
While we were busy with Claude 3.5 Sonnet, GroqInc launched an API for OpenAI’s Whisper-large-v3 model. This is an insanely fast speech-text solution. And it only costs $0.03 per hour of transcription! Here’s the code to use Groq’s whisper API with the OpenAI client!
from openai import OpenAI
groq = OpenAI (api_key="GROQ_API_KEY" ,
base_url="https://api.groq.com/openai/v1")
audio_file = open ("/ content/sample_audio.mp3", "Ib")
transcript = groq.audio.transcriptions.create(
model="whisper-large-v3", file=audio_file, response_format="text"
print (transcript)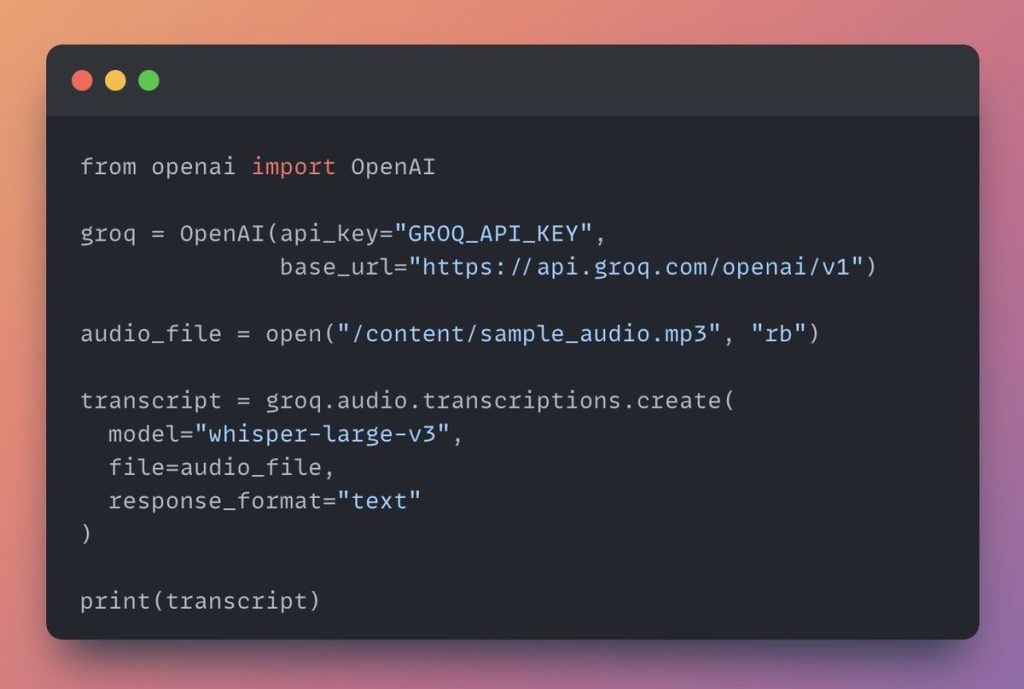
What is Whisper?
Whisper is a pre-trained model designed for automatic speech recognition (ASR) and speech translation. It has been trained on 680,000 hours of labeled data, demonstrating a robust ability to generalize across various datasets and domains without the need for fine-tuning.
The model was introduced in the paper “Robust Speech Recognition via Large-Scale Weak Supervision” by Alec Radford et al. from OpenAI. The original code repository is available here.
Whisper large-v3 maintains the same architecture as the previous large models, with a few minor adjustments:
- The input now uses 128 Mel frequency bins instead of 80.
- A new language token for Cantonese has been added.
Whisper large-v3 was trained on 1 million hours of weakly labeled audio and 4 million hours of pseudolabeled audio collected using Whisper large-v2. The training spanned 2.0 epochs over this mixed dataset.
The large-v3 model exhibits improved performance across a wide range of languages, achieving a 10% to 20% reduction in errors compared to Whisper large-v2.
Read more: Whisper large-v3 model vs large-v2 model
Read related articles: