

Modèles d’IA
Comprendre le détecteur de sortie gpt-2 : comment il fonctionne et pourquoi c’est important en 2025
Les Mécanismes Derrière le Détecteur de Sortie GPT-2 à l’Ère de l’IA Générative
Dans le paysage en évolution rapide de 2026, la capacité de distinguer entre des récits écrits par des humains et du contenu généré par des machines est devenue une compétence cruciale pour les éducateurs, les éditeurs et les développeurs. Alors que nous naviguons désormais dans un monde peuplé de modèles avancés, la technologie fondamentale du détecteur de sortie GPT-2 reste une étude de cas pertinente en apprentissage automatique. Initialement développé pour identifier le texte synthétisé par le modèle GPT-2, cet outil utilise une architecture basée sur RoBERTa pour analyser les motifs linguistiques. Il fonctionne en calculant des distributions de probabilité, à la recherche des signatures mathématiques révélatrices qui accompagnent souvent la génération artificielle.
Le principe de base est simple mais sophistiqué : le détecteur évalue une séquence de texte pour prédire la probabilité qu’elle soit « réelle » (humaine) ou « fausse » (machine). Contrairement à un éditeur humain qui cherche la fluidité ou la créativité, le logiciel scrute la prévisibilité statistique. En suivant l’évolution de ChatGPT AI, nous constatons que les premiers modèles laissaient des empreintes numériques distinctes. Le détecteur requiert une entrée minimale — généralement autour de 50 tokens — pour générer un score de probabilité fiable. Si l’entrée est trop courte, l’analyse de texte manque de points de données suffisants pour formuler un jugement concluant, ce qui conduit à des résultats peu fiables.

Comparaison de la Précision de Détection à Travers les Générations
À mesure que nous avons dépassé les premières itérations de l’IA générative, le jeu du chat et de la souris entre génération et détection s’est intensifié. Aujourd’hui, les utilisateurs se demandent souvent comment les méthodes de détection héritées se comparent aux géants comme GPT-4, GPT-5.0 et Bard de Google. La réalité est nuancée. Alors que le détecteur GPT-2 était à la pointe pour son modèle éponyme, le traitement du langage naturel moderne a rendu certains de ses paramètres moins efficaces sans ajustement. Les nouveaux modèles de grande taille (LLM) sont conçus pour imiter l’imprévisibilité humaine, rendant la tâche des détecteurs plus anciens nettement plus difficile.
Pour comprendre l’écosystème actuel de l’évaluation des modèles, il est utile d’examiner comment différents outils performent selon des critères spécifiques. Le tableau suivant détaille les forces et faiblesses des utilitaires de détection populaires utilisés dans les milieux professionnels et académiques aujourd’hui :
| Outil de Détection | Cas d’Usage Principal | Forces Clés 🔍 | Faiblesses Notables ⚠️ |
|---|---|---|---|
| Détecteur de Sortie GPT-2 | Recherche & Tests Développeurs | Haute précision sur les signatures des anciens modèles ; transparence open-source. | Peine avec les textes courts (< 50 tokens) et le contenu fortement sollicité par GPT-5. |
| JustDone AI Detector | Écriture Étudiante & Académique | Conçu pour un ton académique ; fournit des retours exploitables pour l’humanisation. | Peut être trop sensible aux corrections formelles, signalant les révisions légitimes. |
| Originality.AI | Publication Web & SEO | Robuste contre GPT-3.5 et Bard ; suit le plagiat en parallèle de l’IA. | La détection agressive peut entraîner de faux positifs sur des brouillons très édités. |
| GPTZero | Institutions Éducatives | Score équilibré avec des taux de faux positifs plus faibles ; mises en évidence détaillées. | Peut signaler l’écriture humaine technique et complexe comme artificielle à cause de la structure. |
Ces données mettent en lumière une tendance cruciale : aucun outil n’est infaillible. Pour les développeurs intégrant ces systèmes via des workflows automatisés ChatGPT API, s’appuyer sur une seule métrique peut être risqué. Une approche à plusieurs niveaux, combinant scores de probabilité et analyse sémantique, offre la meilleure défense contre les erreurs de classification.
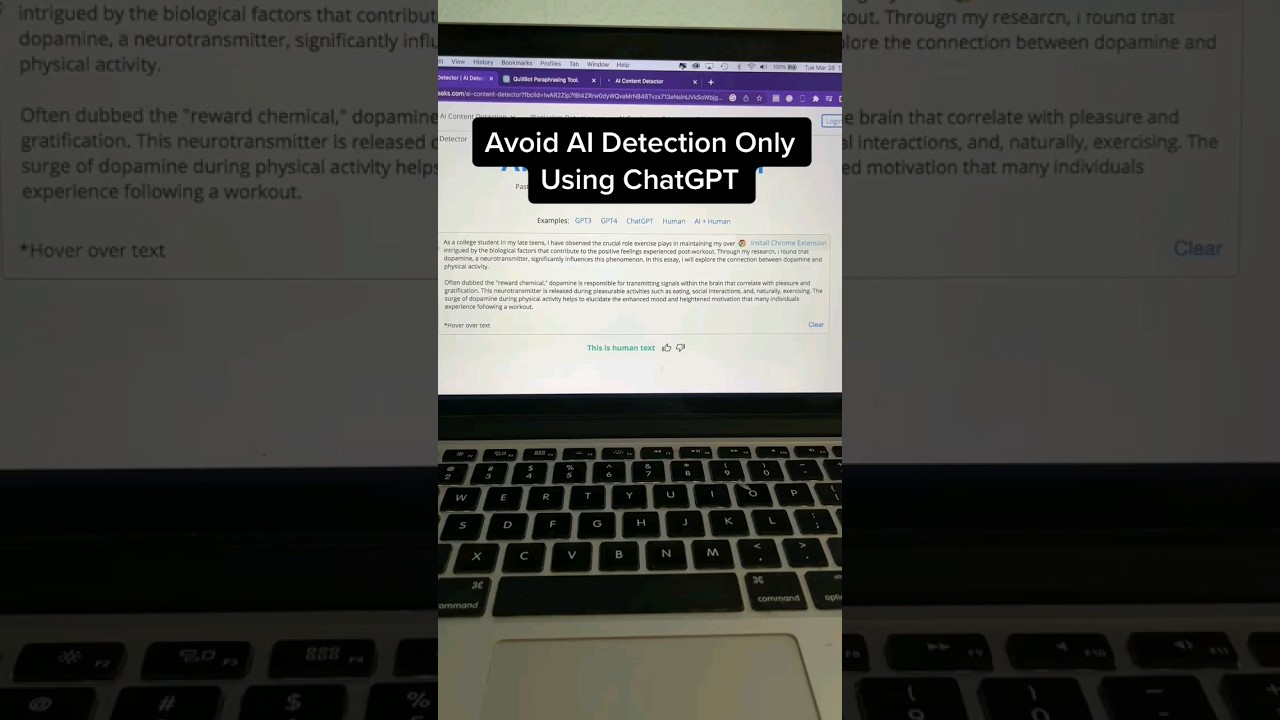
Contourner la Détection : L’Art de l’Humanisation
L’essor de la détection IA a naturellement conduit au développement de contre-stratégies. Que ce soit pour les étudiants cherchant à éviter un signalement injuste ou les rédacteurs visant à conserver une voix distincte, « humaniser » un texte IA est essentiel. La logique est simple : les modèles IA prédisent le mot suivant en fonction de la probabilité la plus élevée, tandis que les humains sont chaotiques et créatifs. Pour combler cet écart, il faut introduire de la variance — souvent appelée « burstiness » et « perplexité » en termes techniques.
Demander simplement à un modèle de « réécrire ceci » est rarement suffisant en 2026. Une humanisation efficace nécessite un prompting stratégique qui force le modèle à rompre ses propres schémas statistiques. Voici des stratégies impactantes pour affiner les brouillons générés par IA :
- Injecter un Contexte Personnel : L’IA ne se souvient pas des événements personnels. Ajouter des anecdotes à la première personne ou des références localisées spécifiques réduit significativement le score de probabilité « faux ».
- Varier la Structure des Phrases : Les machines aiment les phrases de longueur moyenne, grammaticalement parfaites. Mélanger délibérément des fragments courts et percutants avec des phrases longues et complexes brise la signature machine.
- Imperfection Intentionnelle : Un texte poli est suspect. Demander un style de « brouillon » avec des colloquialismes ou de légères informalités peut contourner les filtres rigides.
- Mélange de Styles : Instruire l’IA à combiner des tons contradictoires, comme « formel académique » mêlé à « blog conversationnel », pour créer une voix hybride unique.
Mettre en œuvre ces techniques fait plus que contourner les détecteurs ; cela améliore la qualité du contenu. En regardant quelles innovations attendent GPT-4.5 et au-delà, la frontière entre outil et collaborateur s’estompe. Le but n’est pas de tromper, mais d’assurer que le résultat final résonne d’une authenticité humaine.
Implications Éthiques des Faux Positifs en 2026
La dépendance aux outils de détection automatisés soulève d’importantes questions en matière de déontologie de l’IA. Nous assistons à des cas où des étudiants font face à des sanctions disciplinaires et où des employés subissent un examen minutieux basé sur des scores de probabilité imparfaits. Un faux positif — identifier un travail humain comme généré par machine — peut nuire à la réputation et éroder la confiance. Cela est particulièrement préoccupant quand on considère que les locuteurs non natifs écrivent souvent avec la précision grammaticale prévisible que les détecteurs associent à l’IA.
De plus, la pression pour prouver la paternité modifie notre façon d’écrire. Paradoxalement, les humains commencent à écrire de façon moins formelle pour éviter l’accusation d’utiliser l’IA, un phénomène que certains appellent la « coercition inversée de Turing ». Assurer l’authenticité du contenu nécessite un changement de perspective : les outils doivent être utilisés pour vérifier, non pour poursuivre. Dans le secteur corporatif, alors que les entreprises explorent la rivalité entre OpenAI et Anthropic, l’accent se porte sur la « provenance » — suivre le processus de création d’un document plutôt que d’analyser le texte final.
Comprendre les limites de ces outils est également vital pour le bien-être mental. L’anxiété liée à l’intégrité académique à l’ère de l’IA n’est pas négligeable. Nous devons naviguer ces limites et stratégies pour ChatGPT en 2025 et au-delà avec un esprit équilibré, assurant que la technologie nous serve plutôt que de nous contrôler de manière déraisonnable.

En regardant vers la technologie future de 2025 et les années suivantes, le détecteur de sortie GPT-2 demeure un pilier fondamental. Il nous rappelle que si les machines peuvent générer du langage, comprendre la nuance, l’intention et l’origine de ce langage reste une exigence strictement humaine. Que vous déboguiez une nouvelle application LLM ou que vous essayiez simplement de soumettre un essai, reconnaître les mécanismes de ces détecteurs vous permet de collaborer avec l’IA de manière transparente et efficace.
{« @context »: »https://schema.org », »@type »: »FAQPage », »mainEntity »:[{« @type »: »Question », »name »: »How reliable is the GPT-2 Output Detector for modern models? », »acceptedAnswer »:{« @type »: »Answer », »text »: »While it set the standard for early detection, the GPT-2 Output Detector is less reliable for advanced models like GPT-4 or GPT-5.0 without fine-tuning. It works best on text similar to GPT-2’s architecture and may struggle with highly humanized or heavily edited content from newer LLMs. »}},{« @type »: »Question », »name »: »Why does the detector require at least 50 tokens? », »acceptedAnswer »:{« @type »: »Answer », »text »: »The underlying RoBERTa model needs a sufficient sample size to analyze statistical patterns and probability distributions accurately. With fewer than 50 tokens, the data is too sparse to distinguish between human unpredictability and machine consistency, leading to inconclusive results. »}},{« @type »: »Question », »name »: »Can human writing be flagged as AI-generated? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Yes, false positives are a significant issue. Technical writing, non-native English speakers using formal grammar, or highly structured legal text often exhibit the low ‘perplexity’ that detectors associate with AI, causing them to be incorrectly flagged as machine-generated. »}},{« @type »: »Question », »name »: »Is it possible to completely bypass AI detection? », »acceptedAnswer »:{« @type »: »Answer », »text »: »It is possible to significantly reduce the likelihood of detection by using ‘humanizing’ strategies such as varying sentence structure, injecting personal anecdotes, and altering vocabulary. However, as detection algorithms evolve alongside generative models, no method guarantees a 100% bypass rate indefinitely. »}}]}How reliable is the GPT-2 Output Detector for modern models?
While it set the standard for early detection, the GPT-2 Output Detector is less reliable for advanced models like GPT-4 or GPT-5.0 without fine-tuning. It works best on text similar to GPT-2’s architecture and may struggle with highly humanized or heavily edited content from newer LLMs.
Why does the detector require at least 50 tokens?
The underlying RoBERTa model needs a sufficient sample size to analyze statistical patterns and probability distributions accurately. With fewer than 50 tokens, the data is too sparse to distinguish between human unpredictability and machine consistency, leading to inconclusive results.
Can human writing be flagged as AI-generated?
Yes, false positives are a significant issue. Technical writing, non-native English speakers using formal grammar, or highly structured legal text often exhibit the low ‘perplexity’ that detectors associate with AI, causing them to be incorrectly flagged as machine-generated.
Is it possible to completely bypass AI detection?
It is possible to significantly reduce the likelihood of detection by using ‘humanizing’ strategies such as varying sentence structure, injecting personal anecdotes, and altering vocabulary. However, as detection algorithms evolve alongside generative models, no method guarantees a 100% bypass rate indefinitely.



découvrez les noms de coquillages les plus fascinants et leurs significations
Déchiffrer les données cachées des architectures marines L’océan fonctionne comme une vaste archive décentralisée de l’histoire biologique. Dans cette étendue,...


Funko pop actualités : dernières sorties et exclusivités en 2025
Principales nouveautés Funko Pop de 2025 et l’impact continu en 2026 Le paysage de la collection a changé radicalement au...


qui est hans walters ? dévoiler l’histoire derrière le nom en 2025
L’Énigme de Hans Walters : Analyser l’empreinte numérique en 2026 Dans l’immense étendue d’informations disponible aujourd’hui, peu d’identificateurs présentent une...


Explorer le microsoft building 30 : un centre d’innovation et de technologie en 2025
Redéfinir l’espace de travail : au cœur de l’évolution technologique de Redmond Niché au milieu de la verdure du vaste...


Meilleurs outils d’IA pour l’aide aux devoirs en 2025
L’évolution de l’IA d’assistance aux étudiants dans la classe moderne La panique liée à un délai le dimanche soir devient...


OpenAI vs Mistral : Quel modèle d’IA conviendra le mieux à vos besoins en traitement du langage naturel en 2025 ?
Le paysage de l’Intelligence Artificielle a profondément changé alors que nous avançons en 2026. La rivalité qui a marqué l’année...


comment dire au revoir : des façons douces de gérer les adieux et les fins
Naviguer dans l’art d’un adieu en douceur en 2026 Dire adieu est rarement une tâche simple. Que vous pivotiez vers...


générateur de noms de navires pirates : créez le nom de votre navire légendaire dès aujourd’hui
Concevoir l’Identité Parfaite pour Votre Aventure Maritime Nommer un navire n’est pas simplement un exercice d’étiquetage ; c’est un acte de...


Libérer la créativité avec les prompts AI diamond body en 2025
Maîtriser le Cadre Diamond Body pour une Précision IA Dans le paysage en évolution rapide de 2025, la différence entre...


Qu’est-ce que canvas ? Tout ce que vous devez savoir en 2025
Définir Canvas dans l’Entreprise Numérique Moderne Dans le paysage de 2026, le terme « Canvas » a évolué au-delà d’une...


comment allumer la lumière du clavier de votre ordinateur portable : un guide étape par étape
Maîtriser l’illumination du clavier : Le guide essentiel étape par étape Taper dans une pièce faiblement éclairée, lors d’un vol...


meilleures suggestions de maquettes de livre pour midjourney en 2025
Optimiser la Visualisation des Livres Numériques avec Midjourney à l’Ère Post-2025 Le paysage de la visualisation des livres numériques a...


Générateurs de vidéos pour adultes pilotés par l’IA : les principales innovations à surveiller en 2025
L’aube de l’intimité synthétique : redéfinir le contenu pour adultes en 2026 Le paysage de l’expression digitale a connu un bouleversement...


ChatGPT vs LLaMA : Quel modèle de langue dominera en 2025 ?
La bataille colossale pour la suprématie de l’IA : écosystèmes ouverts vs jardins clos Dans le paysage en rapide évolution...


Maîtriser les mots commençant par ch : conseils et activités pour les jeunes lecteurs
Décoder le Mécanisme des Mots Initials en CH dans l’Alphabétisation Précoce L’acquisition du langage chez les jeunes lecteurs fonctionne remarquablement...


Howmanyofme avis : découvrez à quel point votre nom est vraiment unique
Déverrouiller les secrets de l’identité de votre nom avec des données Votre nom est bien plus qu’une simple étiquette sur...


Comprendre le détecteur de sortie gpt-2 : comment il fonctionne et pourquoi c’est important en 2025
Les Mécanismes Derrière le Détecteur de Sortie GPT-2 à l’Ère de l’IA Générative Dans le paysage en évolution rapide de...


Comment intégrer pirate weather avec home assistant : un guide complet étape par étape
L’évolution des données météorologiques hyper-locales dans les écosystèmes de maisons intelligentes La fiabilité est la pierre angulaire de toute installation...


Guide complet 2025 des meilleurs créateurs d’art IA NSFW : tendances et outils essentiels
L’évolution de l’érotisme numérique et le changement technologique de 2025 Le paysage de l’art numérique a connu un bouleversement sismique,...


OpenAI vs Meta : Explorer les différences clés entre ChatGPT et Llama 3 en 2025
Le paysage de l’IA à la fin de 2025 : un affrontement de titans Le secteur de l’intelligence artificielle a...
-

 Open Ai6 jours ago
Open Ai6 jours agoLibérer la puissance des Plugins ChatGPT : améliorez votre expérience en 2025
-

 Open Ai5 jours ago
Open Ai5 jours agoMaîtriser l’ajustement fin de GPT : un guide pour personnaliser efficacement vos modèles en 2025
-
 Open Ai6 jours ago
Open Ai6 jours agoComparer ChatGPT d’OpenAI, Claude d’Anthropic et Bard de Google : quel outil d’IA générative dominera en 2025 ?
-

 Open Ai5 jours ago
Open Ai5 jours agoTarification de ChatGPT en 2025 : Tout ce que vous devez savoir sur les tarifs et abonnements
-

 Open Ai6 jours ago
Open Ai6 jours agoLa suppression progressive des modèles GPT : à quoi les utilisateurs peuvent s’attendre en 2025
-

 Modèles d’IA5 jours ago
Modèles d’IA5 jours agoModèles GPT-4 : Comment l’intelligence artificielle transforme 2025