
PSU and Duke researchers, joined by collaborators from Google DeepMind and others, are reframing a perennial problem in Multi-Agent development: tracing the root cause of a Task Failure across long, intertwined logs. Their ICML 2025 spotlight work proposes Automated Attribution—a rigorous way to identify which agent failed and when—backed by a new open dataset and baseline methods. The goal is simple: turn opaque breakdowns into structured System Diagnostics that accelerate iteration.
| In a hurry? Here’s what matters: ⚡ | |
|---|---|
| • 🔎 New task: Automated failure attribution for LLM Multi-Agent workflows. | • 🧭 Benchmark: Who&When dataset with Who, When, Why labels. |
| • 📉 Challenge: Best single method hits ~53.5% on “Who” and ~14.2% on “When”. | • 🧰 Takeaway: Hybrid, reasoning-rich prompts and careful context control work best. |
Automated Failure Attribution in Multi-Agent Systems: Why Root Cause Analysis Matters
Multi-Agent pipelines promise collaboration, but in practice a flurry of agent messages can mask critical mistakes. Developers often confront long traces where several agents propose plans, critique each other, and call tools, yet the final output misses the target. Without structured Root Cause Analysis, the “what went wrong, who caused it, and when” remains buried in noise. PSU and Duke set out to formalize this missing link in AI Research by naming and scoping Automated Attribution for Multi-Agent Intelligent Systems.
Why formalization matters is straightforward. Debugging through manual “log archaeology” consumes hours, requires deep system expertise, and scales poorly as teams experiment with more agents, longer contexts, and tool-heavy workflows. A principled attribution layer transforms qualitative blame into quantifiable System Diagnostics. That shift affects everything from incident response to model governance, ultimately improving the reliability of Machine Learning systems deployed in real organizations.
Consider “NovaAI,” a fictional startup building an autonomous coding crew. A product agent gathers specs, a planner decomposes tasks, a coder writes patches, and a tester runs CI. A release fails because the coder misunderstood an API change hinted at earlier by the planner. Without attribution, the team patches surface symptoms—maybe turning up temperature or swapping the coder model—only to repeat the same failure pattern. With automated attribution, they get a concrete assignment: responsible agent, decisive step, and a brief explanation. Now the team can update prompts, rewire handoffs, or create a schema validator at that step.
Three reasons make this task uniquely tough. First, Task Failure can be systemic, with compounding small errors rather than a single catastrophic misstep. Second, the “right” answer may not be known during debugging, especially in open-ended problems. Third, lengthy context windows dilute signal; reasoning models must sift for causal hinges, not just correlate text fragments. That is why PSU and Duke’s framing emphasizes both the Who and the When, then complements them with a natural-language Why, tying together responsibility and mechanism.
Equally important is the impact on organizational processes. Operations teams gain consistent post-mortems; research teams compare agent variants on a shared yardstick; compliance teams audit failure patterns. Even product managers benefit, seeing which user scenarios routinely derail agents. A new vocabulary around agent failure improves cross-functional communication and prioritization.
- 🧩 Benefit: Turns vague incidents into concrete, fixable steps across the pipeline.
- 🕒 Efficiency: Cuts manual log review time by narrowing search to a single agent and step.
- 🧪 Experimentation: Enables A/B testing of agents based on causal error profiles, not just end metrics.
- 🛡️ Governance: Creates audit trails for safety, compliance, and post-incident reviews.
| Pain point 😵 | Impact on teams 🧠 | Attribution value ✅ |
|---|---|---|
| Long, noisy logs | Slow triage; guesswork | Pinpoint “Who” + “When” to focus fixes |
| Hidden causal chains | Mistargeted mitigations | “Why” explanations surface mechanisms |
| No shared vocabulary | Cross-team friction | Standard labels enable comparisons |
| Scaling agents/tools | Complexity spikes | System Diagnostics guardrails |
The headline insight is simple: when Automated Attribution becomes a default layer in Multi-Agent development, reliability stops being anecdotal and starts becoming measurable.

Inside the Who&When Benchmark: Data, Labels, and Design Choices from PSU and Duke
To ground the problem, PSU and Duke curated the Who&When dataset—failure logs spanning 127 Multi-Agent setups. Some traces are algorithmically generated for coverage; others are crafted by experts to preserve realism. Each log carries three fine-grained human annotations: Who (the responsible agent), When (the decisive step), and Why (a short explanation). This triad captures responsibility, timing, and mechanism in a machine-usable form.
Developers can browse the code on GitHub and fetch the dataset on Hugging Face, tying evaluation to reproducible pipelines. The design reflects common archetypes: planning-then-execution workflows; debate-and-select structures; and tool-augmented agents calling external APIs. Labels are consistent across these patterns, making it possible to compare attribution methods by topology, task domain, or log length.
Two evaluation regimes reveal how context shifts difficulty. In the “With Ground Truth” setting, the model doing attribution knows the correct final answer; it can cross-check intermediate steps against that answer. In the “Without Ground Truth” setting, it must reason from the process alone—a closer mirror of production incidents. Across both, the core outputs remain the same, which helps teams analyze gaps in reasoning rather than memorizing outcomes.
Beyond labels, the dataset includes metadata: agent roles, tool usage, and source systems. That metadata enables richer analysis, such as whether critic agents reduce missteps or whether tool calls correlate with brittle coordination. Because logs vary in length, the benchmark can quantify how performance degrades with context size—a known limitation of current reasoning models.
For teams adopting this data, a pragmatic pathway is to start with a narrow slice that mirrors their stack. If a team runs a planner-coder-tester trio, they can filter for similar topologies and build prompts using the Who&When annotation schema. Later, they can expand to debate-style or retrieval-heavy agents and see if failure patterns shift with architecture.
- 📚 Labels: Who (agent), When (step), Why (explanation).
- 🧭 Settings: With vs. Without Ground Truth for realistic variance.
- 🧩 Coverage: 127 systems spanning planning, debate, tool use.
- 🔓 Open: paper • code • dataset
| Dataset facet 🗂️ | Why it matters 🎯 | Team takeaway 🧰 |
|---|---|---|
| Who / When / Why labels | Structured RCA across agents | Standardize post-mortems |
| Topology diversity | Stress-tests methods | Match to your architecture |
| Context length variation | Measures scaling limits | Plan chunking/condensing |
| Open-source pipelines | Reproducible baselines | Adopt, then adapt |
For a quick orientation to Multi-Agent debugging patterns and attribution goals, the following search can help map relevant talks and demos across the community.
The dataset’s strength is its bridge between academic rigor and shop-floor utility: teams can lift the schema directly into their incident tooling and close the loop from “evaluation” to “improvement.”
Three Automated Attribution Strategies: All-at-Once, Step-by-Step, and Binary Search
With the benchmark in place, the team evaluated three strategies for Automated Attribution. Each reflects a different philosophy of reading and reasoning over logs. The All-at-Once method feeds the entire conversation and the user query to a model (e.g., GPT-4o), requesting the Who and When in one shot, plus an optional explanation. It is cheap in control flow but can miss fine-grained mistakes when contexts are long or when subtle contradictions hide inside role handoffs.
The Step-by-Step strategy mirrors human debugging: walk the log sequentially, assess each step, and stop when a decisive error appears. It tends to locate the specific step better, though it increases token cost and risks error accumulation in multi-hop judgments. Think of it as a meticulous reviewer that trades speed for precision.
A middle path is Binary Search. Split the log in half, ask the model which segment contains the mistake, then recurse. This narrows context quickly and avoids reading everything at once. It often balances cost and accuracy, though it can still be sensitive to ambiguous boundaries—e.g., when a misinterpretation begins earlier but manifests later.
Choosing among these depends on constraints. If teams optimize for dollar cost and engineer time, All-at-Once is a starting point, especially if prompts require explicit reasoning. If the priority is pinpointing the error step in safety-critical flows, Step-by-Step wins. Binary Search is attractive for large logs with clear semantic pivots (plan vs. execution). Hybrids—like All-at-Once to guess the agent and Step-by-Step to locate timing—often shine but add compute overhead.
- ⚙️ All-at-Once: simple control flow; watch context limits.
- 🧭 Step-by-Step: higher precision on “When”; monitor cumulative errors.
- ✂️ Binary Search: efficient narrowing; sensitive to fuzzy boundaries.
- 🧪 Hybrid: combine strengths; pay extra for tokens and time.
| Method 🔬 | Strength 💪 | Risk ⚠️ | Best use case 🚀 |
|---|---|---|---|
| All-at-Once | Low orchestration, quick | Misses subtle step errors | Short-to-medium logs |
| Step-by-Step | Step precision | Token and latency costs | Safety-critical audits |
| Binary Search | Scales to long logs | Ambiguous segmentation | Deep traces with pivots |
| Hybrid | Best of both | Compute-heavy | High-stakes incidents |
The practical heuristic is to instrument all three and route by trace size and risk: short traces to All-at-Once, long traces to Binary Search, and critical flows to Step-by-Step. This policy captures quick wins while reserving precision for where it matters.

Experimental Results and Real-World Use Cases: What Fails, Who Fails, and When
On Who&When, a single best-performing method reached about 53.5% accuracy on identifying the responsible agent and about 14.2% on pinpointing the exact error step—better than many baselines, yet far from production-ready nirvana. Notably, even strong reasoning models, including OpenAI o1 and DeepSeek R1, struggled with nuanced, multi-hop causality. That gap underscores the difference between solving tasks and explaining failures of agent collectives.
Two levers consistently helped: demanding explicit reasoning in prompts (e.g., chain-of-thought style rationales) and constraining context through chunking or guided navigation. However, performance dropped as logs grew longer, especially on the “When” label—evidence that temporal localization remains the hardest part. The Binary Search strategy mitigated context overload, while Step-by-Step improved temporal precision at higher cost.
In the field, consider “Orion Labs,” a hypothetical analytics firm building a Multi-Agent report generator. A planner drafts a data plan, a retriever fetches tables, a writer compiles a narrative, and a verifier checks consistency. A client notices that quarterly revenue is off by one region. Attribution reveals that the retriever used a deprecated schema after a tool call returned an outdated index. The decisive error step happened mid-trace, but the symptom surfaced only at the final verification. With automated diagnostics, Orion rewires the retriever to validate schema version at fetch time and to surface a hard error if versions mismatch.
Hybrid strategies also saw real use: first run All-at-Once to nominate the likely agent, then perform Step-by-Step focused only on that agent’s handoffs. The hybrid boosted accuracy in several cases, although token costs rose. Teams weighed the trade-off by routing high-value incidents to hybrids and routine regressions to cheaper methods.
- 📉 Reality check: Task attribution is harder than task execution for current models.
- 🧠 Explicit reasoning boosts both “Who” and “When.”
- 🧱 Context length remains a limiting factor; chunking helps.
- 🧯 Hybrids work best for critical incidents despite higher cost.
| Finding 🔎 | Evidence 📊 | Implication 🧭 |
|---|---|---|
| “Who” easier than “When” | 53.5% vs. 14.2% | Prioritize step localization research |
| Reasoning helps | Better results with explicit rationales | Mandate rationalized prompts |
| Context hurts | Longer logs degrade accuracy | Adopt Binary Search + summarization |
| Hybrids pay off | Improved combined accuracy | Route high-stakes to hybrid policy |
For additional perspectives on complex system failures and diagnostic workflows, this search will surface talks and case studies relevant to practitioners and researchers alike.
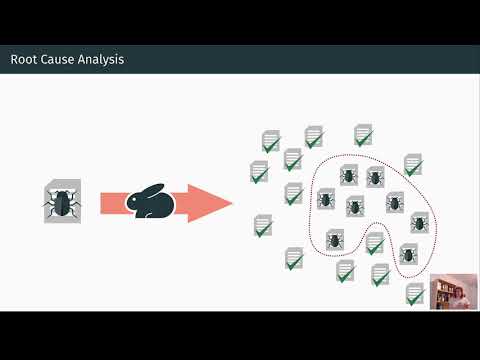
The upshot: attribution is now measurable. Even if scores are modest, the path to operational reliability becomes empirical and iterative.
Actionable Playbook for Developers: From System Diagnostics to Continuous Reliability
Turning research into practice starts with a pipeline mindset. Treat Automated Attribution as a standard stage in CI for Multi-Agent releases. Capture logs, normalize roles, and auto-run attribution after any failed run. Then convert results into tickets that specify the agent, step, and brief “why.” Over time, this produces a living catalogue of failure motifs—prompt misreads, stale tools, brittle handoffs—that engineering can systematically eliminate.
Consider a practical rollout. Begin with All-at-Once on short traces and add Binary Search above a context-length threshold. For customer-facing or safety-critical workflows, enable Step-by-Step or a hybrid. Bundle prompts that demand explicit reasoning, require model verdicts to cite log lines, and cache sub-analyses to control cost. Where possible, add lightweight validators at sensitive steps: schema version checks, unit tests for tool outputs, and guardrails that block ambiguous handoffs.
Prompt and data hygiene matter. Use the Who&When schema internally so post-mortems remain consistent across teams. Encourage agents to write short, machine-parsable rationales (e.g., JSON with “claim,” “evidence,” “confidence”). Log tool metadata—version, endpoint, latency—so attribution can distinguish agent logic errors from infrastructure issues. In multi-tenant environments, scrub personally identifiable data before exporting traces into shared benchmarks.
Finally, align stakeholders. Product prioritizes scenarios by user impact, research targets the hardest “When” localizations, and ops maintains dashboards showing incident rates by agent and step. Leadership gets trendlines: as attribution rates improve, incident MTTR falls. Over months, the organization shifts from reacting to failures to preventing them, supported by measurable diagnostics.
- 🧪 Start small: Pilot on one high-traffic workflow before scaling.
- 🪜 Tiered policy: Route by log length and business risk.
- 🧰 Tooling: Add validators and typed handoffs at fragile links.
- 📈 Metrics: Track attribution accuracy and MTTR together.
| Phase 🚀 | What to implement 🧩 | Outcome 🎯 |
|---|---|---|
| Instrumentation | Structured logs, role tags, tool metadata | Clean inputs for attribution |
| Attribution engine | All-at-Once + Binary Search + Step-by-Step | Coverage across trace shapes |
| Guardrails | Schema checks, tool unit tests, typed handoffs | Fewer recurrent failures |
| Operations | Auto-ticketing with Who/When/Why | Faster, focused fixes |
| Learning loop | Trend dashboards, A/B agent swaps | Continuous reliability gains |
Ground truth isn’t always available in production, so prefer methods robust to uncertainty and invest in synthetic evaluations that mirror your risk profile. Attribution is not just a research milestone; it is a practical lever to make Intelligent Systems dependable at scale.
What makes automated failure attribution different from standard debugging?
It formalizes responsibility and timing—identifying the exact agent (Who) and decisive step (When)—and couples them with a short explanation (Why). This turns free-form log reviews into structured System Diagnostics suitable for metrics, audits, and automation.
How do PSU and Duke evaluate methods fairly?
They use the Who&When benchmark with two regimes: With Ground Truth (the model knows the correct answer) and Without Ground Truth (the model relies solely on the process). This isolates reasoning skill from answer lookup and keeps comparisons consistent.
Why do strong models like OpenAI o1 and DeepSeek R1 still struggle?
Attribution demands multi-hop causal reasoning and temporal localization across long contexts. These demands are harder than producing a final answer, especially when errors compound or emerge indirectly through tool use.
When should a team prefer Binary Search over Step-by-Step?
Use Binary Search for long traces where the error likely sits behind major semantic boundaries (planning vs. execution). Choose Step-by-Step when precision on the exact step matters more than cost or latency.
Where can developers start with the open resources?
Read the ICML 2025 spotlight paper, clone the GitHub repo for pipelines, and pull the Who&When dataset from Hugging Face. Begin by mirroring your own agent topology and adopt the Who/When/Why schema in internal post-mortems.
Jordan has a knack for turning dense whitepapers into compelling stories. Whether he’s testing a new OpenAI release or interviewing industry insiders, his energy jumps off the page—and makes complex tech feel fresh and relevant.
Comments are closed