GPT language models process textual data in units known as GPT tokens. In the English language, tokens could be as short as a single character or as long as a full word (such as ‘a’ or ‘apple’). In some other languages, tokens could either be shorter or longer than a single character or word.
Take for instance the phrase:
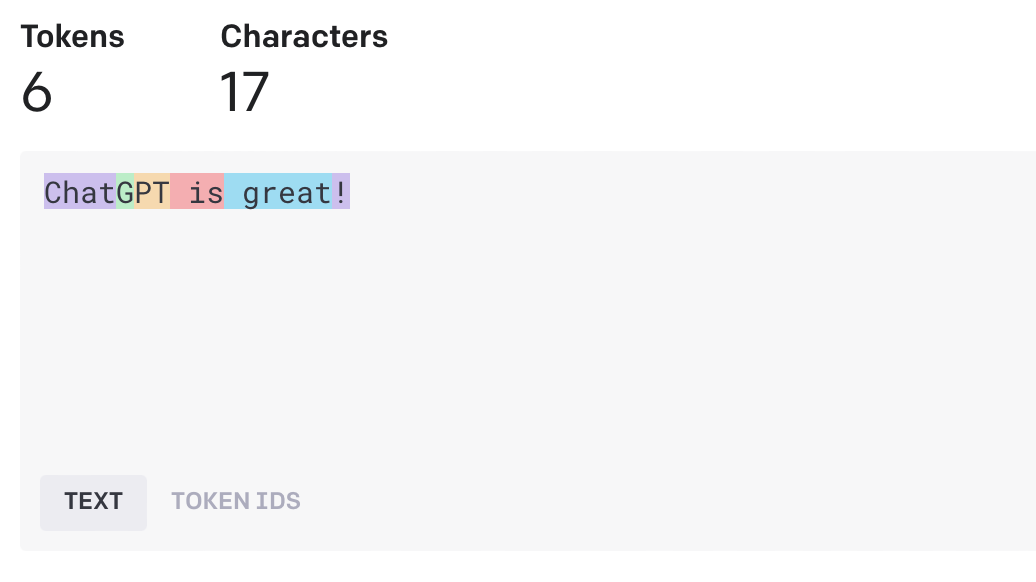
“ChatGPT is great!”
It is split into six tokens as follows: [“Chat”, “G”, “PT”, ” is”, ” great”, “!”].
The total number of tokens an API call uses influences the following:
- The cost of the API call, as billing is done per token
- The duration of the API call, as more tokens take longer to process
- The functionality of the API call, as the number of total tokens should be within the model’s limit (for instance,
gpt-3.5-turbohas a maximum limit of 4096 tokens)
Both input and output tokens are counted. As an example, if you have 10 tokens in the input message and receive 20 tokens in the output message, you will be billed for 30 tokens. However, it’s important to note that some models charge differently for input and output tokens (more details can be found on the pricing page).
To understand how many tokens an API call uses, refer to the ‘usage’ field in the API response (for instance, response['usage']['total_tokens']).
Language models such as gpt-3.5-turbo and gpt-4 employ tokens similarly as those in the completions API. However, due to their conversation-based format, determining the number of tokens used can be more challenging.
GPT Tiktoken
You can ascertain the number of tokens in a text string without initiating an API call through the tiktoken Python library provided by OpenAI. Example code can be found in the OpenAI Cookbook’s guide on how to count tokens with tiktoken.
Each message sent to the API uses a certain number of tokens found in the content, role, and other fields, plus a few extra for internal formatting. This may be subject to minor changes in the future.
If a conversation exceeds the maximum token limit of a model (like over 4096 tokens for gpt-3.5-turbo), it will be necessary to trim, omit, or reduce your text until it fits. Be aware that if a message is excluded from the message input, the model will have no memory of it.
Lastly, bear in mind that exceptionally lengthy conversations are prone to receiving incomplete responses. For instance, a gpt-3.5-turbo conversation that is 4090 tokens long will have its response truncated after just 6 tokens.
Read more related articles: