
Open-Source LLMs, with their accessibility and community-driven development, offer a unique blend of versatility and innovation, allowing for widespread experimentation and customization. ChatGPT, on the other hand, stands as a testament to targeted development and refinement, offering a user experience honed by extensive training and specific design goals. This article delves into the nuanced differences between these two approaches, exploring how each fulfills distinct roles in the realm of artificial intelligence and how they are shaping the future of human-computer interaction.
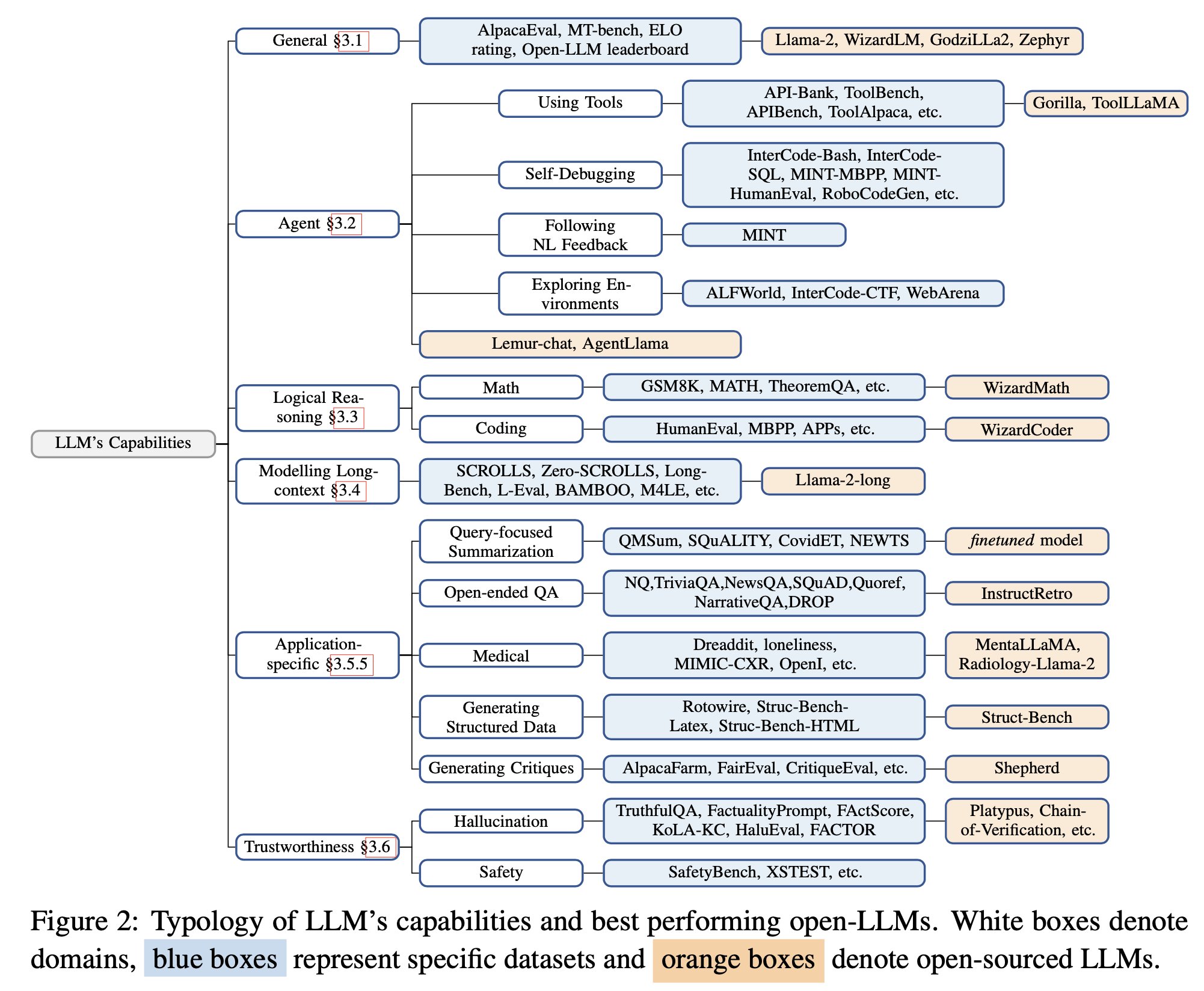
General Capabilities
Llama-2-chat-70B variant exhibits enhanced capabilities in general conversational tasks, surpassing the performance of GPT-3.5-turbo; UltraLlama matches GPT-3.5-turbo’s performance in its proposed benchmark.
Agent Capabilities (using tools, self-debugging, following natural language feedback, exploring environment): Lemur-70B-chat surpasses the performance of GPT-3.5-turbo when exploring the environment or following natural language feedback on coding tasks. AgentLlama-70B achieves comparable performance to GPT-3.5-turbo on unseen agent tasks. Gorilla outperforms GPT-4 on writing API calls.
Logical Reasoning Capabilities
Fine-tuned models (e.g., WizardCoder, WizardMath) and pre-training on higher quality data models (e.g., Lemur-70B-chat, Phi-1, Phi-1.5) show stronger performance than GPT-3.5-turbo.
Modeling Long-Context Capabilities: Llama-2-long-chat-70B outperforms GPT-3.5-turbo-16k on ZeroSCROLLS.
Application-specific Capabilities
- query-focused summarization (fine-tuning on training data is better)
- open-ended QA (InstructRetro shows improvement over GPT3)
- medical (MentalLlama-chat-13 and Radiology-Llama-2 outperform ChatGPT)
- generate structured responses (Struc-Bench outperforms ChatGPT)
- generate critiques (Shepherd is almost on-par with ChatGPT)
Trust-worthy AI
Hallucination: during finetuning – improving data quality during fine-tuning; during inference – specific decoding strategies, external knowledge augmentation (Chain-of-Knowledge, LLM-AUGMENTER, Knowledge Solver, CRITIC, Prametric Knowlege Guiding), and multi-agent dialogue.
Safety: GPT-3.5-turbo and GPT-4 models remain at the top for safety evaluations. This is largely attributed to Reinforcement Learning with Human Feedback (RLHF). RL from AI Feedback (RLAIF) could help reduce costs for RLHF.
Read related articles: