

KI-Modelle
Verstehen des GPT-2-Ausgabedetektors: wie er funktioniert und warum er im Jahr 2025 wichtig ist
Die Mechanik hinter dem GPT-2 Output Detector im Zeitalter der generativen KI
Im sich schnell entwickelnden Umfeld des Jahres 2026 ist die Fähigkeit, zwischen von Menschen verfassten Texten und maschinell generierten Inhalten zu unterscheiden, für Pädagogen, Verleger und Entwickler gleichermaßen zu einer wichtigen Kompetenz geworden. Während wir heute eine Welt mit fortschrittlichen Modellen durchschreiten, bleibt die Basistechnologie des GPT-2 Output Detectors eine relevante Fallstudie im Bereich Maschinelles Lernen. Ursprünglich entwickelt, um von GPT-2 erzeugte Texte zu identifizieren, nutzt dieses Tool eine auf RoBERTa basierende Architektur zur Analyse sprachlicher Muster. Es funktioniert, indem es Wahrscheinlichkeitsverteilungen berechnet und nach den typischen mathematischen Signaturen sucht, die häufig mit künstlicher Generierung einhergehen.
Die grundlegende Prämisse ist einfach, aber komplex: Der Detector bewertet eine Textsequenz, um die Wahrscheinlichkeit vorherzusagen, ob sie „echt“ (menschlich) oder „gefälscht“ (maschinell) ist. Anders als ein menschlicher Redakteur, der auf Fluss oder Kreativität achtet, sucht die Software nach statistischer Vorhersagbarkeit. Wenn man die Entwicklung der ChatGPT KI nachverfolgt, sieht man, dass frühere Modelle deutliche digitale Spuren hinterließen. Der Detector benötigt eine Mindestanzahl an Eingaben – typischerweise etwa 50 Tokens –, um eine zuverlässige Wahrscheinlichkeitsbewertung zu erzeugen. Ist die Eingabe zu kurz, fehlen dem Textanalyse ausreichende Datenpunkte, um ein eindeutiges Urteil zu fällen, was zu unzuverlässigen Ergebnissen führt.

Vergleich der Genauigkeit der Detektion über Generationen hinweg
Als wir die ersten Iterationen der generativen KI hinter uns ließen, intensivierte sich das Katz-und-Maus-Spiel zwischen Generierung und Erkennung. Heute fragen sich Nutzer oft, wie herkömmliche Erkennungsmethoden im Vergleich zu Giganten wie GPT-4, GPT-5.0 und Googles Bard abschneiden. Die Realität ist nuanciert. Während der GPT-2 Detector für sein Namensmodell wegweisend war, hat die moderne natürliche Sprachverarbeitung einige seiner Parameter ohne Feineinstellung weniger wirksam gemacht. Neuere Large Language Models (LLMs) sind darauf ausgelegt, menschliche Unvorhersehbarkeit zu imitieren, was die Arbeit älterer Detectoren deutlich erschwert.
Um das aktuelle Ökosystem der Modellevaluation zu verstehen, ist es hilfreich, sich anzusehen, wie verschiedene Tools in Bezug auf bestimmte Kriterien abschneiden. Die folgende Tabelle zeigt die Stärken und Schwächen populärer Erkennungstools, die heute in professionellen und wissenschaftlichen Umgebungen verwendet werden:
| Detektionstool | Hauptanwendungsbereich | Stärken 🔍 | Beachtliche Schwächen ⚠️ |
|---|---|---|---|
| GPT-2 Output Detector | Forschung & Entwicklertests | Hohe Genauigkeit bei älteren Modell-Signaturen; Open-Source-Transparenz. | Probleme bei kurzen Texten (< 50 Tokens) sowie stark promptete GPT-5-Inhalte. |
| JustDone AI Detector | Studentisches & Akademisches Schreiben | Entwickelt für akademischen Tonfall; bietet umsetzbares Feedback zur Humanisierung. | Kann bei formaler Bearbeitung zu empfindlich sein und legitime Korrekturen markieren. |
| Originality.AI | Web-Publishing & SEO | Robust gegenüber GPT-3.5 und Bard; verfolgt Plagiate neben KI-Erkennung. | Aggressive Erkennung kann zu Fehlalarmen bei stark bearbeiteten Entwürfen führen. |
| GPTZero | Bildungseinrichtungen | Ausgewogene Bewertung mit niedrigerer Fehlalarmrate; detaillierte Hervorhebungen. | Kann komplexes, technisches menschliches Schreiben aufgrund der Struktur als künstlich markieren. |
Diese Daten unterstreichen einen wichtigen Trend: Kein einzelnes Tool ist unfehlbar. Für Entwickler, die diese Systeme via automatisierte ChatGPT-API-Workflows integrieren, ist die Abhängigkeit von einer einzigen Metrik riskant. Ein mehrschichtiger Ansatz, der Wahrscheinlichkeitswerte mit semantischer Analyse kombiniert, bietet den besten Schutz gegen Fehlklassifikationen.
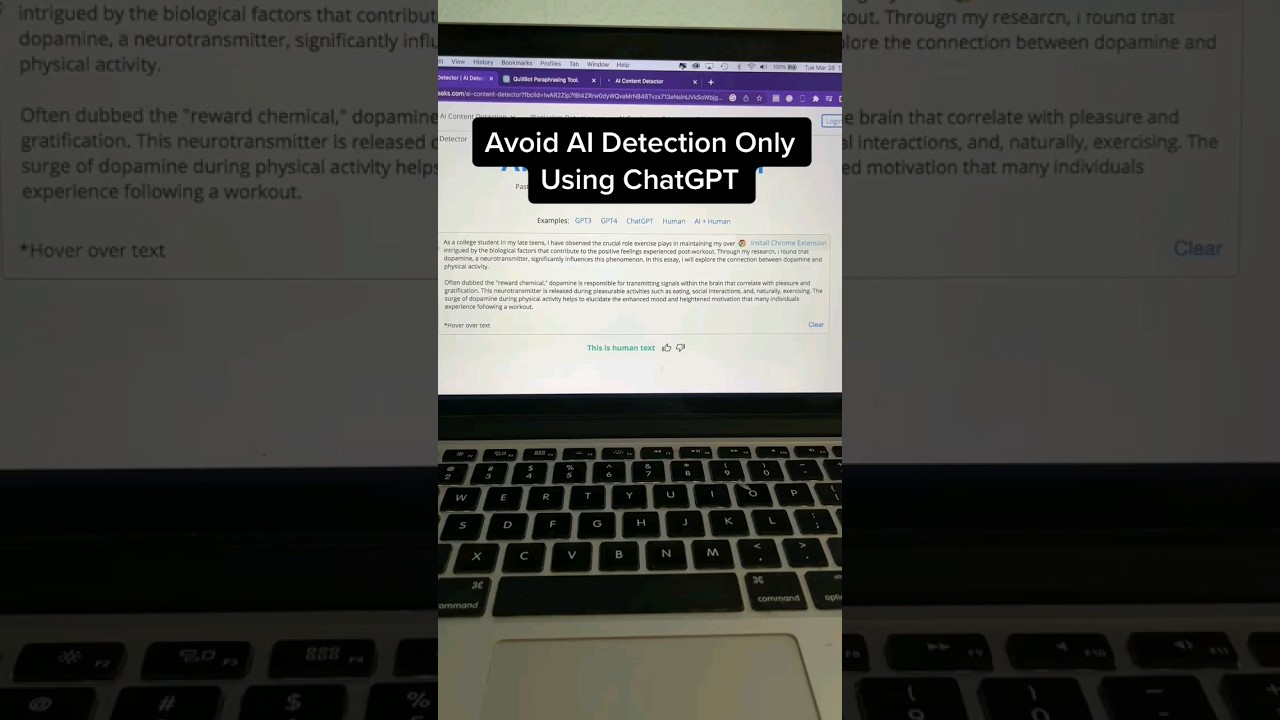
Detektion umgehen: Die Kunst der Humanisierung
Der Aufstieg der KI-Erkennung hat naturgemäß zur Entwicklung von Gegenstrategien geführt. Ob Studenten, die falsche Markierungen vermeiden wollen, oder Autoren, die ihre eigene Stimme bewahren möchten – das „Humanisieren“ von KI-Texten ist essenziell. Die Logik ist einfach: KI-Modelle sagen das nächste Wort aufgrund der höchsten Wahrscheinlichkeit voraus, während Menschen chaotisch und kreativ sind. Um diese Lücke zu schließen, muss man Varianz einführen – oft technisch als „Burstiness“ und „Perplexity“ bezeichnet.
Einfach das Modell zu bitten, „das umzuschreiben“, reicht 2026 selten aus. Effektive Humanisierung erfordert strategisches Prompting, das das Modell zwingt, seine eigenen statistischen Muster zu durchbrechen. Hier sind wirkungsvolle Strategien zur Verfeinerung KI-generierter Entwürfe:
- Persönlichen Kontext einbauen: KI erinnert sich nicht an persönliche Lebensereignisse. Das Einfügen von Ich-Erzählungen oder spezifischen, lokalisierten Bezügen senkt die „Fake“-Wahrscheinlichkeit erheblich.
- Satzstruktur variieren: Maschinen bevorzugen mittel-lange, grammatikalisch perfekte Sätze. Das bewusste Mischen von kurzen, prägnanten Fragmenten mit langen, komplexen zusammengesetzten Sätzen durchbricht die Maschinensignatur.
- Absichtliche Imperfektion: Ein ausgefeilter Text wirkt verdächtig. Ein „Rohentwurf“-Stil mit Umgangssprache oder kleinen informellen Elementen kann starre Filter umgehen.
- Stilmischung: Die KI anweisen, widersprüchliche Töne wie „formell-akademisch“ gemischt mit „konversationellem Blog“ zu kombinieren, erzeugt eine einzigartige hybride Stimme.
Diese Techniken umzusetzen bewirkt mehr, als nur Detektoren zu umgehen; sie verbessert die Qualität der Inhalte. Betrachtet man die Innovationen, die in GPT-4.5 und darüber hinaus erwarten, verwischen die Grenzen zwischen Werkzeug und Kollaborateur. Ziel ist nicht Täuschung, sondern sicherzustellen, dass das Endergebnis mit menschlicher Authentizität resoniert.
Ethische Implikationen von Fehlalarmen im Jahr 2026
Die Abhängigkeit von automatisierten Erkennungstools wirft bedeutende Fragen zur KI-Ethik auf. Wir erleben Szenarien, in denen Studierende wegen unvollkommenen Wahrscheinlichkeitsbewertungen disziplinarisch belangt werden und Angestellte unter Beobachtung geraten. Ein Fehlalarm – menschliche Arbeit als maschinell generiert zu identifizieren – kann Rufschäden verursachen und Vertrauen untergraben. Besonders besorgniserregend ist dies, wenn man bedenkt, dass Nicht-Muttersprachler oft mit der für Erkennungssysteme typischen vorhersehbaren, grammatikalischen Präzision schreiben, die als „KI“ markiert wird.
Darüber hinaus verändert der Druck, Urheberschaft zu beweisen, die Art, wie wir schreiben. Paradoxerweise beginnen Menschen, weniger formell zu schreiben, um nicht des KI-Gebrauchs beschuldigt zu werden – ein Phänomen, das manche als „Reverse Turing Coercion“ bezeichnen. Die Sicherstellung von Inhaltsauthentizität erfordert einen Perspektivwechsel: Werkzeuge sollten zum Verifizieren und nicht zum Verurteilen genutzt werden. Im Unternehmenssektor, wo Firmen die Rivalität zwischen OpenAI und Anthropic erforschen, verlagert sich der Fokus auf „Provenienz“ – die Nachverfolgung des Entstehungsprozesses eines Dokuments statt der Analyse des Endtexts.
Das Verständnis der Grenzen dieser Tools ist auch für das psychische Wohlbefinden wichtig. Die mit akademischer Integrität im KI-Zeitalter verbundene Angst darf nicht unterschätzt werden. Wir müssen diese Beschränkungen und Strategien für ChatGPT im Jahr 2025 und darüber hinaus mit einer ausgewogenen Einstellung angehen, damit die Technologie uns dient, anstatt uns unangemessen zu kontrollieren.

Wenn wir auf Zukunftstechnologien 2025 und die folgenden Jahre blicken, steht der GPT-2 Output Detector als grundlegende Säule. Er erinnert uns daran, dass Maschinen zwar Sprache generieren können, das Verständnis von Nuancen, Absicht und Ursprung dieser Sprache jedoch eine zutiefst menschliche Aufgabe bleibt. Ganz gleich, ob Sie eine neue LLM-Anwendung debuggen oder einfach nur einen Aufsatz einreichen möchten – das Erkennen der Funktionsweise dieser Detectoren befähigt Sie, transparent und effektiv mit KI zusammenzuarbeiten.
Wie zuverlässig ist der GPT-2 Output Detector für moderne Modelle?
Während er für die frühe Erkennung Maßstäbe setzte, ist der GPT-2 Output Detector für fortgeschrittene Modelle wie GPT-4 oder GPT-5.0 ohne Feineinstellung weniger zuverlässig. Er arbeitet am besten mit Texten, die der Architektur von GPT-2 ähneln, und kann Schwierigkeiten mit stark humanisierten oder stark bearbeiteten Inhalten neuerer LLMs haben.
Warum benötigt der Detector mindestens 50 Tokens?
Das zugrundeliegende RoBERTa-Modell benötigt eine ausreichende Stichprobengröße, um statistische Muster und Wahrscheinlichkeitsverteilungen genau analysieren zu können. Mit weniger als 50 Tokens sind die Daten zu spärlich, um zwischen menschlicher Unvorhersehbarkeit und maschineller Konsistenz zu unterscheiden, was zu unklaren Ergebnissen führt.
Kann menschliches Schreiben als KI-generiert markiert werden?
Ja, Fehlalarme sind ein erhebliches Problem. Technisches Schreiben, Nicht-Muttersprachler, die formale Grammatik verwenden, oder stark strukturierter juristischer Text zeigen oft die niedrige „Perplexity“, die Detectoren mit KI assoziieren, was zu falschen Markierungen als maschinell erzeugt führt.
Ist es möglich, KI-Erkennung vollständig zu umgehen?
Es ist möglich, die Wahrscheinlichkeit der Erkennung deutlich zu reduzieren, indem man „humanisierende“ Strategien wie Variation der Satzstruktur, Einfügen persönlicher Anekdoten und Veränderung des Vokabulars anwendet. Allerdings garantiert keine Methode eine 100%ige Umgehung, da Erkennungsalgorithmen sich parallel zu generativen Modellen weiterentwickeln.



entdecke die faszinierendsten Muschelnamen und ihre Bedeutungen
Entschlüsselung der verborgenen Daten mariner Architekturen Der Ozean fungiert als ein riesiges, dezentralisiertes Archiv biologischer Geschichte. Innerhalb dieses Raums sind...


Funko pop Nachrichten: Neueste Veröffentlichungen und exklusive Drops im Jahr 2025
Wichtige Funko Pop Neuigkeiten 2025 und die andauernde Wirkung in 2026 Die Landschaft des Sammelns hat sich in den letzten...


wer ist hans walters? die geschichte hinter dem namen im jahr 2025 enthüllt
Das Rätsel um Hans Walters: Analyse des digitalen Fußabdrucks im Jahr 2026 Im weiten Informationsraum von heute präsentieren nur wenige...


Exploring microsoft building 30: ein Zentrum für Innovation und Technologie im Jahr 2025
Die Neugestaltung des Arbeitsplatzes: Im Herzen der technologischen Entwicklung Redmonds Eingebettet in das Grün des weitläufigen Redmond-Campus stellt Microsoft Building...


Top KI-Tools zur Hausaufgabenhilfe im Jahr 2025
Die Entwicklung von KI zur Unterstützung von Schülern im modernen Klassenzimmer Die Panik vor einer Sonntagnacht-Abgabefrist wird langsam zur Vergangenheit....


OpenAI vs Mistral: Welches KI-Modell passt 2025 am besten zu Ihren Anforderungen an die Verarbeitung natürlicher Sprache?
Die Landschaft der Künstlichen Intelligenz hat sich 2026 dramatisch verändert. Die Rivalität, die das letzte Jahr prägte – insbesondere der...


wie man sich verabschiedet: sanfte Wege, Abschiede und Enden zu bewältigen
Die Kunst eines sanften Abschieds im Jahr 2026 meistern Abschied zu nehmen ist selten eine einfache Aufgabe. Ob Sie nun...


piratenschiff name generator: erstelle noch heute den legendären Namen deines Schiffs
Die perfekte Identität für dein maritimes Abenteuer gestalten Ein Schiff zu benennen ist weit mehr als eine einfache Beschriftung; es...


Kreativität freisetzen mit Diamond Body AI-Prompts im Jahr 2025
Meisterung des Diamond Body Frameworks für KI-Präzision Im sich schnell entwickelnden Umfeld des Jahres 2025 liegt der Unterschied zwischen einem...


Was ist Canvas? Alles, was Sie 2025 wissen müssen
Definition von Canvas im modernen digitalen Unternehmen Im Umfeld des Jahres 2026 hat sich der Begriff „Canvas“ über eine einzelne...


wie man die Tastaturbeleuchtung Ihres Laptops einschaltet: eine Schritt-für-Schritt-Anleitung
Meisterung der Tastaturbeleuchtung: Der unverzichtbare Schritt-für-Schritt-Leitfaden Das Tippen in einem schwach beleuchteten Raum, auf einem Nachtflug oder während einer späten...


beste Buch-Mockup-Aufforderungen für Midjourney im Jahr 2025
Optimierung der digitalen Buchvisualisierung mit Midjourney in der Post-2025-Ära Die Landschaft der digitalen Buchvisualisierung hat sich nach den algorithmischen Updates...


KI-gesteuerte Erwachsenenvideo-Generatoren: Die wichtigsten Innovationen, auf die man 2025 achten sollte
Der Beginn synthetischer Intimität: Neuinterpretation von Inhalten für Erwachsene im Jahr 2026 Das Feld des digitalen Ausdrucks hat einen grundsätzlichen...


ChatGPT vs LLaMA: Welches Sprachmodell wird 2025 dominieren?
Die kolossale Schlacht um die KI-Vorherrschaft: Offene Ökosysteme vs. Geschlossene Gärten Im sich schnell entwickelnden Umfeld der künstlichen Intelligenz ist...


Meisterung der ersten ch-Wörter: Tipps und Aktivitäten für frühe Leser
Entschlüsselung des Mechanismus der anfänglichen CH-Wörter in der frühen Alphabetisierung Spracherwerb bei frühen Lesern funktioniert bemerkenswert wie ein komplexes Betriebssystem:...


Howmanyofme Bewertung: Entdecken Sie, wie einzigartig Ihr Name wirklich ist
Die Geheimnisse deiner Namensidentität mit Daten entschlüsseln Dein Name ist mehr als nur ein Etikett auf dem Führerschein; er ist...


Verstehen des GPT-2-Ausgabedetektors: wie er funktioniert und warum er im Jahr 2025 wichtig ist
Die Mechanik hinter dem GPT-2 Output Detector im Zeitalter der generativen KI Im sich schnell entwickelnden Umfeld des Jahres 2026...


Wie man Pirate Weather mit Home Assistant integriert: eine vollständige Schritt-für-Schritt-Anleitung
Die Entwicklung hyperlokaler Wetterdaten in Smart-Home-Ökosystemen Zuverlässigkeit ist das Fundament jeder effektiven Smart Home-Einrichtung. Im Jahr 2026, in dem die...


2025 Leitfaden zu den besten NSFW AI Art Creators: Trends und unverzichtbare Tools
Die Entwicklung der digitalen Erotik und der technologische Wandel im Jahr 2025 Die Landschaft der Digital Art hat einen gewaltigen...


OpenAI vs Meta: Erforschung der wichtigsten Unterschiede zwischen ChatGPT und Llama 3 im Jahr 2025
Die KI-Landschaft Ende 2025: Ein Kampf der Giganten Der Bereich der künstlichen Intelligenz hat seit der Veröffentlichung von Meta’s Llama...
-

 Open Ai6 days ago
Open Ai6 days agoEntfesselung der Power von ChatGPT-Plugins: Verbessern Sie Ihr Erlebnis im Jahr 2025
-

 Open Ai5 days ago
Open Ai5 days agoMastering GPT Fine-Tuning: Ein Leitfaden zur effektiven Anpassung Ihrer Modelle im Jahr 2025
-
 Open Ai6 days ago
Open Ai6 days agoVergleich von OpenAIs ChatGPT, Anthropics Claude und Googles Bard: Welches generative KI-Tool wird 2025 die Vorherrschaft erlangen?
-

 Open Ai5 days ago
Open Ai5 days agoChatGPT-Preise im Jahr 2025: Alles, was Sie über Tarife und Abonnements wissen müssen
-

 Open Ai6 days ago
Open Ai6 days agoDas Auslaufen der GPT-Modelle: Was Nutzer im Jahr 2025 erwartet
-

 KI-Modelle5 days ago
KI-Modelle5 days agoGPT-4-Modelle: Wie Künstliche Intelligenz das Jahr 2025 verändert