

Ai models
Understanding gpt-2 output detector: how it works and why it matters in 2025
The Mechanics Behind GPT-2 Output Detector in the Age of Generative AI
In the rapidly evolving landscape of 2026, the ability to distinguish between human-written narratives and machine-generated content has become a critical skill for educators, publishers, and developers alike. While we now navigate a world populated by advanced models, the foundational technology of the GPT-2 output detector remains a relevant case study in machine learning. Originally developed to identify text synthesized by the GPT-2 model, this tool utilizes a RoBERTa-based architecture to analyze linguistic patterns. It functions by calculating probability distributions, looking for the tell-tale mathematical signatures that often accompany artificial generation.
The core premise is straightforward yet sophisticated: the detector evaluates a sequence of text to predict the likelihood of it being “real” (human) or “fake” (machine). Unlike a human editor who looks for flow or creativity, the software scans for statistical predictability. When tracing the evolution of ChatGPT AI, we see that earlier models left distinct digital footprints. The detector requires a minimum input—typically around 50 tokens—to generate a reliable probability score. If the input is too short, the text analysis lacks sufficient data points to form a conclusive judgment, leading to unreliable results.

Comparing Detection Accuracy Across Generations
As we moved past the initial iterations of generative AI, the cat-and-mouse game between generation and detection intensified. Today, users often wonder how legacy detection methods stack up against giants like GPT-4, GPT-5.0, and Google’s Bard. The reality is nuanced. While the GPT-2 detector was state-of-the-art for its namesake, modern natural language processing has rendered some of its parameters less effective without fine-tuning. Newer Large Language Models (LLMs) are designed to mimic human unpredictability, making the job of older detectors significantly harder.
To understand the current ecosystem of model evaluation, it is helpful to look at how different tools perform against specific criteria. The following table breaks down the strengths and weaknesses of popular detection utilities used in professional and academic settings today:
| Detection Tool | Primary Use Case | Key Strengths 🔍 | Notable Weaknesses ⚠️ |
|---|---|---|---|
| GPT-2 Output Detector | Research & Developer Testing | High accuracy on older model signatures; open-source transparency. | Struggles with short texts (< 50 tokens) and highly prompted GPT-5 content. |
| JustDone AI Detector | Student & Academic Writing | Designed for academic tone; provides actionable feedback for humanization. | Can be overly sensitive to formal editing, flagging legitimate corrections. |
| Originality.AI | Web Publishing & SEO | robust against GPT-3.5 and Bard; tracks plagiarism alongside AI. | Aggressive detection can lead to false positives on heavily edited drafts. |
| GPTZero | Educational Institutions | Balanced scoring with lower false positive rates; detailed highlighting. | May flag complex, technical human writing as artificial due to structure. |
This data highlights a crucial trend: no single tool is infallible. For developers integrating these systems via automated ChatGPT API workflows, relying on a single metric can be risky. A multi-layered approach, combining probability scores with semantic analysis, offers the best defense against misclassification.
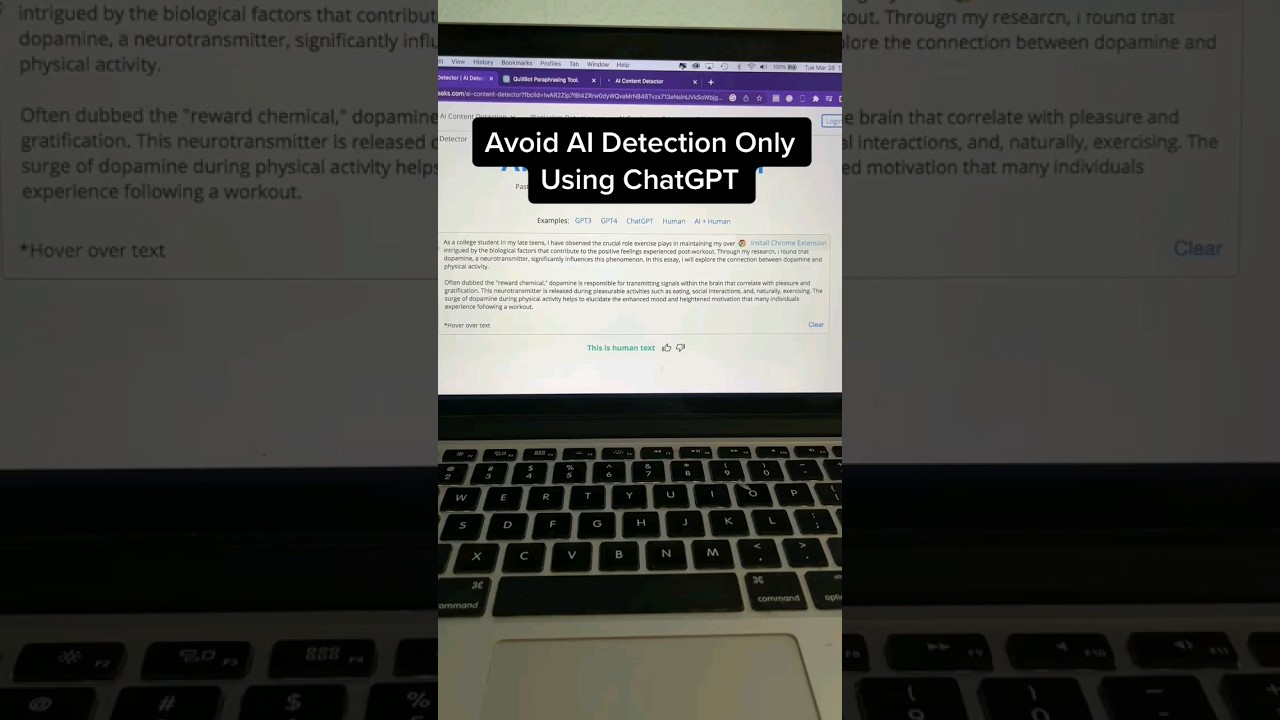
Bypassing Detection: The Art of Humanization
The rise of AI detection has naturally led to the development of counter-strategies. Whether for students trying to avoid unfair flagging or writers aiming to maintain a distinct voice, “humanizing” AI text is essential. The logic is simple: AI models predict the next word based on the highest probability, whereas humans are chaotic and creative. To bridge this gap, one must introduce variance—often referred to as “burstiness” and “perplexity” in technical terms.
Simply asking a model to “rewrite this” is rarely enough in 2026. Effective humanization requires strategic prompting that forces the model to break its own statistical patterns. Here are impactful strategies to refine AI-generated drafts:
- Inject Personal Context: AI lacks memory of personal life events. Adding first-person anecdotes or specific, localized references significantly lowers the “fake” probability score.
- Vary Sentence Structure: Machines love medium-length, grammatically perfect sentences. Deliberately mixing short, punchy fragments with long, complex compound sentences disrupts the machine signature.
- Intentional Imperfection: A polished text is suspicious. Requesting a “rough draft” style with colloquialisms or slight informalities can bypass rigid filters.
- Style Blending: Instruct the AI to combine conflicting tones, such as “formal academic” mixed with “conversational blog,” to create a unique hybrid voice.
Implementing these techniques does more than just bypass detectors; it improves the quality of the content. As we look at what innovations await in GPT-4.5 and beyond, the line between tool and collaborator blurs. The goal isn’t to deceive, but to ensure that the final output resonates with human authenticity.
Ethical Implications of False Positives in 2026
The reliance on automated detection tools brings forth significant questions regarding AI ethics. We are witnessing scenarios where students face disciplinary action and employees face scrutiny based on imperfect probability scores. A false positive—identifying human work as machine-generated—can damage reputations and erode trust. This is particularly concerning when we consider that non-native speakers often write with the predictable grammatical precision that detectors flag as “AI.”
Furthermore, the pressure to prove authorship is changing how we write. Paradoxically, humans are beginning to write less formally to avoid being accused of using AI, a phenomenon some call “reverse Turing coercion.” Ensuring content authenticity requires a shift in perspective: tools should be used to verify, not to prosecute. In the corporate sector, as companies explore the rivalry between OpenAI and Anthropic, the focus is shifting towards “provenance”—tracking the creation process of a document rather than analyzing the final text.
Understanding the limitations of these tools is also vital for mental well-being. The anxiety associated with academic integrity in the AI era is non-negligible. We must navigate these limitations and strategies for ChatGPT in 2025 and beyond with a balanced mindset, ensuring technology serves us rather than policing us unreasonably.

As we look toward future technology 2025 and the years following, the GPT-2 output detector stands as a foundational pillar. It reminds us that while machines can generate language, understanding the nuance, intent, and origin of that language remains a distinctly human imperative. Whether you are debugging a new LLM application or simply trying to submit an essay, recognizing the mechanics of these detectors empowers you to work alongside AI transparently and effectively.
How reliable is the GPT-2 Output Detector for modern models?
While it set the standard for early detection, the GPT-2 Output Detector is less reliable for advanced models like GPT-4 or GPT-5.0 without fine-tuning. It works best on text similar to GPT-2’s architecture and may struggle with highly humanized or heavily edited content from newer LLMs.
Why does the detector require at least 50 tokens?
The underlying RoBERTa model needs a sufficient sample size to analyze statistical patterns and probability distributions accurately. With fewer than 50 tokens, the data is too sparse to distinguish between human unpredictability and machine consistency, leading to inconclusive results.
Can human writing be flagged as AI-generated?
Yes, false positives are a significant issue. Technical writing, non-native English speakers using formal grammar, or highly structured legal text often exhibit the low ‘perplexity’ that detectors associate with AI, causing them to be incorrectly flagged as machine-generated.
Is it possible to completely bypass AI detection?
It is possible to significantly reduce the likelihood of detection by using ‘humanizing’ strategies such as varying sentence structure, injecting personal anecdotes, and altering vocabulary. However, as detection algorithms evolve alongside generative models, no method guarantees a 100% bypass rate indefinitely.
Max doesn’t just talk AI—he builds with it every day. His writing is calm, structured, and deeply strategic, focusing on how LLMs like GPT-5 are transforming product workflows, decision-making, and the future of work.



discover the most fascinating shell names and their meanings
Decoding the Hidden Data of Marine Architectures The ocean functions as a vast, decentralized archive of biological history. Within this...


Funko pop news: latest releases and exclusive drops in 2025
Major 2025 Funko Pop News and the Continuing Impact in 2026 The landscape of collecting changed drastically over the last...


who is hans walters? uncovering the story behind the name in 2025
The Enigma of Hans Walters: Analyzing the Digital Footprint in 2026 In the vast expanse of information available today, few...


Exploring microsoft building 30: a hub of innovation and technology in 2025
Redefining the Workspace: Inside the Heart of Redmond’s Tech Evolution Nestled within the greenery of the expansive Redmond campus, Microsoft...


Top AI Tools for Homework Assistance in 2025
The Evolution of Student Support AI in the Modern Classroom The panic of a Sunday night deadline is slowly becoming...


OpenAI vs Mistral: Which AI Model Will Best Suit Your Natural Language Processing Needs in 2025?
The landscape of Artificial Intelligence has shifted dramatically as we navigate through 2026. The rivalry that defined the previous year—specifically...


how to say goodbye: gentle ways to handle farewells and endings
Navigating the Art of a Gentle Farewell in 2026 Saying goodbye is rarely a simple task. Whether you are pivoting...


pirate ship name generator: create your legendary vessel’s name today
Designing the Perfect Identity for Your Maritime Adventure Naming a vessel is far more than a simple labeling exercise; it...


Unlocking creativity with diamond body AI prompts in 2025
Mastering the Diamond Body Framework for AI Precision In the rapidly evolving landscape of 2025, the difference between a generic...


What is canvas? Everything you need to know in 2025
Defining Canvas in the Modern Digital Enterprise In the landscape of 2026, the term “Canvas” has evolved beyond a singular...


how to turn on your laptop keyboard light: a step-by-step guide
Mastering Keyboard Illumination: The Essential Step-by-Step Guide Typing in a dimly lit room, on a night flight, or during a...


best book mockup prompts for midjourney in 2025
Optimizing Digital Book Visualization with Midjourney in the Post-2025 Era The landscape of digital book visualization shifted dramatically following the...


AI-Driven Adult Video Generators: The Top Innovations to Watch for in 2025
The Dawn of Synthetic Intimacy: Redefining Adult Content in 2026 The landscape of digital expression has undergone a seismic shift,...


ChatGPT vs LLaMA: Which Language Model Will Dominate in 2025?
The Colossal Battle for AI Supremacy: Open Ecosystems vs. Walled Gardens In the rapidly evolving landscape of artificial intelligence, the...


Mastering initial ch words: tips and activities for early readers
Decoding the Mechanism of Initial CH Words in Early Literacy Language acquisition in early readers functions remarkably like a complex...


Howmanyofme review: discover how unique your name really is
Unlocking the secrets of your name identity with data Your name is more than just a label on a driver’s...


Understanding gpt-2 output detector: how it works and why it matters in 2025
The Mechanics Behind GPT-2 Output Detector in the Age of Generative AI In the rapidly evolving landscape of 2026, the...


How to integrate pirate weather with home assistant: a complete step-by-step guide
The Evolution of Hyper-Local Weather Data in Smart Home Ecosystems Reliability is the cornerstone of any effective Smart Home setup....


2025’s Comprehensive Guide to Top NSFW AI Art Creators: Trends and Essential Tools
The Evolution of Digital Erotica and 2025’s Technological Shift The landscape of Digital Art has undergone a seismic shift, moving...


OpenAI vs Meta: Exploring the Key Differences Between ChatGPT and Llama 3 in 2025
The AI Landscape in Late 2025: A Clash of Titans The artificial intelligence sector has witnessed a seismic shift since...
-

 Tech1 month ago
Tech1 month agoYour card doesn’t support this type of purchase: what it means and how to solve it
-

 Open Ai2 months ago
Open Ai2 months agoMastering Your ChatGPT API Key: A Comprehensive Guide for 2025
-
 Tools2 months ago
Tools2 months agoHow to download and use open subtitles for movies and TV in 2025
-

 Actualités2 months ago
Actualités2 months agoOntario Man Claims ChatGPT Prompted Psychosis During ‘World-Saving’ Quest
-

 Ai models2 months ago
Ai models2 months agovietnamese models in 2025: new faces and rising stars to watch
-

 Actualités2 months ago
Actualités2 months agoUnlock the Power of ChatGPT Group Chat for Free: A Step-by-Step Guide to Getting Started