

ChatGPT-Anfragen erscheinen in Google Analytics Workflows: Wie peinliche Eingaben in der Search Console landeten
Was als ein typischer Analytics-Tag galt, wurde seltsam, als KI-Konversationen an Orten auftauchten, an denen sie niemals sein sollten: Abfrageprotokolle in Google Analytics-verbundenen Search Console-Workflows. Entwickler, die Leistungsberichte überprüften, entdeckten extrem lange Zeichenketten – manchmal über 300 Zeichen – die rohen ChatGPT-Eingaben über Beziehungen, Konflikte am Arbeitsplatz und sogar Entwürfe für RTO-Richtlinien ähnelten. Dabei handelte es sich nicht um Ausschnitte aus Blogbeiträgen; es sah vielmehr so aus, als wären es direkte Nutzereingaben, die irgendwie in Googles Indexpfade gelangt und dann in Google Search Console (GSC)-Berichten auf SEO-Dashboards und, bei einigen Teams, in exportierte Google Analytics-verbundene Reporting-Stacks aufgetaucht waren.
Analysten bemerkten ein merkwürdiges Präfix an vielen dieser Zeichenketten: eine tokenisierte Spur, die auf eine OpenAI-URL hinwies, welche Suchmaschinen in Begriffe wie „openai + index + chatgpt“ aufteilten. Jede Seite, die für diese Schlüsselwörter gerankt wurde, könnte die „ausgespähten“ Eingaben in der GSC sehen. Das Ergebnis war surreal: Ein SEO-Tool, das zur Überwachung der organischen Leistung dient, wurde unbeabsichtigt zu einem Spionagefenster für vermeintlich private Datenleck-Artefakte. Das Beunruhigendste? Viele Eingaben waren eindeutig sensibel. Es gab Geständnisse, Namen, geschäftliche Details – Inhalte, die niemals das Chatfenster verlassen sollten.
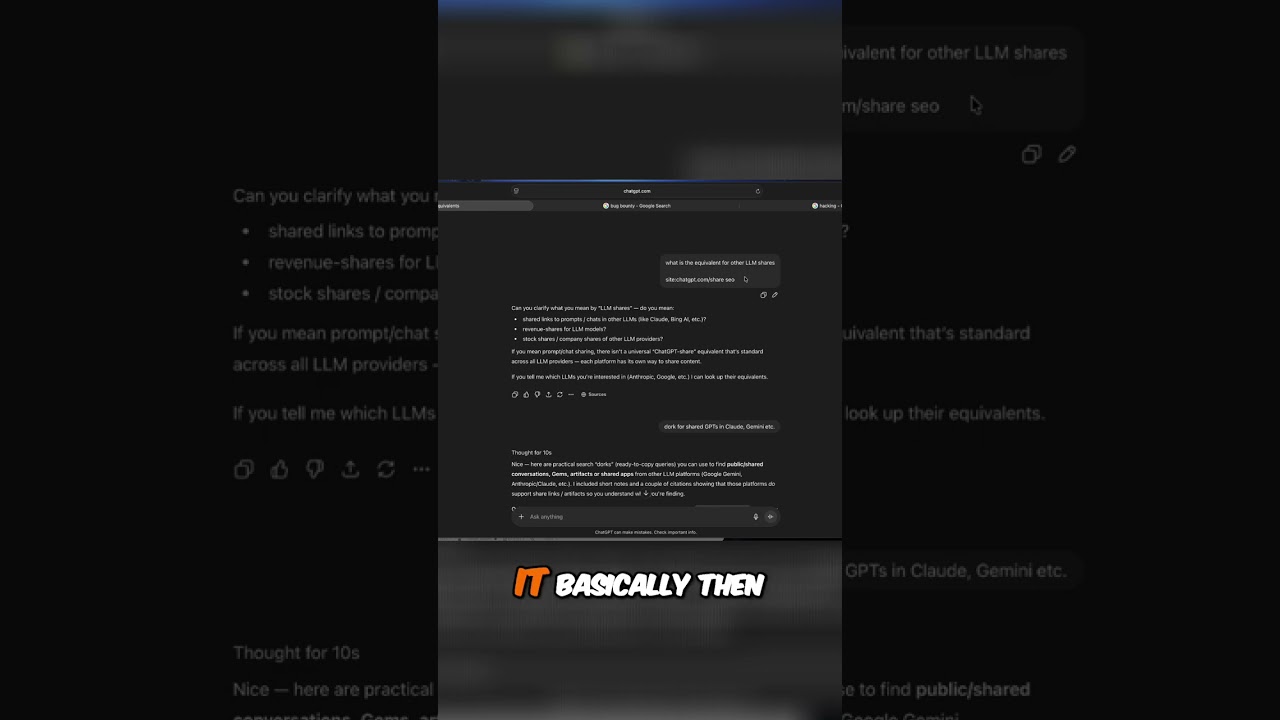
Unabhängige Ermittler – ein Analytics-Berater und ein erfahrener Web-Optimierer – testeten das Muster und vermuteten, dass eine fehlerhafte Chat-Oberfläche die Seiten-URL zur Eingabe hinzufügte und über einen Hints-Parameter Websuchen aggressiver auslöste. Wenn ChatGPT entschied, dass eine Suche notwendig war, konnte diese Eingabe an die öffentliche Suche weitergeleitet werden, und Spuren könnten im GSC widerhallen, wo Domains für das tokenisierte Präfix gerankt wurden. OpenAI gab später eine Routing-Störung zu, die eine kleine Anzahl von Anfragen betraf, und erklärte, dass das Problem behoben sei. Doch die fehlende Frage bleibt: Wie viele Eingaben waren betroffen und über welchen Zeitraum?
Teams, die GSC-Daten mit Google Analytics integrieren, spürten die Auswirkungen auf die unangenehmste Weise – durch Dashboards und BI-Tools, die plötzlich abseitige, sehr persönliche Zeichenketten widerspiegelten. Während frühere Vorfälle Nutzer einbezogen, die Chats explizit teilten oder indizierten, traf dieses Muster Seitenbetreiber völlig unvorbereitet, die nie auf einen Share-Button klickten. Für datenschutzorientierte Teams unterstreicht die Episode eine zerbrechliche Wahrheit: scheinbar private Eingaben können sehr öffentliche Wege nehmen, wenn die Browser-Logik eines Produkts Fehlfunktionen zeigt.
Was Analysten als Erstes auffiel
Erste Warnsignale beinhalteten Eindrucksspitzen bei nicht verwandten Keywords, große Diskrepanzen zwischen Impressionen und Klicks („Krokodilmaul“-Muster) und merkwürdige Präfixe, die nicht zur Seiten-Taxonomie passten. Effektiv hinterließen Chat-Eingaben – die eigentlich flüchtig sein sollten – dauerhafte Spuren in der SEO-Telemetrie und schlichen sich dann in Digitale Forensik-Gespräche innerhalb von Sicherheits- und Marketingteams.
- 🔎 Seltsame, lange Suchanfragen, die wie komplette Nachrichten an ChatGPT wirken
- 📈 Eindrucksspitzen mit verschwindend niedrigem CTR bei irrelevanten Begriffen
- 🧩 Ein konsistentes Präfix, das tokenisierte OpenAI-Seitenelemente nahelegt
- 🛡️ Datenschutzwarnungen, ausgelöst von Cybersecurity oder Compliance-Mitarbeitern
- 🧭 Widersprüchliche Zuordnung in Google Analytics gegenüber GSC-Exporten
| Zeitleiste ⏱️ | Symptom 🧪 | Beobachteter Ort 🔭 | Risikostufe ⚠️ |
|---|---|---|---|
| Entdeckungsphase | Eingaben erscheinen als Suchanfragen | GSC, verbunden mit Google Analytics | Hoch 😬 |
| Untersuchung | Tokenisiertes Präfix-Muster | Top-Queries-Bericht | Mittel 😕 |
| Antwort des Anbieters | Routing-Störung anerkannt | Offizielle Erklärungen | Variabel 🤔 |
| Behebung | Filterung und Warnmeldungen | Analytics-Pipelines | Niedriger 🙂 |
Für Leser, die Best Practices vergleichen, bieten praktische Guides wie Playground-Tipps und ein offener Blick auf Bedauern nach dem Teilen von Reiseplänen mit einem Bot fundierte Schritte für sicheres Prompten. Ein umfassenderer Guide für ungefilterte KI-Chatbots ergänzt den Kontext zu Grenzen bei Experimenten mit öffentlichen Share-Links.
Die wichtigste Lektion dieses Vorfalls ist einfach: Wenn ein Modell browsed, kann der Prompt-Text reisen; ohne Schutzmaßnahmen kann ein Teil davon als Boomerang in öffentliche Telemetrie zurückkehren.

Nicht dasselbe wie „Share to the Web“: Warum diese Offenlegung seltsamer ist – und warum sie wichtig ist
Frühere Kontroversen drehten sich um eine explizite „Teilen“- oder „entdeckbare“ Einstellung, die ChatGPT-Threads zu öffentlichen Seiten machte, die von Suchmaschinen indiziert wurden. Das war ein Opt-in-Verhalten – selbst wenn die Benutzeroberfläche manche Nutzer verwirrte. Diesmal sieht das Problem strukturell anders aus. Lange Suchanfragen, die echten Eingaben ähneln, tauchten in Google Search Console über Keyword-Tokenisierung und Browsing-Verhalten auf – nicht über öffentlich veröffentlichte Chat-Seiten. Kein „Veröffentlichen“-Button. Kein soziales Teilen. Nur roher Prompt-Text, der in einem SEO-Tool erscheint, das verfolgt, wie Suchende Inhalte finden.
Datenschutzexperten nennen dies die Albtraum-Überlappung: Ein Produkt, das im Web browsed, trifft auf eine Suchpipeline, die alles als potenzielles Signal interpretiert. Wenn das Routing falsch konfiguriert ist, berührt Prompt-Text nicht nur Drittanbieter-Dienste, sondern hinterlässt Spuren, die nachgelagerte Analytics-Tools nicht ignorieren können. Selbst nachdem OpenAI erklärte, die Routing-Störung sei behoben, stellten Analysten die naheliegenden Nachfragen: Wurden wirklich alle Endpunkte abgedeckt? Wurden Prompts von chatgpt.com und mobilen Clients ähnlich weitergeleitet? Könnten Drittanbieter-Scraper dieselben Datenströme kopiert haben?
Die Medienberichterstattung 2025 spiegelt diese Spaltung wider: Einige Medien betonen schnelle Behebung und beschäftigen sich nicht mehr weiter damit; andere heben das breitere systemische Risiko hervor. Ob man sich eher für TechCrunch-artige Produktverantwortlichkeit oder Wired-ähnliche kulturelle Kritik entscheidet – die zentrale Frage bleibt unverändert: Wie sollen browsing-fähige Assistenten mit Prompt-Text an der Netzwerkschnittstelle umgehen, damit keine Analytics-Konsole jemals zum Spiegel privater Gedanken wird?
Wesentliche Unterschiede, die Nutzer verstehen sollten
In der Praxis müssen Unternehmen zwischen freiwilliger Veröffentlichung und unbeabsichtigter Offenlegung über Telemetrie unterscheiden. Sicherheitsteams müssen auch wissen, wo Prompts auftauchen können – Browser-Caches, DNS-Protokolle, Suchschnittstellen von Anbietern – und wie Kontrollen wie Data Loss Prevention bei model-browsing Workflows greifen.
- 🧭 Opt-in-Sharing erzeugt indexierte Seiten; dieser Vorfall leitete Prompts in Suchpfade weiter
- 🔐 Online-Privatsphäre-Erwartungen unterscheiden sich grundlegend zwischen „Posten im Web“ und „Modell-Browsing“
- 🧰 Korrekturen müssen Netzwerkrouting adressieren, nicht nur die Sichtbarkeit von geteilten Links
- 🔍 Digitale Forensik sollte prüfen, wo Prompt-Text in Protokollen verbleiben kann
- 📚 Mitarbeiterschulungen müssen browsing-bezogene Risiken abdecken, nicht nur Share-Link-Hygiene
| Szenario 🧩 | Nutzeraktion 🖱️ | Offenlegungsvektor 🌐 | Abhilfemaßnahme ✅ |
|---|---|---|---|
| Geteilte Chat-Seite | Explizites „Teilen“ | Indizierte öffentliche URL | Deaktivieren + Deindizieren 😌 |
| Browsing-induzierter Prompt-Echoeffekt | Kein Teilen | Such-Routing + Protokolle | Netzwerkfix + Protokollhygiene 🧽 |
| Drittanbieter-Scraper | Keine | Kopien von freigelegten Spuren | Entfernungsanfragen + Blocklisten 🛑 |
Organisationen, die model-enable Workflows bewerten, können operative Playbooks wie Unternehmens-Insights mit ChatGPT, taktische Fine-Tuning-Techniken für 2025 und den praktischen Leitfaden zu KI-Browsern und Cybersicherheit heranziehen. Jede Ressource bekräftigt ein einfaches Mantra: Datenschutz ist eine Architekturentscheidung, kein Schalter in den Einstellungen.
Während der Vorfall sich legt, ist der nützlichste Erkenntnisgewinn eine präzise Sprache: Es war kein Nutzerpublikationsfehler – es war eine Browsing- und Routing-Offenlegung, die aus Sicht der Analytics-Telemetrie wie ein Datenleck wirkte.

Geschäftliche Folgen: SEO-Rauschen, Compliance-Druck und das „Krokodilmaul“-Problem
Unternehmen, die GSC mit Google Analytics synchronisieren, spürten sofort störende Einflüsse auf KPIs. Die Impressionen auf irrelevanten Long-Tail-Suchen stiegen stark an – doch Klicks blieben aus. Diese wachsende Lücke, unter SEOs als „Krokodilmaul“ bekannt, erschwerte Berichte für Wochen-Reviews und OKRs. Marketing-Teams mussten Erklärungen an Führungskräfte liefern, die klare Narrative erwarteten und keine Vorbehalte über Eingabe-Artefakte.
Über kosmetische Aspekte hinaus erkannten Compliance-Beauftragte potenzielle Online-Privacy</strong-Einflüsse. Wenn Prompt-Text persönliche Identifikatoren enthält und dieser Text in Drittanbietersysteme verarbeitet wird, müssen Datenschutzteams prüfen, ob eine solche Verarbeitung mit Einwilligung und Minimierungsprinzipien konform ist. Die Risikomatrix erweitert sich: Geheimhaltungsvereinbarungen, Kundendaten und Produktdetails vor der Veröffentlichung sind alles Inhalte, die Mitarbeiter manchmal mit ChatGPT entwerfen. Das Erscheinen ähnlicher Inhalte in SEO-Tools – wenn auch als nicht anklickbare Spuren – wirft ernste Fragen auf.
Betrachten wir einen fiktiven Bekleidungshändler, Northbridge Outfitters. Deren Content-Team nutzt ein Modell, um saisonale Texte zu verfeinern. An einem Nachmittag sieht der SEO-Analyst Abfragen in GSC, die verdächtig nach Brainstorming-Prompts für eine noch nicht gestartete Kooperation aussehen. Die Marke hat keine Landing-Pages geleakt. Doch diese Eingaben existieren jetzt in einem System, das mit Agenturen und BI-Anbietern geteilt wird. Das Rechtsteam greift ein, und die Startpläne werden verzögert, während Protokolle überprüft und Exportrichtlinien verschärft werden.
Sofortige Maßnahmen der Teams
Um die Signalqualität zurückzugewinnen, wurden praktische Schritte ergriffen: Filter, Regex-Regeln und Alerts. Sie dokumentierten das tokenisierte Präfix-Muster, schlossen es aus Dashboards aus und legten interne Tickets an, um zu überprüfen, welche GSC-Daten in Google Analytics fließen und wohin.
- 🧹 Anwenden von View-Level-Filtern zur Unterdrückung bekannter promptartiger Zeichenketten
- 🧪 Durchführung eines Diffs zu Impressionen vor/nach dem Vorfall für sensible Begriffe
- 🔐 Pause der GSC-Daten-Exporte zu geteilten BI-Systemen bis zur Bereinigung
- 📝 Aktualisierung von Analytics-Runbooks, um KI-Konversations-Überlauf-Szenarien einzubeziehen
- 🚨 Erstellen eines Vorfall-Labels für rückwirkende Berichterstattung in Management-Präsentationen
| Stakeholder 👥 | Haupt-Risiko 🧨 | Aktionsplan 🗂️ | Ergebnis 🎯 |
|---|---|---|---|
| SEO/Analytics | Verzerrte KPIs | Filter + Anmerkungen | Sauberere Dashboards 😊 |
| Recht/Datenschutz | Verarbeitung personenbezogener Daten | DPIA-Überprüfung + Anbieter-QA | Geringere Exposition 🛡️ |
| Sicherheit | Unbeabsichtigter Datenfluss | Netzwerkrichtlinien-Prüfungen | Gesicherte Routen 🔒 |
| Kommunikation | Reputationsrisiko | Holding-Statement | Vertrauen der Stakeholder 🤝 |
Zum strategischen Kontext bezüglich Modellentscheidungen und Anbieterzusagen vergleichen Leser oft eine ChatGPT-Review 2025, ChatGPT vs. Perplexity AI 2025 und prüfen Enterprise-Playbooks wie Azure ChatGPT Projekt-Effizienz. Das Verständnis von Preismodellen und SLA-Formulierungen ist ebenfalls wichtig; ein Überblick zu ChatGPT-Preisen 2025 hilft Einkaufsabteilungen, Budget und Risikokontrollen abzustimmen.
Die operative Lektion ist klar: Browsing-fähige Assistenten sollten wie jeder andere Drittanbieterdatenprozessor behandelt werden – mit Kontrollen, Verträgen und konsequenter Bewertung des Restrisikos.
Ein Leitfaden für digitale Forensik: Überprüfung, Abgrenzung und Eindämmung von Prompt-Telemetrie
Wenn Analytics-Teams menschenähnliche Eingaben in Abfrageprotokollen entdecken, setzt Digitale Forensik ein. Der erste Schritt ist die Verifikation: Bestätigen, dass die Zeichenketten nicht aus benutzergenerierten Site-Suchen oder internen Testdaten stammen. Danach folgen die Analysten den Spuren – tokenisierte Präfixe, Zeitstempelgruppen und Eindruckspfade über Regionen hinweg. Das Ziel ist es, den Umfang abzustecken, ohne Beweise zu verunreinigen oder die Nutzerprivatsphäre weiter zu verletzen.
Ein simples Vorgehen funktioniert gut. Erhalte einen sauberen Export der GSC-Anfragen für den Zeitraum, hashe den Datensatz und speichere ihn in einem sicheren Evidenzspeicher. Erstelle ein Regex-Signaturmuster für das verdächtige Präfix und markiere alle Treffer. Prüfe Änderungsprotokolle auf neue Anbieter-Updates, Browsing-Features oder A/B-Tests. Schließlich führe Interviews mit Verantwortlichen, um zu erfahren, wer die Anomalie zuerst bemerkte und ob Screenshots oder Alarm-E-Mails vorliegen. Extern sollte die Berichterstattung von Wired und TechCrunch beobachtet werden, um autoritative Updates und Minderungsempfehlungen zu erhalten.
Wiederholbare Untersuchungsschritte
Teams passen oft den folgenden Plan an, um von Verwirrung zur Klarheit zu gelangen, ohne sensible Inhalte übermäßig zu erfassen. Der Fokus liegt auf Metadaten, nicht auf Inhalten, und auf der Minimierung von Replikationen.
- 🧭 Priorisieren: Exporte von GSC zu geteilten Google Analytics-Views einfrieren
- 🧪 Signatur: Regex entwerfen, um tokenisierte Präfix-Varianten zu isolieren
- 🗂️ Beweise: Hashen und archivieren eines minimalen Datensatzes gemäß Aufbewahrungsrichtlinie
- 🔍 Korrelation: Eindrucksspitzen auf Zeitraum der Anbieter-Vorfallfenster abgleichen
- 📣 Benachrichtigung: Datenschutz-Hinweise vorbereiten, falls persönliche Daten in der Telemetrie auftauchen
| Artefakt 🔎 | Speicherort 📂 | Relevanz 🎯 | Verarbeitungsregel 🧱 |
|---|---|---|---|
| Prompt-artige Suchanfragen | GSC-Exporte | Primärer Indikator | Schwärzen + Minimieren ✂️ |
| Präfix-Token | Suchzeichenketten | Verbindung zum Routing | Regex + Isolierung 🧪 |
| Impressionsdifferenzen | Zeitreihenberichte | Abgrenzung der Offenlegung | Annotations in Dashboards 📝 |
| Anbietererklärungen | Vertrauenszentren | Status der Eindämmung | Archivieren + Zitieren 📌 |
Für Einsatzbereitschaft im Team eignen sich praxisnahe Einführungen wie ChatGPT-Konversationen teilen und ein Reality-Check zu Beschränkungen und Strategien für 2025. Für Engineering-Leads klären Vergleiche von GPT-4-Transformation 2025 und der Fahrplan zu der GPT-5-Trainingsphase, wie Browsing, Grounding und Retrieval-Richtlinien sich entwickeln.
Eindämmung bedeutet nicht, die Anomalie zu verstecken; es geht darum, zu verhindern, dass sie zur neuen Normalität im System wird.
Governance nach der Störung: Anbieterfragen, Schutzmaßnahmen und sichereres Prompten
Risikomanagement entwickelt sich am schnellsten direkt nach einem Vorfall. Unternehmen prüfen nun ihre OpenAI-Integrationen und allgemein das Verhalten von browsing-fähigen Assistenten genauer. Die unverzichtbare Checkliste beginnt mit vertraglichen Zusagen und vertieft sich in technische Kontrollen und UX-Schutzmechanismen. Wenn ein Modell browsed, was genau wird übertragen? In welcher Granularität? Auf welcher rechtlichen Grundlage? Kann eine Datenschutzbeauftragte eine „kein externes Browsing“-Richtlinie für bestimmte Projekte durchsetzen?
Risikoteams passen auch die interne Anleitung an. Prompts können NDAs, personenbezogene Daten, Gesundheitsangaben und Finanzpläne enthalten. Wenn diese Eingaben durchs Browsing mehrere Rechtsgebiete und Dienste passieren, reduzieren Unternehmen dieses Risiko auf zwei Wegen: strengere Inhaltsrichtlinien (keine persönlichen Daten, keine Kundennamen) und bessere UX-Hinweise (klare Icons, Banner und Protokolle, wenn das Modell online geht).
Wesentliche Governance-Schritte
Von der Beschaffung bis zum operativen Betrieb verhindern die folgenden Maßnahmen das Wandern von Prompts in die Analytics-Telemetrie und unterstützen die Wiederherstellung des Vertrauens bei Stakeholdern.
- 🧾 Aktualisieren von Datenverarbeitungsverträgen zu Browsing, Caching und Drittanbieter-Such-Routing
- 🧱 Durchsetzen von Allow/Deny-Listen für Modell-Browsing am Netzwerk-Rand
- 🧑🏫 Schulung der Mitarbeitenden zu Prompt-Hygiene mit realen Beispielen von Datenleck-Folgen
- 🧰 Instrumentieren von Dashboards mit Markierungen, wenn ChatGPT online geht
- 🧭 Einführung von Datenschutz-voreingestellten Einstellungen für sensible Rollen und Projekte
| Kontrolle 🔐 | Verantwortlicher 👤 | Was es verhindert 🛑 | Erfolgsindikator ✅ |
|---|---|---|---|
| Browsing-Richtlinie | Sicherheit | Weiterleitung von Prompts an Suchdienste | Keine promptartigen GSC-Abfragen 😊 |
| UX-Aufklärung | Produkt | Unbewusste Online-Aktivitäten | Höheres Mitarbeiterbewusstsein 📈 |
| DLP-Regeln | IT | PII in Prompts | Blockierte sensible Begriffe 🛡️ |
| Protokoll-Minimierung | Datenschutz | Übermäßige Speicherung | Kürzere Aufbewahrungszeiten ⏳ |
Praktische Teams können Ressourcen wie ChatGPT-Plugins Power 2025 für Integrationshygiene erkunden, eine KI-FAQ für 2025 zum Vokabularabgleich mit Richtlinien und Hinweise zu psychischen Gesundheitsvorteilen von ChatGPT – wichtige Kontexte bei sensiblen Eingaben. Für Build-vs-Buy-Entscheidungen gilt: Governance ist nicht nur eine Modellfrage; sie betrifft die gesamte Pipeline vom Browser bis zum Dashboard.
Ein Governance-Programm, das Browsing als privilegierte Fähigkeit und nicht als Standard behandelt, wird gut altern, da sich Assistentenprodukte weiterentwickeln.
Was dies über KI-Browsing, Suchökosysteme und den weiteren Weg signalisiert
Rückblickend zeigt die Episode eine grundsätzliche Spannung zwischen Modell-Browsing und Websuche. Assistenten profitieren, wenn sie Sachen nachschlagen können, doch die Telemetriesysteme des Webs sind nicht für das Vermischen privater Prompts mit öffentlicher Entdeckung ausgelegt. Wenn eine einzelne Routing-Störung die offensten menschlichen Nachrichten in SEO-Artefakte verwandelt, muss die Produktarchitektur sich entwickeln – sowohl in den OpenAI-Stacks als auch in Suchökosystemen, die jede Zeichenkette als Ranking-Signal interpretieren.
Erwarten Sie deutlichere Browser-Anzeigen, wenn ein Modell online geht, und klarere Abgrenzungen zwischen Prompt-Text und den Suchbegriffen, die zum Abruf von Seiten verwendet werden. Auf Suchmaschinenseite benötigen Engines und Tools womöglich strengere Bereinigungsregeln für verdächtig lange, gesprächige Strings, die keine echten Suchintentionen abbilden. Wenn neue Schutzvorrichtungen entstehen, sollte der nächste Routing-Fehler mit weniger Telemetrie-Lecks und weniger peinlichen Überraschungen in Google Analytics-Berichten enden.
Praktische Wege für Teams in 2025
Unternehmen können zugleich ihren Umgang mit browsing-fähigen Assistenten härten. Behandeln Sie sie wie integrierte Cloud-Dienste, nicht nur als Chatfenster. Validieren Sie, was Ihr Netzwerk verlässt, wie es protokolliert wird und wie schnell es gelöscht werden kann. Und – entscheidend – schulen Sie Mitarbeitende darin, was nicht in einen Prompt eingefügt werden darf.
- 🧭 Führen Sie ein Register der Modellnutzung, in dem festgehalten wird, wo Browsing erlaubt ist
- 🧯 Fügen Sie Not-Aus-Schalter hinzu, um Browsing bei Vorfällen zu deaktivieren
- 🧪 Führen Sie Red-Team-Übungen durch, die Telekommetrielecks von Prompts simulieren
- 🧠 Bieten Sie im Chat-UI zeitnahe Anleitungen zu sensiblen Inhalten
- 🔁 Überprüfen Sie Anbieterfahrpläne vierteljährlich auf Änderungen im Routing-Verhalten
| Priorität 🚀 | Aktion 🔧 | Werkzeuge 🧰 | Nutzen 🌟 |
|---|---|---|---|
| Hoch | Netzwerk-Ausgangskontrollen | Proxy + CASB | Entkopplung von Browsing-Daten 🔒 |
| Mittel | Prompt-Hygiene-Training | LMS-Module | Reduziertes Leckrisiko 📉 |
| Mittel | Erkennung von Telemetrie-Anomalien | SIEM-Regeln | Schnellere Vorfallserkennung ⏱️ |
| Explorativ | Sandboxed Browsing | Isolierte VPC | Reduziertes Schadensausmaß 🛡️ |
Zur Verfeinerung des Stacks sollten Teams Produkt und Richtlinie mit technischen Ressourcen und vergleichenden Lesungen verknüpfen – etwa KI-Browser und Cybersicherheit sowie Übersichtsleitfäden, die Strategie festigen, selbst wenn sich Modelle weiterentwickeln. Die sichersten Systeme gehen davon aus, dass mitunter die seltsamsten Strings an die öffentlichsten Orte gelangen – und planen entsprechend.
Für Entwickler, die neue Workflows testen, bewahren eine pragmatische Mischung aus Plattform-Reviews, Architektur-Schutzmaßnahmen und Produkt-Telemetrie-Disziplin den Nutzen von Browsing, ohne dass die peinlichen Chat-Protokolle erneut online auftauchen.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Warum erschienen ChatGPT-ähnliche Prompts in Search Console und Analytics-Workflows?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Eine Routing-Störung im Zusammenhang mit Browsing-Verhalten führte dazu, dass ungewöhnlich lange, gesprächsartige Zeichenketten – die Nutzereingaben ähneln – über Suchpfade verarbeitet wurden. Da viele Organisationen Google Search Console-Daten in Berichtsstacks zusammen mit Google Analytics einbinden, tauchten diese Zeichenketten in Dashboards und Exporten auf.”}},{“@type”:”Question”,”name”:”Worin unterscheidet sich das von öffentlich geteilten Chat-Links?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Geteilte Links erzeugen per Design indexierbare Seiten. Diese Offenlegung beruhte nicht darauf, dass Nutzer einen Teilen-Button klickten. Stattdessen wurde promptartiger Text so geroutet, dass Spuren in der Suchtelemetrie verblieben, was ein grundlegend anderes Datenschutz- und Governance-Problem darstellt.”}},{“@type”:”Question”,”name”:”Was sollte ein Unternehmen unmittelbar nach Entdeckung von Prompt-Artefakten tun?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Exporte von GSC zu BI anhalten, bekannte Präfixe filtern, minimale Beweise hashen und archivieren sowie Datenschutz- und Sicherheitsteams informieren. Dashboards für den betroffenen Zeitraum annotieren und Browsing-Richtlinien für alle verwendeten Assistenztools überprüfen.”}},{“@type”:”Question”,”name”:”Kann man ChatGPT weiterhin für sensible Arbeit vertrauen?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Ja – wenn Organisationen Governance anwenden. Browsing bei Bedarf deaktivieren, DLP für Prompts implementieren und Mitarbeitende in Prompt-Hygiene schulen. Anbieterdokumentationen prüfen und für sensible Workflows Sandbox-Umgebungen in Betracht ziehen.”}},{“@type”:”Question”,”name”:”Wo können Praktiker sichereres Prompten und Deployment-Taktiken lernen?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Praktische Guides wie Playground Best Practices, policy-fokussierte FAQs und Anbieter-Vergleichsartikel helfen Teams, sicherere Muster zu entwickeln. Suchen Sie nach Ressourcen, die Browsing-Verhalten, Datenaufbewahrung und Datenschutz-nach-Design-Kontrollen abdecken.”}}]}Warum erschienen ChatGPT-ähnliche Prompts in Search Console und Analytics-Workflows?
Eine Routing-Störung im Zusammenhang mit Browsing-Verhalten führte dazu, dass ungewöhnlich lange, gesprächsartige Zeichenketten—die Nutzereingaben ähneln—über Suchpfade verarbeitet wurden. Da viele Organisationen Google Search Console-Daten in Berichtsstacks zusammen mit Google Analytics einbinden, tauchten diese Zeichenketten in Dashboards und Exporten auf.
Worin unterscheidet sich das von öffentlich geteilten Chat-Links?
Geteilte Links erzeugen per Design indexierbare Seiten. Diese Offenlegung beruhte nicht darauf, dass Nutzer einen Teilen-Button klickten. Stattdessen wurde promptartiger Text so geroutet, dass Spuren in der Suchtelemetrie verblieben, was ein grundlegend anderes Datenschutz- und Governance-Problem darstellt.
Was sollte ein Unternehmen unmittelbar nach Entdeckung von Prompt-Artefakten tun?
Exporte von GSC zu BI anhalten, bekannte Präfixe filtern, minimale Beweise hashen und archivieren sowie Datenschutz- und Sicherheitsteams informieren. Dashboards für den betroffenen Zeitraum annotieren und Browsing-Richtlinien für alle verwendeten Assistenztools überprüfen.
Kann man ChatGPT weiterhin für sensible Arbeit vertrauen?
Ja—wenn Organisationen Governance anwenden. Browsing bei Bedarf deaktivieren, DLP für Prompts implementieren und Mitarbeitende in Prompt-Hygiene schulen. Anbieterdokumentationen prüfen und für sensible Workflows Sandbox-Umgebungen in Betracht ziehen.
Wo können Praktiker sichereres Prompten und Deployment-Taktiken lernen?
Praktische Guides wie Playground Best Practices, policy-fokussierte FAQs und Anbieter-Vergleichsartikel helfen Teams, sicherere Muster zu entwickeln. Suchen Sie nach Ressourcen, die Browsing-Verhalten, Datenaufbewahrung und Datenschutz-nach-Design-Kontrollen abdecken.



Verstehen der Gall-Peters-Kartenprojektion: Vorteile und Kontroversen im Jahr 2025
Die Realität hinter der Karte: Warum die Gall-Peters-Projektion immer noch wichtig ist Jedes Mal, wenn Sie eine standardmäßige Weltkarte betrachten,...


wie man im Jahr 2025 einen sicheren Building-Link-Anmeldevorgang erstellt
Entwicklung eines robusten Authentifizierungsrahmens im Zeitalter der KI Die Benutzeranmeldung definiert den Perimeter moderner digitaler Infrastrukturen. Im Jahr 2026 geht...


Top KI-Tools für kleine Unternehmen: Unverzichtbare Auswahl für 2025
Die KI-Landschaft navigieren: Unverzichtbare Werkzeuge für das Wachstum kleiner Unternehmen im Jahr 2025 Der digitale Horizont hat sich drastisch verschoben....


Die Wahl zwischen OpenAIs ChatGPT und Falcon: Das beste KI-Modell für 2025
Die Landschaft der künstlichen Intelligenz hat sich dramatisch verändert, während wir uns durch das Jahr 2026 bewegen. Die Wahl geht...


entdecke die faszinierendsten Muschelnamen und ihre Bedeutungen
Entschlüsselung der verborgenen Daten mariner Architekturen Der Ozean fungiert als ein riesiges, dezentralisiertes Archiv biologischer Geschichte. Innerhalb dieses Raums sind...


Funko pop Nachrichten: Neueste Veröffentlichungen und exklusive Drops im Jahr 2025
Wichtige Funko Pop Neuigkeiten 2025 und die andauernde Wirkung in 2026 Die Landschaft des Sammelns hat sich in den letzten...


wer ist hans walters? die geschichte hinter dem namen im jahr 2025 enthüllt
Das Rätsel um Hans Walters: Analyse des digitalen Fußabdrucks im Jahr 2026 Im weiten Informationsraum von heute präsentieren nur wenige...


Exploring microsoft building 30: ein Zentrum für Innovation und Technologie im Jahr 2025
Die Neugestaltung des Arbeitsplatzes: Im Herzen der technologischen Entwicklung Redmonds Eingebettet in das Grün des weitläufigen Redmond-Campus stellt Microsoft Building...


Top KI-Tools zur Hausaufgabenhilfe im Jahr 2025
Die Entwicklung von KI zur Unterstützung von Schülern im modernen Klassenzimmer Die Panik vor einer Sonntagnacht-Abgabefrist wird langsam zur Vergangenheit....


OpenAI vs Mistral: Welches KI-Modell passt 2025 am besten zu Ihren Anforderungen an die Verarbeitung natürlicher Sprache?
Die Landschaft der Künstlichen Intelligenz hat sich 2026 dramatisch verändert. Die Rivalität, die das letzte Jahr prägte – insbesondere der...


wie man sich verabschiedet: sanfte Wege, Abschiede und Enden zu bewältigen
Die Kunst eines sanften Abschieds im Jahr 2026 meistern Abschied zu nehmen ist selten eine einfache Aufgabe. Ob Sie nun...


piratenschiff name generator: erstelle noch heute den legendären Namen deines Schiffs
Die perfekte Identität für dein maritimes Abenteuer gestalten Ein Schiff zu benennen ist weit mehr als eine einfache Beschriftung; es...


Kreativität freisetzen mit Diamond Body AI-Prompts im Jahr 2025
Meisterung des Diamond Body Frameworks für KI-Präzision Im sich schnell entwickelnden Umfeld des Jahres 2025 liegt der Unterschied zwischen einem...


Was ist Canvas? Alles, was Sie 2025 wissen müssen
Definition von Canvas im modernen digitalen Unternehmen Im Umfeld des Jahres 2026 hat sich der Begriff „Canvas“ über eine einzelne...


wie man die Tastaturbeleuchtung Ihres Laptops einschaltet: eine Schritt-für-Schritt-Anleitung
Meisterung der Tastaturbeleuchtung: Der unverzichtbare Schritt-für-Schritt-Leitfaden Das Tippen in einem schwach beleuchteten Raum, auf einem Nachtflug oder während einer späten...


beste Buch-Mockup-Aufforderungen für Midjourney im Jahr 2025
Optimierung der digitalen Buchvisualisierung mit Midjourney in der Post-2025-Ära Die Landschaft der digitalen Buchvisualisierung hat sich nach den algorithmischen Updates...


KI-gesteuerte Erwachsenenvideo-Generatoren: Die wichtigsten Innovationen, auf die man 2025 achten sollte
Der Beginn synthetischer Intimität: Neuinterpretation von Inhalten für Erwachsene im Jahr 2026 Das Feld des digitalen Ausdrucks hat einen grundsätzlichen...


ChatGPT vs LLaMA: Welches Sprachmodell wird 2025 dominieren?
Die kolossale Schlacht um die KI-Vorherrschaft: Offene Ökosysteme vs. Geschlossene Gärten Im sich schnell entwickelnden Umfeld der künstlichen Intelligenz ist...


Meisterung der ersten ch-Wörter: Tipps und Aktivitäten für frühe Leser
Entschlüsselung des Mechanismus der anfänglichen CH-Wörter in der frühen Alphabetisierung Spracherwerb bei frühen Lesern funktioniert bemerkenswert wie ein komplexes Betriebssystem:...


Howmanyofme Bewertung: Entdecken Sie, wie einzigartig Ihr Name wirklich ist
Die Geheimnisse deiner Namensidentität mit Daten entschlüsseln Dein Name ist mehr als nur ein Etikett auf dem Führerschein; er ist...
-

 Open Ai1 week ago
Open Ai1 week agoEntfesselung der Power von ChatGPT-Plugins: Verbessern Sie Ihr Erlebnis im Jahr 2025
-

 Open Ai6 days ago
Open Ai6 days agoMastering GPT Fine-Tuning: Ein Leitfaden zur effektiven Anpassung Ihrer Modelle im Jahr 2025
-
 Open Ai7 days ago
Open Ai7 days agoVergleich von OpenAIs ChatGPT, Anthropics Claude und Googles Bard: Welches generative KI-Tool wird 2025 die Vorherrschaft erlangen?
-

 Open Ai6 days ago
Open Ai6 days agoChatGPT-Preise im Jahr 2025: Alles, was Sie über Tarife und Abonnements wissen müssen
-

 Open Ai7 days ago
Open Ai7 days agoDas Auslaufen der GPT-Modelle: Was Nutzer im Jahr 2025 erwartet
-

 KI-Modelle6 days ago
KI-Modelle6 days agoGPT-4-Modelle: Wie Künstliche Intelligenz das Jahr 2025 verändert