

Модели ИИ
Понимание детектора вывода gpt-2: как он работает и почему это важно в 2025 году
Механика работы детектора вывода GPT-2 в эпоху генеративного ИИ
В быстро меняющемся ландшафте 2026 года умение различать написанные человеком тексты и сгенерированные машинами стало критически важным навыком для преподавателей, издателей и разработчиков. Хотя сейчас мы ориентируемся в мире, населенном продвинутыми моделями, базовая технология детектора вывода GPT-2 по-прежнему является актуальным примером машинного обучения. Первоначально разработанный для выявления текста, синтезированного моделью GPT-2, этот инструмент использует архитектуру на базе RoBERTa для анализа языковых паттернов. Он функционирует, вычисляя распределения вероятностей, и ищет характерные математические сигнатуры, часто сопровождающие искусственную генерацию.
Основная идея проста, но изящна: детектор оценивает последовательность текста, чтобы предсказать вероятность того, что он является «настоящим» (человеческим) или «фальшивым» (машинным). В отличие от человека-редактора, который обращает внимание на плавность или креативность, программное обеспечение сканирует статистическую предсказуемость. При отслеживании эволюции ChatGPT AI видно, что ранние модели оставляли отчетливые цифровые отпечатки. Детектор требует минимального объёма ввода — обычно около 50 токенов — для генерации надежного коэффициента вероятности. Если вход слишком короткий, текстовый анализ не имеет достаточного количества данных для вынесения однозначного суждения, что ведет к ненадежным результатам.

Сравнение точности детекции между поколениями
По мере того как мы прошли начальные итерации генеративного ИИ, игра в кошки-мышки между генерацией и детекцией усилилась. Сегодня пользователи часто задаются вопросом, как унаследованные методы детекции сопоставляются с гигантами вроде GPT-4, GPT-5.0 и Bard от Google. Реальность сложна. Пока детектор GPT-2 был передовым инструментом своего времени, современные методы обработки естественного языка сделали некоторые его параметры менее эффективными без дополнительной настройки. Новые крупные языковые модели (LLMs) разработаны так, чтобы имитировать человеческую непредсказуемость, что значительно усложняет работу старых детекторов.
Чтобы понять текущую экосистему оценки моделей, полезно посмотреть, как различные инструменты работают по определённым критериям. Следующая таблица разбирает сильные и слабые стороны популярных утилит детекции, используемых в профессиональной и академической среде сегодня:
| Инструмент детекции | Основное назначение | Ключевые преимущества 🔍 | Заметные недостатки ⚠️ |
|---|---|---|---|
| Детектор вывода GPT-2 | Исследования и тестирование для разработчиков | Высокая точность на сигнатурах старых моделей; открытая прозрачность исходного кода. | Плохо работает на коротких текстах (< 50 токенов) и в случае контента GPT-5 с сильным промптингом. |
| JustDone AI Detector | Студенческое и академическое письмо | Создан для академического стиля; предоставляет действенную обратную связь для «очеловечивания» текста. | Может быть слишком чувствительным к формальному редактированию, отмечая легитимные исправления. |
| Originality.AI | Веб-публикации и SEO | устойчив к GPT-3.5 и Bard; отслеживает плагиат и ИИ. | Агрессивная детекция может приводить к ложным срабатываниям на сильно отредактированных черновиках. |
| GPTZero | Образовательные учреждения | Сбалансированная оценка с низким уровнем ложных срабатываний; детальное выделение. | Может помечать сложные технические тексты человека как искусственные из-за структуры. |
Эти данные подчеркивают ключевую тенденцию: ни один инструмент не является безошибочным. Для разработчиков, интегрирующих эти системы через автоматизированные рабочие процессы API ChatGPT, полагаться на единую метрику рискованно. Многоуровневый подход, сочетающий вероятностные показатели с семантическим анализом, обеспечивает наилучшую защиту от ошибочной классификации.
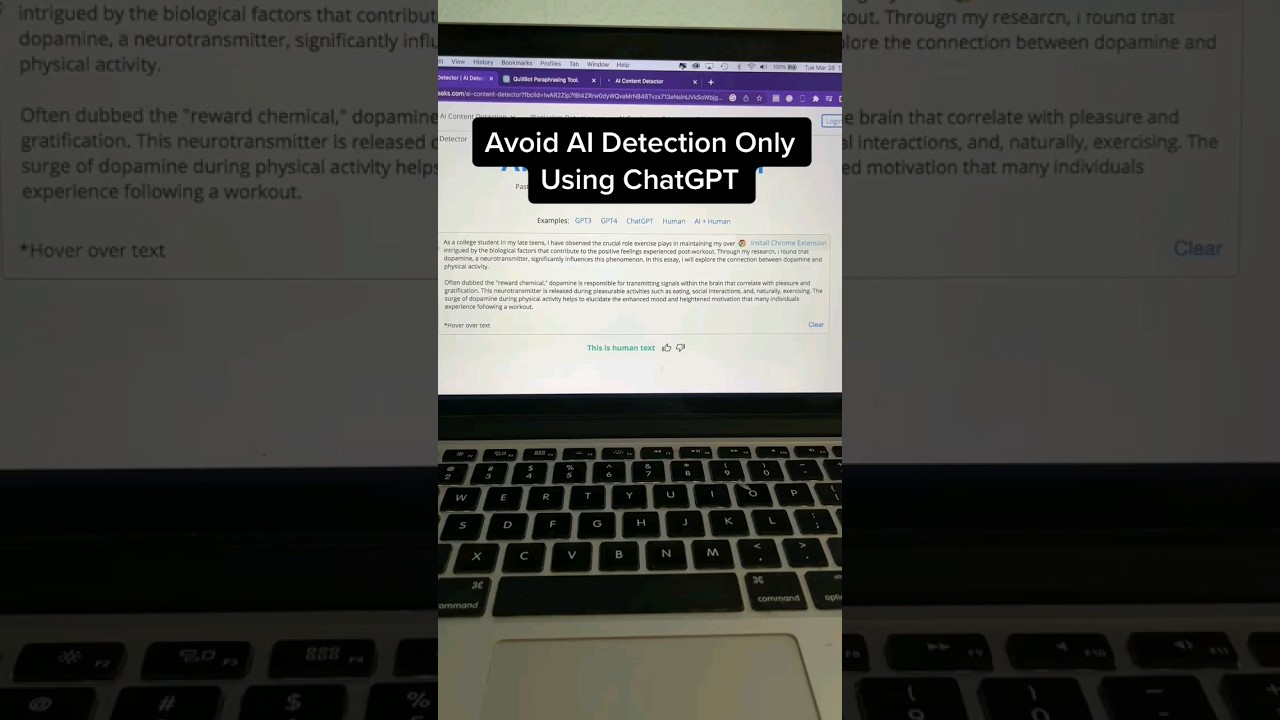
Обход детекции: искусство очеловечивания
Рост детекции ИИ естественным образом привел к развитию контрмер. Будь то студенты, стремящиеся избежать несправедливого флага, или писатели, желающие сохранить уникальный голос, «очеловечивание» текста ИИ становится необходимым. Логика проста: модели ИИ предсказывают следующее слово, основываясь на наивысшей вероятности, тогда как люди хаотичны и креативны. Чтобы преодолеть этот разрыв, нужно вносить разнообразие — технически известное как «бурстность» и «неопределённость».
Просто попросить модель «переписать это» в 2026 году редко достаточно. Эффективное очеловечивание требует стратегического промптинга, который заставляет модель ломать собственные статистические паттерны. Вот эффективные стратегии для улучшения черновиков, сгенерированных ИИ:
- Внедрение личного контекста: ИИ не хранит воспоминаний о личных событиях. Добавление повествований от первого лица или конкретных, локализованных ссылок значительно снижает вероятность «фальшивости».
- Разнообразие структуры предложений: Машины любят предложения средней длины с идеальной грамматикой. Сознательное смешивание коротких, емких фрагментов с длинными сложными сложносочинёнными предложениями нарушает машинный отпечаток.
- Преднамеренное несовершенство: Отшлифованный текст вызывает подозрение. Запрос стиля «черновика» с коллоквиализмами или легкими неформальностями может обойти жесткие фильтры.
- Смешение стилей: Инструктируйте ИИ объединять конфликтующие тона, например, «формально-академический» с «разговорным блоговым», создавая уникальный гибридный голос.
Реализация этих техник не только помогает обходить детекторы, но и повышает качество контента. Когда мы смотрим на ожидания от инноваций GPT-4.5 и дальше, грань между инструментом и соавтором стирается. Цель не в обмане, а в обеспечении того, чтобы конечный продукт резонировал с человеческой аутентичностью.
Этические последствия ложных срабатываний в 2026 году
Зависимость от автоматизированных инструментов детекции порождает серьезные вопросы в области этики ИИ. Мы наблюдаем ситуации, когда студенты подвергаются дисциплинарным мерам, а сотрудники — пристальному вниманию на основе несовершенных вероятностных оценок. Ложное срабатывание — когда человеческая работа определяется как машинная — может повредить репутации и подорвать доверие. Это особенно актуально, учитывая, что не носители языка часто пишут с такой предсказуемой грамматической точностью, что детекторы воспринимают это как «ИИ».
Более того, давление для доказательства авторства меняет стиль письма. Парадоксально, люди начинают писать менее формально, чтобы избежать обвинений в использовании ИИ — явление, которое некоторые называют «обратным туринговским принуждением». Обеспечение аутентичности контента требует смены перспективы: инструменты должны использоваться для проверки, а не для преследования. В корпоративном секторе, когда компании исследуют соперничество между OpenAI и Anthropic, внимание смещается в сторону «происхождения» — отслеживания процесса создания документа, а не только анализа финального текста.
Понимание ограничений этих инструментов также важно для психического здоровья. Тревога, связанная с академической честностью в эпоху ИИ, существенна. Мы должны идти по пути ограничений и стратегий ChatGPT в 2025 году и дальше с уравновешенным подходом, гарантируя, что технологии служат нам, а не становятся чрезмерным контролем.

Смотря в будущее технологий 2025 и последующих лет, детектор вывода GPT-2 остается фундаментальным столпом. Он напоминает нам, что, несмотря на способность машин генерировать язык, понимание нюансов, намерений и источника этого языка остается сугубо человеческим императивом. Будь вы отлаживающим новое приложение LLM или просто сдающим эссе, знание механики этих детекторов дает вам возможность работать с ИИ прозрачно и эффективно.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Насколько надежен детектор вывода GPT-2 для современных моделей?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Хотя он установил стандарт ранней детекции, детектор вывода GPT-2 менее надежен для продвинутых моделей, таких как GPT-4 или GPT-5.0, без дополнительной настройки. Он лучше работает с текстами, схожими с архитектурой GPT-2, и может испытывать трудности с сильно очеловеченным или сильно отредактированным контентом новых LLM.”}},{“@type”:”Question”,”name”:”Почему детектор требует как минимум 50 токенов?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Базовая модель RoBERTa нуждается в достаточном объеме выборки для точного анализа статистических паттернов и распределений вероятностей. При меньше чем 50 токенах данных слишком мало, чтобы отличить человеческую непредсказуемость от машинной последовательности, что приводит к неубедительным результатам.”}},{“@type”:”Question”,”name”:”Может ли человеческое письмо быть помечено как сгенерированное ИИ?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Да, ложные срабатывания — серьезная проблема. Техническое письмо, не носители английского языка, использующие формальную грамматику, или сильно структурированные юридические тексты часто демонстрируют низкую “неопределённость”, которую детекторы ассоциируют с ИИ, в результате чего их ошибочно отмечают как машинные.”}},{“@type”:”Question”,”name”:”Возможно ли полностью обойти детекцию ИИ?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Можно значительно уменьшить вероятность детекции с помощью стратегии “очеловечивания”, такие как варьирование структуры предложений, добавление личных анекдотов и изменение словаря. Однако по мере развития алгоритмов детекции вместе с генеративными моделями ни один метод не гарантирует 100% обхода на постоянной основе.”}}]}Насколько надежен детектор вывода GPT-2 для современных моделей?
Хотя он установил стандарт ранней детекции, детектор вывода GPT-2 менее надежен для продвинутых моделей, таких как GPT-4 или GPT-5.0, без дополнительной настройки. Он лучше работает с текстами, схожими с архитектурой GPT-2, и может испытывать трудности с сильно очеловеченным или сильно отредактированным контентом новых LLM.
Почему детектор требует как минимум 50 токенов?
Базовая модель RoBERTa нуждается в достаточном объеме выборки для точного анализа статистических паттернов и распределений вероятностей. При меньше чем 50 токенах данных слишком мало, чтобы отличить человеческую непредсказуемость от машинной последовательности, что приводит к неубедительным результатам.
Может ли человеческое письмо быть помечено как сгенерированное ИИ?
Да, ложные срабатывания — серьезная проблема. Техническое письмо, не носители английского языка, использующие формальную грамматику, или сильно структурированные юридические тексты часто демонстрируют низкую “неопределённость”, которую детекторы ассоциируют с ИИ, в результате чего их ошибочно отмечают как машинные.
Возможно ли полностью обойти детекцию ИИ?
Можно значительно уменьшить вероятность детекции с помощью стратегии “очеловечивания”, такие как варьирование структуры предложений, добавление личных анекдотов и изменение словаря. Однако по мере развития алгоритмов детекции вместе с генеративными моделями ни один метод не гарантирует 100% обхода на постоянной основе.



откройте для себя самые захватывающие названия ракушек и их значения
Расшифровка скрытых данных морских архитектур Океан функционирует как огромный децентрализованный архив биологической истории. В этой безбрежной среде морские раковины —...


Funko pop новости: последние релизы и эксклюзивные дропы в 2025 году
Основные новости Funko Pop 2025 года и продолжающееся влияние в 2026 году Ландшафт коллекционирования кардинально изменился за последние двенадцать месяцев....


кто такой hans walters? раскрывая историю за именем в 2025 году
Загадка Ханса Уолтерса: анализ цифрового следа в 2026 году В необъятном пространстве доступной сегодня информации немногие идентификаторы показывают такую дихотомию,...


Изучение microsoft building 30: центр инноваций и технологий в 2025 году
Переосмысление рабочего пространства: в сердце технологической эволюции Редмонда Расположенное среди зелени обширного кампуса в Редмонде, Microsoft Building 30 представляет собой...


Лучшие инструменты ИИ для помощи с домашними заданиями в 2025 году
Эволюция ИИ поддержки студентов в современном классе Паника из-за дедлайна в воскресенье вечером постепенно становится пережитком прошлого. По мере того...


OpenAI vs Mistral: Какая модель ИИ лучше всего подойдет для ваших задач обработки естественного языка в 2025 году?
Пейзаж Искусственного Интеллекта кардинально изменился по мере нашего продвижения в 2026 году. Соперничество, определявшее предыдущий год — особенно столкновение между...


как сказать прощай: нежные способы справиться с прощаниями и окончаниями
Искусство нежного прощания в 2026 году Сказать прощай редко бывает просто. Независимо от того, меняете ли вы карьеру и переходите...


генератор названий пиратских кораблей: создайте имя своего легендарного судна сегодня
Создание идеальной идентичности для вашего морского приключения Назвать судно — это гораздо больше, чем просто приклеить ярлык; это акт определения...


Открывая креативность с diamond body AI prompts в 2025 году
Освоение методологии Diamond Body для точности ИИ В стремительно меняющемся мире 2025 года разница между обычным результатом и шедевром часто...


Что такое canvas? Всё, что нужно знать в 2025 году
Определение Canvas в современном цифровом предприятии В ландшафте 2026 года термин «Canvas» вышел за рамки единственного определения, представляя собой слияние...


как включить подсветку клавиатуры ноутбука: поэтапное руководство
Освоение подсветки клавиатуры: важное пошаговое руководство Печатать в тускло освещенной комнате, в ночном рейсе или во время поздней игровой сессии...


лучшие промпты для мокапов книг для midjourney в 2025 году
Оптимизация визуализации цифровых книг с Midjourney в пост-2025 эпоху Ландшафт визуализации цифровых книг кардинально изменился после алгоритмических обновлений 2025 года....


AI-Driven генераторы взрослого видео: основные инновации, на которые стоит обратить внимание в 2025 году
Рассвет синтетической интимности: переосмысление взрослого контента в 2026 году Ландшафт цифрового выражения претерпел колоссальные изменения, особенно в области производства Adult...


ChatGPT vs LLaMA: Какая языковая модель будет доминировать в 2025 году?
Колоссальная битва за превосходство в сфере ИИ: открытые экосистемы против закрытых платформ В быстро развивающемся ландшафте искусственного интеллекта выбор между...


Освоение начальных слов с ch: советы и задания для юных читателей
Расшифровка механизма начальных слов с CH в ранней грамотности Освоение языка у начинающих читателей работает удивительно похоже на сложную операционную...


Howmanyofme обзор: узнайте, насколько уникально ваше имя на самом деле
Раскрывая секреты вашей идентичности имени с помощью данных Ваше имя — это не просто ярлык в водительских правах; это краеугольный...


Понимание детектора вывода gpt-2: как он работает и почему это важно в 2025 году
Механика работы детектора вывода GPT-2 в эпоху генеративного ИИ В быстро меняющемся ландшафте 2026 года умение различать написанные человеком тексты...


Как интегрировать pirate weather с home assistant: полный пошаговый гид
Эволюция гиперлокальных погодных данных в экосистемах умного дома Надежность — краеугольный камень любой эффективной системы умного дома. В условиях 2026...


Полное руководство 2025 года по лучшим NSFW AI художникам: тренды и необходимые инструменты
Эволюция цифровой эротики и технологический сдвиг 2025 года Ландшафт Цифрового искусства претерпел огромные изменения, стремительно переместившись от статичных, созданных человеком...


OpenAI vs Meta: Исследование ключевых различий между ChatGPT и Llama 3 в 2025 году
Пейзаж ИИ в конце 2025 года: столкновение титанов Сектор искусственного интеллекта пережил сейсмический сдвиг после выхода Llama 4 от Meta...
-

 Open Ai5 days ago
Open Ai5 days agoGPT-4 Turbo 128k: Раскрывая инновации и преимущества 2025 года
-

 Инструменты1 week ago
Инструменты1 week agoОткройте лучшие инструменты для генерации имен гномов для уникальных фэнтезийных имен
-

 Open Ai6 days ago
Open Ai6 days agoОткрывая возможности плагинов ChatGPT: улучшите свой опыт в 2025 году
-

 Open Ai5 days ago
Open Ai5 days agoОсвоение тонкой настройки GPT: руководство по эффективной кастомизации ваших моделей в 2025 году
-

 Модели ИИ5 days ago
Модели ИИ5 days agoМодели GPT-4: Как искусственный интеллект преобразует 2025 год
-
 Open Ai6 days ago
Open Ai6 days agoСравнивая ChatGPT от OpenAI, Claude от Anthropic и Bard от Google: какой инструмент генеративного ИИ будет доминировать в 2025 году?