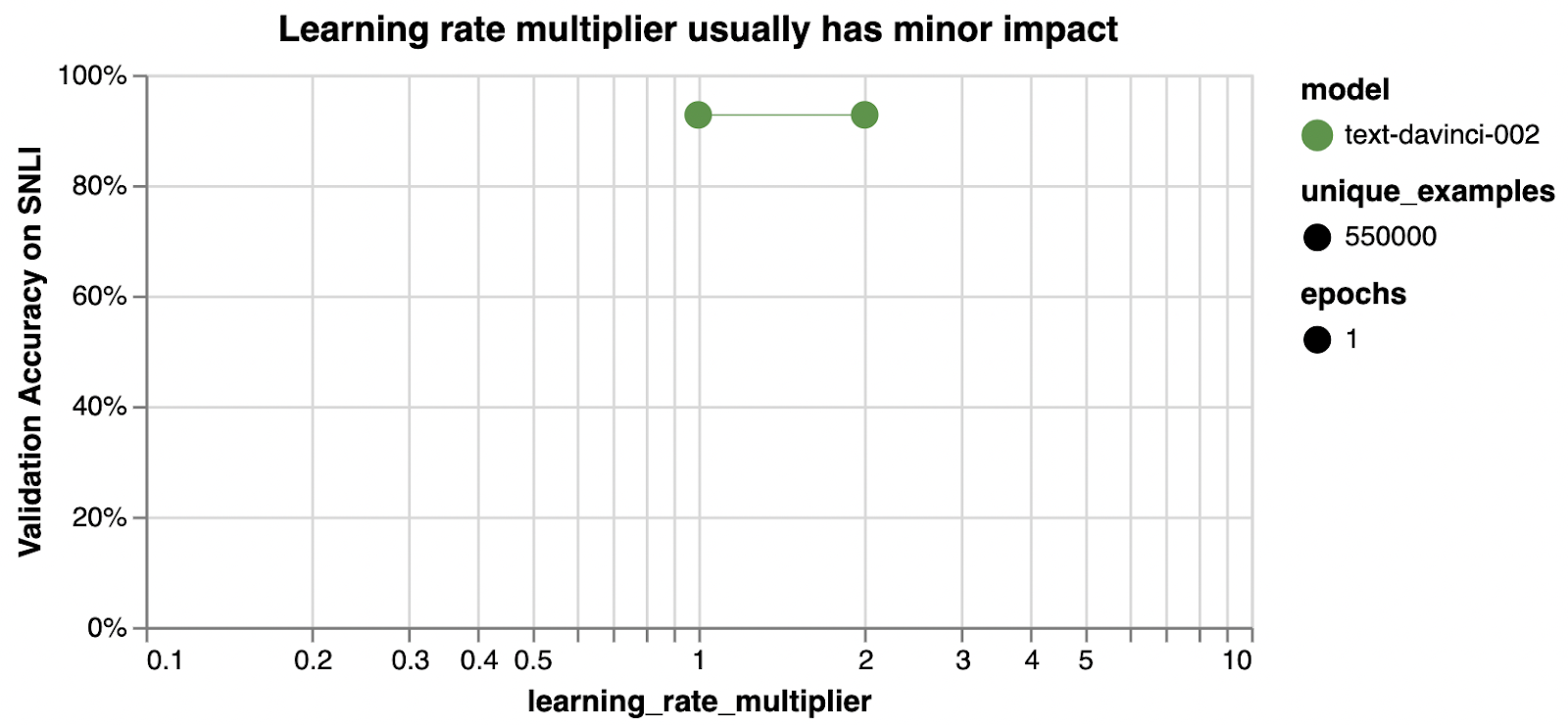
| learning_rate_multiplier controls rate at which the model weights are updated | null(which dynamically adjusts to 0.05, 0.1, or 0.2 depending on batch size) | We’ve seen good performance in the range of 0.02 to 0.5. Larger learning rates tend to perform better with larger batch sizes. |
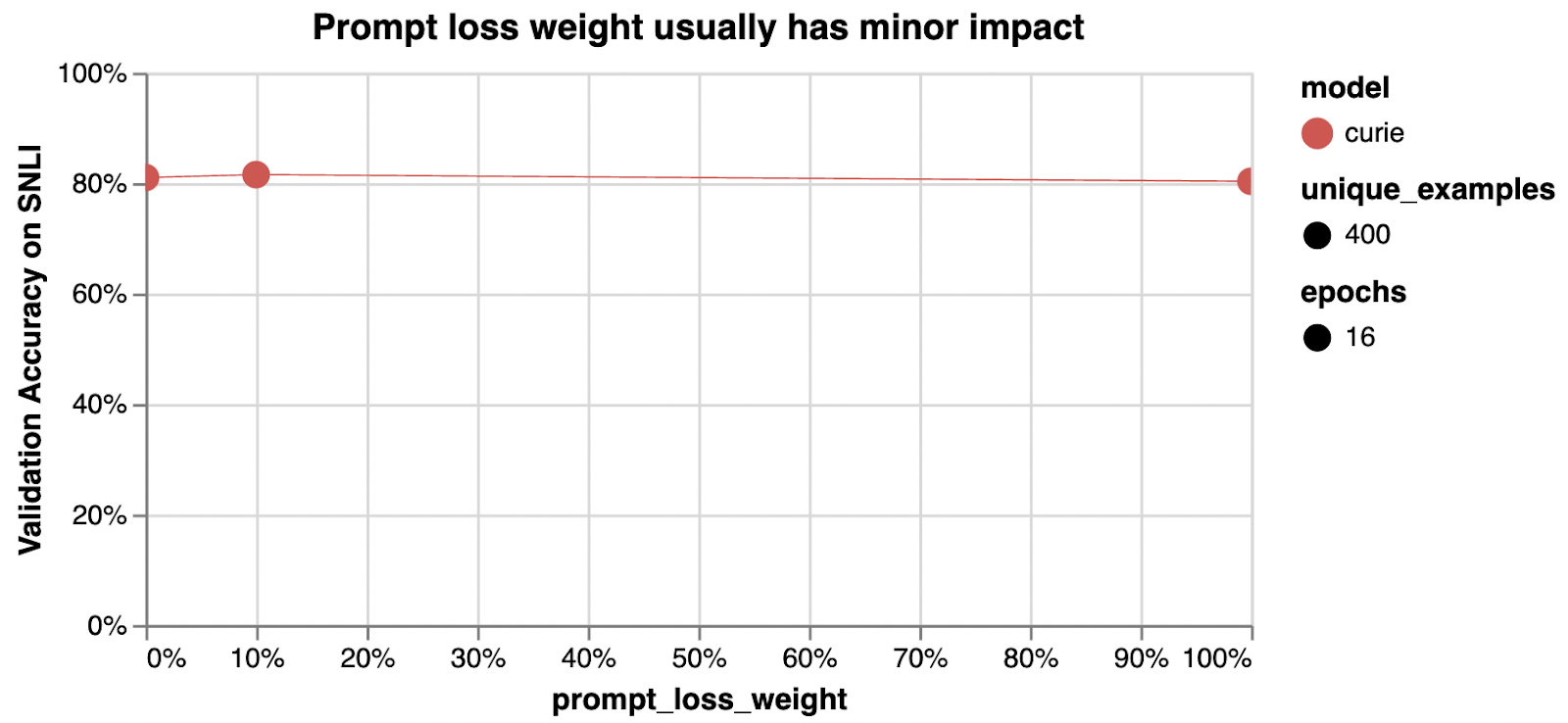
| prompt_loss_weightcontrols how much the model learns from prompt tokens vs completion tokens | 0.1 | If prompts are very long relative to completions, it may make sense to reduce this weight to avoid over-prioritizing learning the prompt. In our tests, reducing this to 0 is sometimes slightly worse or sometimes about the same, depending on the dataset. |
More detail on prompt_loss_weight
When a GPT model is fine-tuned, it learns to produce text it sees in both the prompt and the completion. In fact, from the point of view of the model being fine-tuned, the distinction between prompt and completion is mostly arbitrary. The only difference between prompt text and completion text is that the model learns less from each prompt token than it does from each completion token. This ratio is controlled by the prompt_loss_weight, which by default is 10%.
A prompt_loss_weight of 100% means that the model learns from prompt and completion tokens equally. In this scenario, you would get identical results with all training text in the prompt, all training text in the completion, or any split between them. For classification, we recommend against 100%.
A prompt loss weight of 0% means that the model’s learning is focused entirely on the completion tokens. Note that even in this case, prompts are still necessary because they set the context for each completion. Sometimes we’ve seen a weight of 0% reduce classification performance slightly or make results slightly more sensitive to learning rate; one hypothesis is that a small amount of prompt learning helps preserve or enhance the model’s ability to understand inputs.
Example hyperparameter sweeps
n_epochs
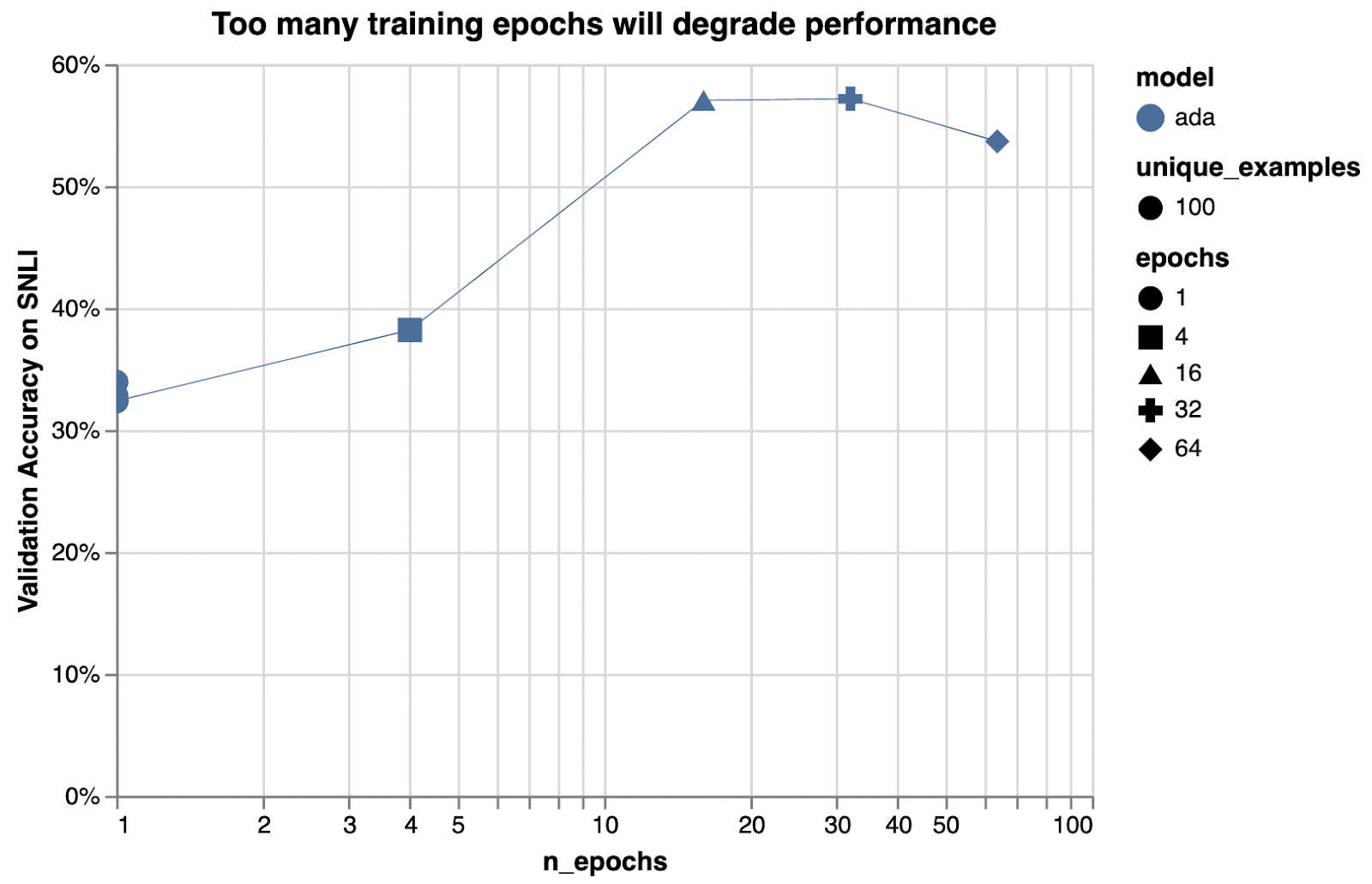
The impact of additional epochs is particularly high here, because only 100 training examples were used.
learning_rate_multiplier
prompt_loss_weight
How to pick inference parameters
| Parameter | Recommendation |
| model | (discussed above) [add link] |
| temperature | Set temperature=0 for classification. Positive values add randomness to completions, which can be good for creative tasks but is bad for a short deterministic task like classification. |
| max_tokens | If using single-token labels (or labels with unique first tokens), set max_tokens=1. If using longer labels, set to the length of your longest label. |
| stop | If using labels of different length, you can optionally append a stop sequence like ‘ END’ to your training completions. Then, pass stop=‘ END’ in your inference call to prevent the model from generating excess text after appending short labels. (Otherwise, you can get completions like “burger –>” “ edible edible edible edible edible edible” as the model continues to generate output after the label is appended.) An alternative solution is to post-process the completions and look for prefixes that match any labels. |
| logit_bias | If using single-token labels, set logit_bias={“label1”: 100, “label2”:100, …} with your labels in place of “label1” etc. For tasks with little data or complex labels, models can output tokens for invented classes never specified in your training set. logit_bias can fix this by upweighting your label tokens so that illegal label tokens are never produced. If using logit_bias in conjunction with multi-token labels, take extra care to check how your labels are being split into tokens, as logit_bias only operates on individual tokens, not sequences. Logit_bias can also be used to bias specific labels to appear more or less frequently. |
| logprobs | Getting the probabilities of each label can be useful for computing confidence scores, precision-recall curves, calibrating debiasing using logit_bias, or general debugging. Setting logprobs=5 will return, for each token position of the completion, the top 5 most likely tokens and the natural logs of their probabilities. To convert logprobs into probabilities, raise e to the power of the logprob (probability = e^logprob). The probabilities returned are independent of temperature and represent what the probability would have been if the temperature had been set to 1. By default 5 is the maximum number of logprobs returned, but exceptions can be requested by emailing support@openai.com and describing your use case. Example API call to get probabilities for the 5 most likely tokensapi_response = openai.Completion.create( model=”{fine-tuned model goes here, without brackets}”, prompt=”toothpaste –>”, temperature=0, max_tokens=1, logprobs=5)dict_of_logprobs = api_response[‘choices’][0][‘logprobs’][‘top_logprobs’][0].to_dict()dict_of_probs = {k: 2.718**v for k, v in dict_of_logprobs.items()} |
| echo | In cases where you want the probability of a particular label that isn’t showing up in the list of logprobs, the echo parameter is useful. If echo is set to True and logprobs is set to a number, the API response will include logprobs for every token of the prompt as well as the completion. So, to get the logprob for any particular label, append that label to the prompt and make an API call with echo=True, logprobs=0, and max_tokens=0. Example API call to get the logprobs of prompt tokensimport openai response = openai.Completion.create( model=”text-davinci-002″, prompt=”burger –> edible”, temperature=0, max_tokens=0, logprobs=0, echo=True) print(response[‘choices’][0][‘logprobs’][‘token_logprobs’]) ===[None, -0.8182136, -7.7480173, -15.915648] |
Read more related articles: