

Modelli di IA
Comprendere il rilevatore di output gpt-2: come funziona e perché è importante nel 2025
La Meccanica Dietro il Rilevatore di Output GPT-2 nell’Era dell’AI Generativa
Nel paesaggio in rapido sviluppo del 2026, la capacità di distinguere tra narrazioni scritte da umani e contenuti generati da macchine è diventata una competenza critica per educatori, editori e sviluppatori allo stesso modo. Mentre ora navighiamo in un mondo popolato da modelli avanzati, la tecnologia di base del rilevatore di output GPT-2 rimane uno studio di caso rilevante nel machine learning. Originariamente sviluppato per identificare testi sintetizzati dal modello GPT-2, questo strumento utilizza un’architettura basata su RoBERTa per analizzare i pattern linguistici. Funziona calcolando distribuzioni di probabilità, ricercando le distintive firme matematiche che spesso accompagnano la generazione artificiale.
Il principio fondamentale è semplice ma sofisticato: il rilevatore valuta una sequenza di testo per prevedere la probabilità che sia “reale” (umano) o “falso” (macchina). A differenza di un editor umano che cerca fluidità o creatività, il software analizza la prevedibilità statistica. Quando tracciamo l’evoluzione dell’AI ChatGPT, vediamo che i modelli precedenti lasciavano impronte digitali distintive. Il rilevatore richiede un input minimo – tipicamente intorno ai 50 token – per generare un punteggio di probabilità affidabile. Se l’input è troppo breve, l’analisi del testo manca di dati sufficienti per formare un giudizio conclusivo, portando a risultati inaffidabili.

Confronto sull’Accuratezza della Rilevazione tra Generazioni
Man mano che superavamo le iterazioni iniziali dell’AI generativa, il gioco del gatto e del topo tra generazione e rilevazione si è intensificato. Oggi, gli utenti spesso si chiedono come i metodi di rilevazione legacy si confrontino con giganti come GPT-4, GPT-5.0 e Bard di Google. La realtà è sfumata. Mentre il rilevatore GPT-2 era all’avanguardia per il suo omonimo, il moderno natural language processing ha reso alcuni dei suoi parametri meno efficaci senza un fine-tuning. I nuovi Large Language Models (LLM) sono progettati per imitare l’imprevedibilità umana, rendendo il lavoro dei vecchi rilevatori significativamente più difficile.
Per comprendere l’ecosistema attuale della valutazione dei modelli, è utile vedere come diversi strumenti si comportano rispetto a criteri specifici. La tabella seguente suddivide i punti di forza e le debolezze delle utilità di rilevazione più popolari utilizzate negli ambienti professionali e accademici oggi:
| Strumento di Rilevazione | Uso Primario | Punti di Forza 🔍 | Debolezze Notevoli ⚠️ |
|---|---|---|---|
| Rilevatore di Output GPT-2 | Ricerca & Test per Sviluppatori | Alta accuratezza sulle firme di modelli più vecchi; trasparenza open-source. | Fatica con testi brevi (< 50 token) e contenuti GPT-5 altamente promptati. |
| JustDone AI Detector | Scrittura Studentesca & Accademica | Progettato per tono accademico; fornisce feedback azionabili per umanizzazione. | Può essere eccessivamente sensibile alle revisioni formali, segnalando correzioni legittime. |
| Originality.AI | Pubblicazione Web & SEO | Robusto contro GPT-3.5 e Bard; monitora plagio insieme all’AI. | Rilevazione aggressiva può causare falsi positivi su bozze fortemente modificate. |
| GPTZero | Istituzioni Educative | Punteggi bilanciati con tassi di falsi positivi più bassi; evidenziazioni dettagliate. | Può segnalare scrittura umana complessa e tecnica come artificiale a causa della struttura. |
Questi dati evidenziano una tendenza cruciale: nessun singolo strumento è infallibile. Per gli sviluppatori che integrano questi sistemi tramite flussi di lavoro API ChatGPT automatici, affidarsi a un solo parametro può essere rischioso. Un approccio multilivello, che combina punteggi di probabilità con analisi semantica, offre la migliore difesa contro una classificazione errata.
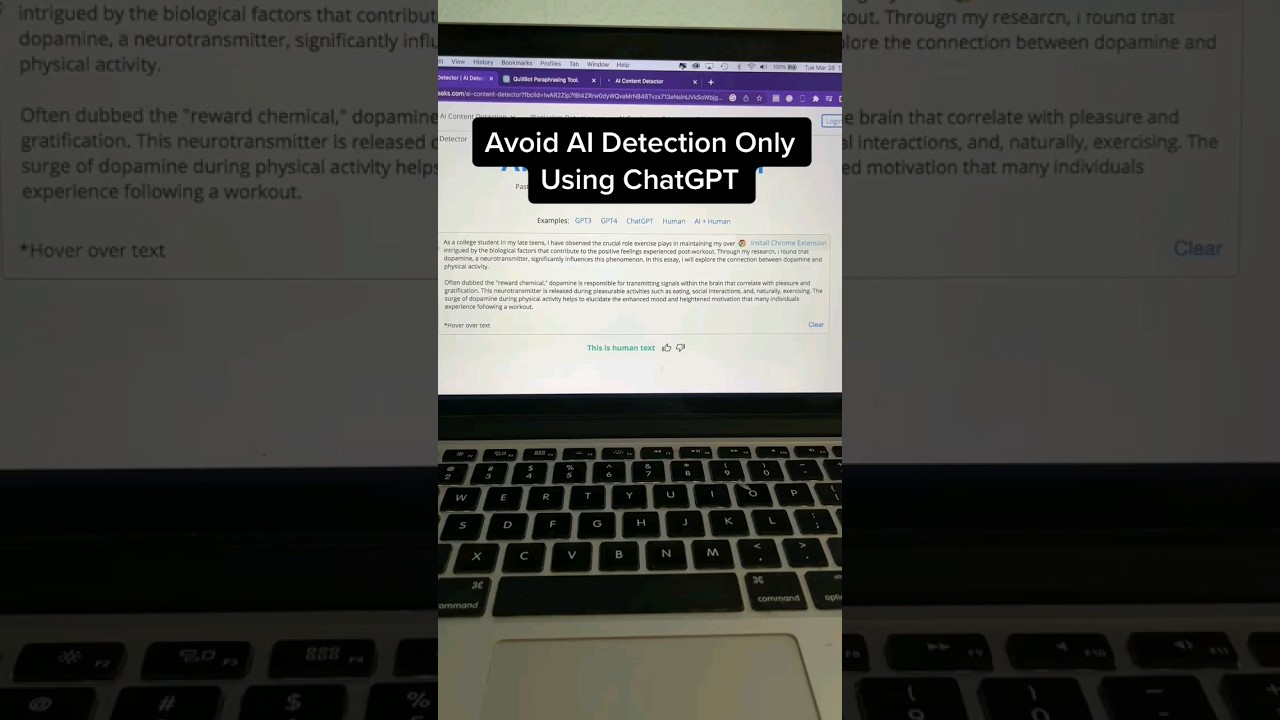
Eludere la Rilevazione: L’Arte dell’Umanizzazione
L’ascesa della rilevazione AI ha naturalmente portato allo sviluppo di contromisure. Che si tratti di studenti che cercano di evitare segnalazioni ingiuste o scrittori che mirano a mantenere una voce distinta, “umanizzare” il testo AI è essenziale. La logica è semplice: i modelli AI prevedono la parola successiva basandosi sulla massima probabilità, mentre gli umani sono caotici e creativi. Per colmare questo divario, si deve introdurre variabilità – spesso chiamata “burstiness” e “perplessità” in termini tecnici.
Semplicemente chiedere a un modello di “riscrivere questo” raramente è sufficiente nel 2026. Un’umanizzazione efficace richiede un prompting strategico che costringa il modello a rompere i propri schemi statistici. Ecco alcune strategie efficaci per migliorare le bozze generate dall’AI:
- Iniettare Contesto Personale: L’AI non ha memoria di eventi personali. Aggiungere aneddoti in prima persona o riferimenti specifici e localizzati abbassa significativamente il punteggio di probabilità “falso”.
- Variare la Struttura delle Frasi: Le macchine amano frasi di media lunghezza, grammaticalmente perfette. Mischiare deliberatamente frammenti brevi e incisivi con frasi lunghe e complesse interrompe la firma della macchina.
- Imperfezione Intenzionale: Un testo troppo rifinito è sospetto. Richiedere uno stile da “bozza grezza” con colloquialismi o lievi informalità può superare filtri rigidi.
- Misto di Stili: Istruire l’AI a combinare toni contrastanti, come “accademico formale” mescolato con “conversazionale da blog,” per creare una voce ibrida unica.
Implementare queste tecniche fa più che eludere i rilevatori; migliora la qualità del contenuto. Guardando a quali innovazioni attendono GPT-4.5 e oltre, il confine tra strumento e collaboratore si sfuma. L’obiettivo non è ingannare, ma assicurare che il prodotto finale risuoni con autenticità umana.
Implicazioni Etiche dei Falsi Positivi nel 2026
L’affidamento sugli strumenti di rilevazione automatizzata solleva importanti questioni riguardo all’etica AI. Stiamo assistendo a scenari in cui studenti affrontano azioni disciplinari e dipendenti subiscono scrutinio basati su punteggi di probabilità imperfetti. Un falso positivo – identificare un lavoro umano come generato da una macchina – può danneggiare reputazioni ed erodere la fiducia. Ciò è particolarmente preoccupante considerando che chi non è madrelingua spesso scrive con una precisione grammaticale prevedibile che i rilevatori segnalano come “AI”.
Inoltre, la pressione per dimostrare la paternità sta cambiando il modo in cui scriviamo. Paradossalmente, gli umani stanno iniziando a scrivere meno formalmente per evitare di essere accusati di usare l’AI, un fenomeno che alcuni chiamano “coercizione di Turing inversa.” Assicurare l’autenticità del contenuto richiede un cambio di prospettiva: gli strumenti dovrebbero essere usati per verificare, non per punire. Nel settore aziendale, mentre le aziende esplorano la rivalità tra OpenAI e Anthropic, l’attenzione si sposta verso la “provenienza” – tracciare il processo di creazione di un documento invece di analizzare il testo finale.
Comprendere i limiti di questi strumenti è anche vitale per il benessere mentale. L’ansia associata all’integrità accademica nell’era AI non è trascurabile. Dobbiamo affrontare queste limitazioni e strategie per ChatGPT nel 2025 e oltre con una mentalità equilibrata, assicurando che la tecnologia ci serva e non ci sorvegli in modo irragionevole.

Guardando al futuro della tecnologia 2025 e agli anni a venire, il rilevatore di output GPT-2 rimane un pilastro fondamentale. Ci ricorda che mentre le macchine possono generare linguaggio, comprendere la sfumatura, l’intento e l’origine di quel linguaggio rimane un imperativo distintamente umano. Che tu stia facendo il debug di una nuova applicazione LLM o semplicemente cercando di consegnare un saggio, riconoscere la meccanica di questi rilevatori ti permette di collaborare con l’AI in modo trasparente ed efficace.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Quanto è affidabile il Rilevatore di Output GPT-2 per modelli moderni?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Sebbene abbia stabilito lo standard per la rilevazione precoce, il Rilevatore di Output GPT-2 è meno affidabile per modelli avanzati come GPT-4 o GPT-5.0 senza un fine-tuning. Funziona meglio su testi simili all’architettura di GPT-2 e può avere difficoltà con contenuti altamente umanizzati o fortemente modificati provenienti da LLM più recenti.”}},{“@type”:”Question”,”name”:”Perché il rilevatore richiede almeno 50 token?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Il modello RoBERTa sottostante necessita di una dimensione del campione sufficiente per analizzare accuratamente i pattern statistici e le distribuzioni di probabilità. Con meno di 50 token, i dati sono troppo scarsi per distinguere tra imprevedibilità umana e coerenza macchina, portando a risultati inconcludenti.”}},{“@type”:”Question”,”name”:”La scrittura umana può essere segnalata come generata da AI?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Sì, i falsi positivi sono un problema significativo. La scrittura tecnica, chi non è madrelingua inglese che usa una grammatica formale o testi legali altamente strutturati spesso mostrano la bassa ‘perplessità’ che i rilevatori associano all’AI, causandone la segnalazione errata come generata da macchina.”}},{“@type”:”Question”,”name”:”È possibile eludere completamente la rilevazione AI?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”È possibile ridurre significativamente la probabilità di rilevazione usando strategie di ‘umanizzazione’ come variare la struttura delle frasi, iniettare aneddoti personali e modificare il vocabolario. Tuttavia, poiché gli algoritmi di rilevazione si evolvono insieme ai modelli generativi, nessun metodo garantisce un tasso di elusione del 100% indefinitamente.”}}]}Quanto è affidabile il Rilevatore di Output GPT-2 per modelli moderni?
Sebbene abbia stabilito lo standard per la rilevazione precoce, il Rilevatore di Output GPT-2 è meno affidabile per modelli avanzati come GPT-4 o GPT-5.0 senza un fine-tuning. Funziona meglio su testi simili all’architettura di GPT-2 e può avere difficoltà con contenuti altamente umanizzati o fortemente modificati provenienti da LLM più recenti.
Perché il rilevatore richiede almeno 50 token?
Il modello RoBERTa sottostante necessita di una dimensione del campione sufficiente per analizzare accuratamente i pattern statistici e le distribuzioni di probabilità. Con meno di 50 token, i dati sono troppo scarsi per distinguere tra imprevedibilità umana e coerenza macchina, portando a risultati inconcludenti.
La scrittura umana può essere segnalata come generata da AI?
Sì, i falsi positivi sono un problema significativo. La scrittura tecnica, chi non è madrelingua inglese che usa una grammatica formale o testi legali altamente strutturati spesso mostrano la bassa ‘perplessità’ che i rilevatori associano all’AI, causandone la segnalazione errata come generata da macchina.
È possibile eludere completamente la rilevazione AI?
È possibile ridurre significativamente la probabilità di rilevazione usando strategie di ‘umanizzazione’ come variare la struttura delle frasi, iniettare aneddoti personali e modificare il vocabolario. Tuttavia, poiché gli algoritmi di rilevazione si evolvono insieme ai modelli generativi, nessun metodo garantisce un tasso di elusione del 100% indefinitamente.



scopri i nomi di conchiglie più affascinanti e i loro significati
Decodificare i Dati Nascosti delle Architetture Marine L’oceano funziona come un vasto archivio decentralizzato di storia biologica. In questa vastità,...


Funko pop news: ultime uscite e drop esclusivi nel 2025
Le principali novità Funko Pop del 2025 e l’impatto continuo nel 2026 Il panorama del collezionismo è cambiato drasticamente negli...


chi è hans walters? scoprendo la storia dietro il nome nel 2025
L’enigma di Hans Walters: analisi dell’impronta digitale nel 2026 Nell’immensa quantità di informazioni disponibili oggi, pochi identificatori presentano una tale...


Esplorando microsoft building 30: un centro di innovazione e tecnologia nel 2025
Ridefinire lo Spazio di Lavoro: Nel Cuore dell’Evoluzione Tecnologica di Redmond Nascosto tra il verde del vasto campus di Redmond,...


I migliori strumenti di intelligenza artificiale per l’assistenza ai compiti nel 2025
L’evoluzione dell’AI per il supporto agli studenti nella classe moderna Il panico per la scadenza della domenica sera sta lentamente...


OpenAI vs Mistral: Quale modello di AI sarà il più adatto per le tue esigenze di elaborazione del linguaggio naturale nel 2025?
Il panorama dell’Intelligenza Artificiale è cambiato drasticamente mentre navighiamo attraverso il 2026. La rivalità che ha definito l’anno precedente—specificamente lo...


come dire addio: modi gentili per gestire i saluti e le conclusioni
Navigare nell’arte di un addio gentile nel 2026 Dire addio è raramente un compito semplice. Che tu stia cambiando carriera...


generatore di nomi per navi pirata: crea oggi il nome della tua leggendaria imbarcazione
Progettare l’Identità Perfetta per la Tua Avventura Marittima Chiamare un’imbarcazione è molto più di un semplice esercizio di etichettatura; è...


Sbloccare la creatività con i prompt diamond body AI nel 2025
Dominare il Framework Diamond Body per la Precisione dell’IA Nell’ambiente in rapida evoluzione del 2025, la differenza tra un output...


Che cos’è canvas? Tutto quello che devi sapere nel 2025
Definizione di Canvas nell’Impresa Digitale Moderna Nell’ambito del 2026, il termine “Canvas” è evoluto oltre una definizione singola, rappresentando una...


come accendere la luce della tastiera del tuo laptop: una guida passo passo
Dominare l’Illuminazione della Tastiera: La Guida Essenziale Passo Dopo Passo Digitare in una stanza poco illuminata, durante un volo notturno...


migliori prompt per mockup di libri per midjourney nel 2025
Ottimizzazione della Visualizzazione dei Libri Digitali con Midjourney nell’Era Post-2025 Il panorama della visualizzazione dei libri digitali è cambiato radicalmente...


Generatori di video per adulti guidati dall’IA: le principali innovazioni da tenere d’occhio nel 2025
L’alba dell’intimità sintetica: ridefinire i contenuti per adulti nel 2026 Il panorama dell’espressione digitale ha subito una trasformazione epocale, in...


ChatGPT vs LLaMA: Quale modello linguistico dominerà nel 2025?
La Battaglia Colossale per la Supremazia dell’IA: Ecosistemi Aperti vs. Giardini Recintati Nel panorama in rapida evoluzione dell’intelligenza artificiale, la...


Padroneggiare le parole iniziali con ch: consigli e attività per lettori alle prime armi
Decifrare il Meccanismo delle Parole Iniziali con CH nella Prima Alfabetizzazione L’acquisizione del linguaggio nei lettori emergenti funziona in modo...


Howmanyofme recensione: scopri quanto è davvero unico il tuo nome
Sbloccare i segreti della tua identità del nome con i dati Il tuo nome è più di una semplice etichetta...


Comprendere il rilevatore di output gpt-2: come funziona e perché è importante nel 2025
La Meccanica Dietro il Rilevatore di Output GPT-2 nell’Era dell’AI Generativa Nel paesaggio in rapido sviluppo del 2026, la capacità...


Come integrare pirate weather con home assistant: una guida completa passo dopo passo
L’evoluzione dei dati meteorologici iper-locali negli ecosistemi di Smart Home Affidabilità è la pietra angolare di qualsiasi configurazione Smart Home...


Guida Completa 2025 ai Migliori Creatori di Arte AI NSFW: Tendenze e Strumenti Essenziali
L’evoluzione dell’erotica digitale e il cambiamento tecnologico del 2025 Il panorama della Digital Art ha subito una svolta epocale, passando...


OpenAI vs Meta: Esplorando le Differenze Chiave Tra ChatGPT e Llama 3 nel 2025
Il panorama dell’IA a fine 2025: uno scontro tra titani Il settore dell’intelligenza artificiale ha subito un cambiamento epocale dalla...
-

 Open Ai6 days ago
Open Ai6 days agoSbloccare il Potere dei Plugin di ChatGPT: Migliora la Tua Esperienza nel 2025
-

 Open Ai5 days ago
Open Ai5 days agoPadroneggiare il Fine-Tuning di GPT: Una guida per personalizzare efficacemente i tuoi modelli nel 2025
-
 Open Ai6 days ago
Open Ai6 days agoConfronto tra ChatGPT di OpenAI, Claude di Anthropic e Bard di Google: quale strumento di IA generativa dominerà nel 2025?
-

 Open Ai5 days ago
Open Ai5 days agoTariffe di ChatGPT nel 2025: Tutto quello che devi sapere su prezzi e abbonamenti
-

 Open Ai6 days ago
Open Ai6 days agoLa Fase di Eliminazione dei Modelli GPT: Cosa Possono Aspettarsi gli Utenti nel 2025
-

 Modelli di IA5 days ago
Modelli di IA5 days agoModelli GPT-4: Come l’Intelligenza Artificiale sta Trasformando il 2025