
OpenAI’s GPT-4 is utilized for content policy development and content moderation decisions, allowing for more uniform labeling, a quicker feedback mechanism for policy improvement, and decreased reliance on human moderators.
Content moderation is pivotal in ensuring the vitality of online platforms. Incorporating GPT-4 in a content moderation system facilitates rapid alterations in policies, shortening the usual cycle from months to mere hours. GPT-4 has the capability to comprehend and adjust to detailed content policy documents, ensuring consistent labeling.
This presents a promising vision for digital platforms’ future, where AI can efficiently regulate online content as per platform-specific rules, thus reducing the workload on human moderators. Anyone possessing OpenAI API access can adopt this strategy to design their own AI-powered moderation system.
Challenges in Content Moderation
The content moderation task requires careful attention, sensitivity, deep contextual understanding, and swift adaptability to emerging scenarios, making it both lengthy and demanding. Historically, this responsibility was primarily shouldered by human moderators who meticulously screened vast amounts of content, eliminating harmful elements, with assistance from niche-specific machine learning models. This traditional method is inherently sluggish and often strains human moderators mentally.
Usage of Large Language Models (LLMs)
OpenAI is delving into the potential of LLMs to tackle these challenges. Their LLMs, such as GPT-4, possess the ability to interpret and produce human-like language, positioning them aptly for content moderation tasks. These models can render moderation decisions as per the policy guidelines fed to them.
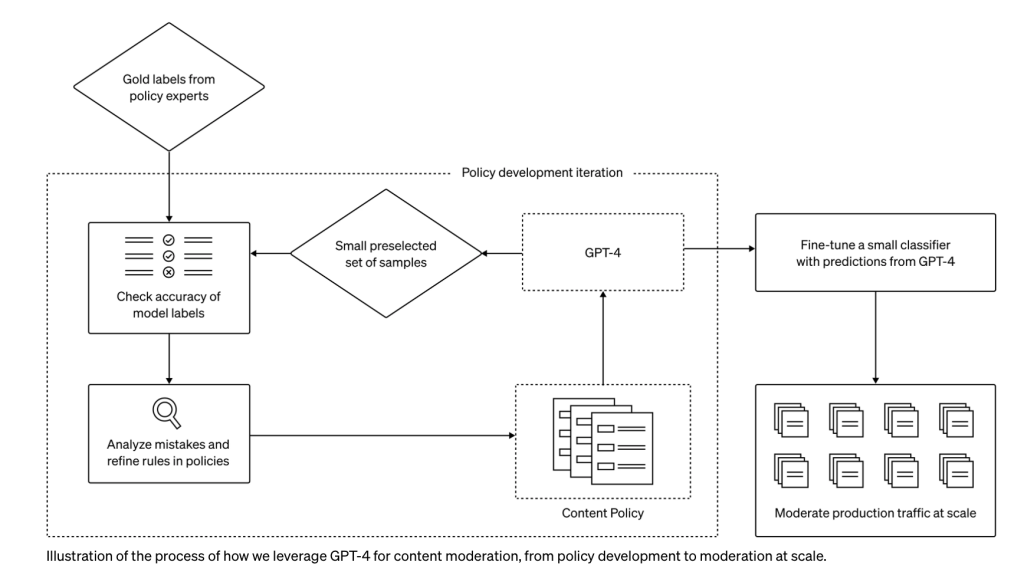
This new approach shortens the policy development and customization process from months to hours. Upon drafting a policy guideline, experts can collate a preliminary dataset by identifying select examples and labeling them per the policy. GPT-4 then reviews the policy, labeling the dataset independently, blind to prior answers.
By contrasting GPT-4’s decisions with human judgments, experts can query GPT-4 about its labeling rationale, highlight ambiguous policy terms, address confusions, and provide further clarity in the policy when necessary. This procedure is repeated until the desired policy quality is achieved. The finalized policy is then converted into classifiers, facilitating its deployment for mass content moderation. If required, for handling vast datasets, GPT-4’s predictions can be employed to hone a more compact model.
Advantages
Such an innovative method introduces several advancements over traditional content moderation practices:
- Enhanced Consistency: As content policies are dynamic and intricate, interpretations can differ among humans. LLMs, sensitive to minute wording variations, can swiftly acclimate to policy updates, ensuring uniform content delivery.
- Swift Feedback Loop: The routine of policy modifications – introducing a fresh policy, labeling, and accruing human feedback – can be protracted. GPT-4 compresses this cycle to hours, allowing swifter reactions to emerging issues.
- Reduced Strain: Constant exposure to detrimental content can emotionally drain human moderators. Automating such tasks safeguards their mental health.
In contrast to Constitutional AI (Bai, et al. 2022) which predominantly depends on the model’s inherent judgment, OpenAI’s method accelerates platform-specific content policy modifications. OpenAI urges Trust & Safety professionals to consider this model for content moderation, noting that anyone with API access can currently conduct similar experiments.
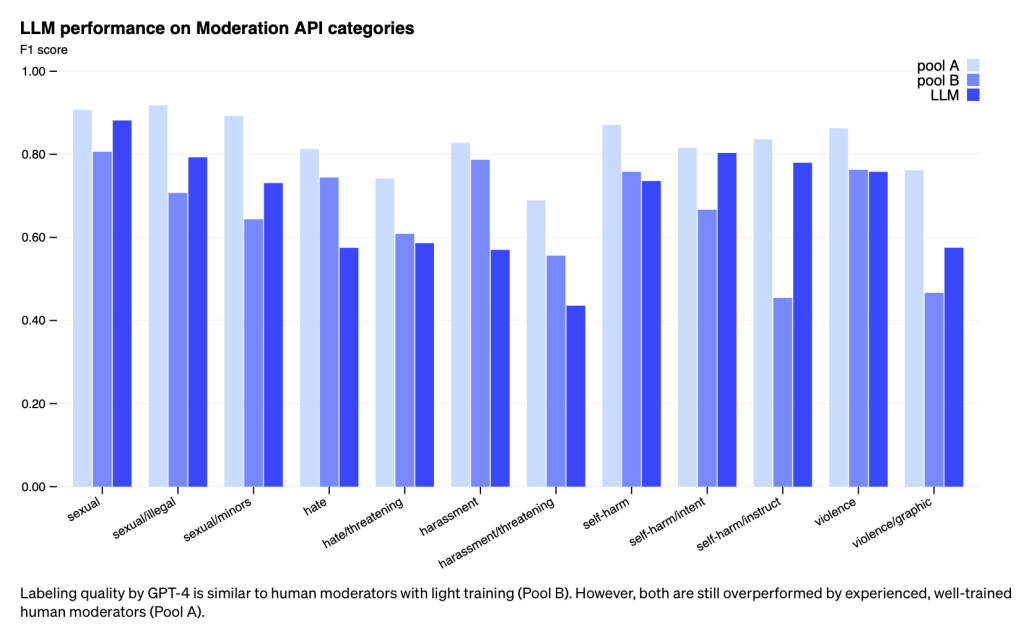
OpenAI is devoted to enhancing GPT-4’s predictive accuracy, possibly by adding chain-of-thought reasoning or self-evaluation. They are also pioneering methods to identify undisclosed risks and, influenced by Constitutional AI, strive to employ models to spot potentially noxious content based on broad definitions of harm. These discoveries would subsequently guide policy updates or the formulation of policies for new risk domains.
Limitations
Language model decisions can sometimes reflect biases from their training data. Like all AI tools, their outputs necessitate vigilant oversight, verification, and fine-tuning, with human moderation remaining vital. By transitioning some moderation tasks to LLMs, human efforts can center on intricate edge cases vital for policy enhancement. OpenAI continues to champion transparency and pledges to update the community on their advancements.
Read more related articles: