

ఏఐ మోడల్స్
gpt-2 అవుట్పుట్ డిటెక్టర్ను అర్థం చేసుకోవడం: ఇది ఎలా పనిచేస్తుంది మరియు 2025లో ఇది ఎందుకు ముఖ్యంగా ఉంటుంది
సంయోజనాత్మక AI యుగంలో GPT-2 ఔట్పుట్ డిటెక్టర్ వెనుక ఉన్న యాంత్రికత
2026 యొక్క వేగంగా అభివృద్ధి చెందుతున్న పరిసరాల్లో, మానవుల ద్వారా రాయబడిన కథనాలు మరియు యంత్రాల ద్వారా రూపొందించిన కంటెంట్ మధ్య తేడా చెప్పడం విద్యార్థులు, ప్రచురణదారులు మరియు అభివృద్ధికర్తలకు అంతటా ఒక ముఖ్యమైన నైపుణ్యంగా మారింది. మనం ఇప్పుడు అధునాతన మోడళ్ళతో కూడిన ప్రపంచంలో నడుస్తున్నప్పటికీ, GPT-2 ఔట్పుట్ డిటెక్టర్ యొక్క ప్రాథమిక సాంకేతికత మిషన్ లెర్నింగ్ రంగంలో ఒక సంబంధిత అధ్యయనంగా నిలుస్తోంది. GPT-2 మోడల్ ద్వారా సింథసైజ్ అయిన వచనం గుర్తించడానికి మొదటగా అభివృద్ధి చేయబడిన ఈ టూల్ RoBERTa ఆధారిత నిర్మాణాన్ని ఉపయోగించి భాషా నమూనాలను విశ్లేషిస్తుంది. ఇది సాంఖ్యిక పంపిణీలను గణించడం ద్వారా పని చేస్తుంది, తరచుగా ఆర్టిఫిషియల్ జనరేషన్ కు సహజమైన గణాంక గుర్తుల కోసం చూస్తుంది.
ప్రధాన భావన సులభమైనా సుదీర్ఘం: డిటెక్టర్ ఒక వచన శ్రేణిని “నిజమైన” (మానవ) లేదా “బతుకుగా లేని” (యంత్ర)గా ఉండే అవకాశాన్ని అంచనా వేస్తుంది. ప్రవాహం లేదా సృజనాత్మకత కోసం చూస్తూ ఉండే మానవ సంపాదకుడితో భిన్నంగా, సాఫ్ట్వేర్ గణాంకీయమైన అంచనాలకు స్కాన్ చేస్తుంది. ChatGPT AI యొక్క అభివృద్ధిని కొలిచేటప్పుడు, ముందరి మోడళ్ళు ప్రత్యేక డిజిటల్ గుర్తులను మిగిల్చినట్లు కన్పిస్తాయి. డిటెక్టర్ ఒక కనీస ఇన్పుట్—సాధారణంగా సుమారు 50 టోకెన్లు—తర్వాతే నమ్మదగిన సాంఖ్యిక స్కోర్ సృష్టిస్తుంది. ఇన్పుట్ చాలా తక్కువగా ఉంటే, వచనం విశ్లేషణకు సరిపడా డేటా పాయింట్లు లేనందున తేలికపాటి తీర్పు ఇవ్వలేక అవిశ్వసనీయ ఫలితాలకు దారి తీస్తుంది.

తరగతుల దృష్ట్యా గుర్తింపు ఖచ్చితత్వం పోలిక
మేము జనరేటివ్ AI యొక్క మొదటి సంస్కరణలను అতিক్రమించినప్పుడు, జనరేషన్ మరియు గుర్తింపు మధ్య మ్యాచింగ్ ఆట తీవ్రమైంది. ఈ రోజుల్లో, యూజర్లు భారీ మోడల్స్ అయిన GPT-4, GPT-5.0, Google యొక్క Bard వంటి వాటితో పూర్వగత గుర్తింపు విధానాలు ఎలా సరిపోతున్నాయో తెలుసుకోవాలన పెరుగుతున్నారు. వాస్తవం సున్నితంగా ఉంటుంది. GPT-2 డిటెక్టర్ తన సమకాలీనకాలంలో అతి ఉత్తమం అయినప్పటికీ, ఆధునిక ప్రाकृतिक భాషా ప్రాసెసింగ్ కొన్ని పరిమాణాలు సున్నితంగా పనిచేయనట్లు మారింది. తాజా LLMలు మానవ unpredictability ని అనుకరిస్తూ ఉంటాయి, దాంతో పాత కాలపు డిటెక్టర్ల పని చాలా కష్టం అవుతుంది.
ప్రస్తుత మోడల్ అంచనా పర్యావరణాన్ని అర్థం చేసుకోవడానికి, వివిధ టూల్స్ నిర్దిష్ట ప్రమాణాల మేరకు ఎలా పనిచేస్తున్నాయో చూడటం సహాయకరం. క్రింది పట్టిక ప్రొఫెషనల్ మరియు అకాడమిక్ పరిసరాల్లో ప్రాచుర్యం పొందిన గుర్తింపు ఉపకరణాల బలాలు మరియు బలహీనతలను పరిశీలిస్తుంది:
| గుర్తింపు టూల్ | మూల్య ఉపయోగం | ప్రధాన బలాలు 🔍 | ప్రత్యేక బలహీనతలు ⚠️ |
|---|---|---|---|
| GPT-2 Output Detector | గবেষణ & అభివృద్ధి పరీక్ష | పాత మోడల్ గుర్తులపై ఉన్నత ఖచ్చితత్వం; ఓపెన్-సోర్స్ పారదర్శకత. | చిన్న వచనాలకే (< 50 టోకెన్లు) మరియు అధిక ప్రమ్ప్ట్ చేసిన GPT-5 కంటెంట్ తో ఇబ్బంది. |
| JustDone AI Detector | విద్యార్థి & అకాడమిక్ రచన | అకాడమిక్ టోన్ కి అనుకూలంగా రూపకల్పన; మానవీకరణ కోసం చేయదగిన అభిప్రాయాలు ఇస్తుంది. | వెయాస్యంగా సున్నితంగా ఉండి, చట్టబద్ధమైన సవరణలను తప్పుగా గుర్తించే అవకాశం. |
| Originality.AI | వెబ్ ప్రచురణ & SEO | GPT-3.5 మరియు Bard కి బలమైనది; AI తో పాటు జోలిపడును కూడా ట్రాక్ చేస్తుంది. | దృఢమైన గుర్తింపు భారీగా సవరించిన డ్రాఫ్ట్లపై తప్పుగా సూచనలు ఇవ్వొచ్చు. |
| GPTZero | విద్యాసంస్థలు | తక్కువ తప్పుగా గుర్తింపు రేటుతో సమగ్రమైన స్కోరింగ్; వివరమైన హైలైటింగ్. | సంఘిఖిత, సాంకేతిక మానవ రచనను నిర్మాణం కారణంగా కృత్రిమంగా గుర్తించే అవకాశం. |
ఈ డేటా ఒక ముఖ్యమైన ధోరణిని ప్రదర్శిస్తుంది: ఏ ఒక్క ఉపకరణం కూడా తప్పు రహితం కాదు. ఆటోమేటెడ్ ChatGPT API పని ప్రవాహాలు ద్వారా ఈ సిస్టమ్లను చేరవేయడం చేస్తున్న అభివృద్ధికర్తలకు ఒకే ప్రమాణంపై ఆధారపెట్టడం ప్రమాదకరం. ఒక బహుళ-పొందు దృష్టికోణం, probability స్కోర్లు మరియుసెమాంటిక్ విశ్లేషణను కలిపి, తప్పు గుర్తింపులపై ఉత్తమ రక్షణను అందిస్తుంది.
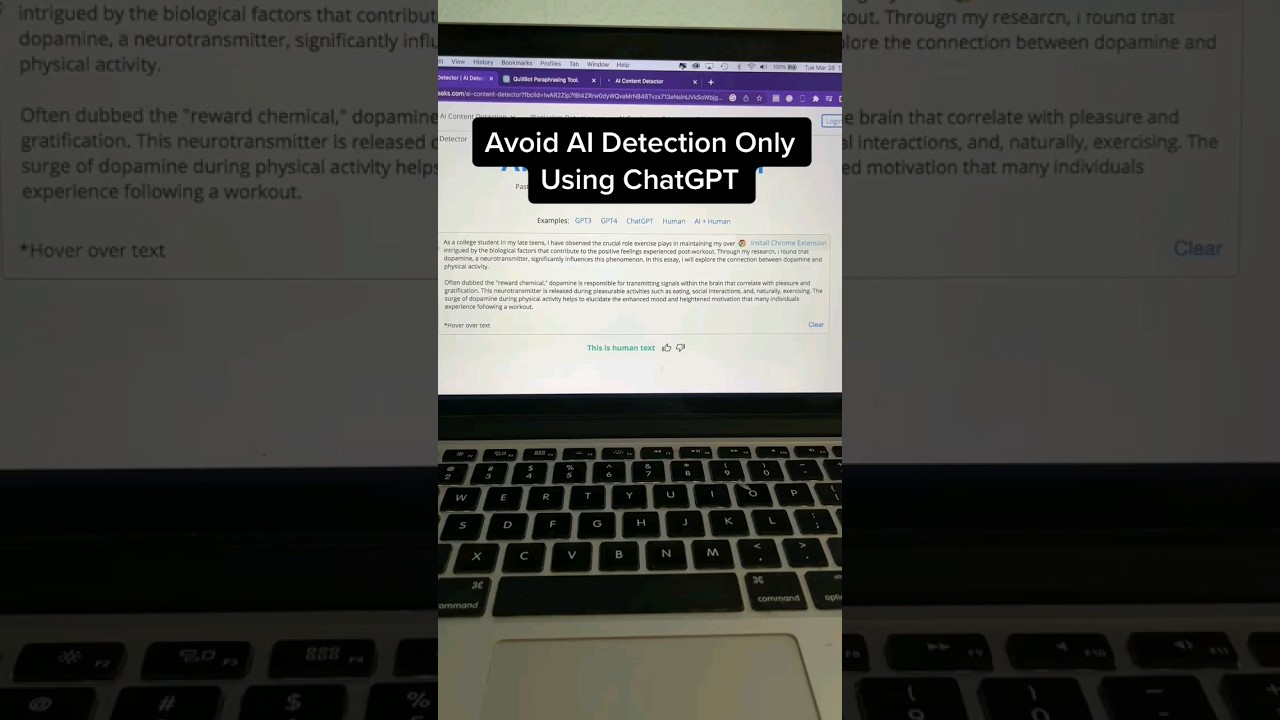
గుర్తింపును దాటి పోవడం: మానవీకరణ కళ
AI గుర్తింపు యొక్క పెరుగుదల సహజంగానే ప్రతికూల వ్యూహాల అభివృద్ధికి దారితీసింది. విద్యార్థులు అన్యాయంగా ఫ్లాగ్ అవ్వకుండా నిరోధించుకోవడానికి లేదా రచయితలు ప్రత్యేక స్వరాన్ని నిలుపుకోవడానికి ప్రయత్నించే సమయాల్లో, AI వచనాన్ని “మానవీకరించడం” అవసరం. లాజిక్ సాదాసీదా: AI మోడళ్ళు అత్యున్నత probability ఆధారంగా తదుపరి పదం అంచనా వేస్తాయి, అయితే మానవులు గందరగోళం మరియు సృజనాత్మకులు. ఈ ఖాళీని పూరించడానికి, తరచూ “బర్స్టినెస్” మరియు “పర్ప్లెక్సిటి” అనే సాంకేతిక పదాలతో పిలిచే వైవిధ్యాన్ని ప్రవేశపెట్టాలి.
2026లో “మర్రి రాయు”ని అడగడం మాత్రం చాలదు. సమర్థవంతమైన మానవీకరణకు, మోడల్ తన స్వంత గణాంక నమూనాలను పగిల్చే విధంగా వ్యూహాత్మక ప్రమ్ప్టింగ్ అవసరం. AI సృష్టించిన డ్రాఫ్ట్లను మెరుగుపరచడానికి క్రింద ప్రభావవంతమైన వ్యూహాలు ఉన్నాయి:
- వ్యక్తిగత నేపథ్యాన్ని చేర్చండి: AIకి వ్యక్తిగత జీవిత సంఘటనల జ్ఞాపకం లేదు. మొదటి వ్యక్తి అనుభవాలు లేదా నిర్దిష్ట, స్థానిక సూచనలు చేర్చటం “బతుకు కాదు” స్కోర్ను గణనీయంగా తగ్గిస్తుంది.
- వాక్య నిర్మాణాన్ని మార్చండి: యంత్రాలు మధ్యమ-పొడవాటి, వ్యాకరణపరంగా సూత్రమైన వాక్యాలను ఇష్టపడతాయి. సంక్లిష్టమైన పెద్ద వాక్యాలతో చిన్న కట్-షార్ట్ వాక్యాలను మిళితం చేయడం యంత్ర గుర్తింపును ధ్వంసం చేస్తుంది.
- సంకల్పిత అకుపూరీతత్వం: నుణుకుకున్న వచనం అనుమానాస్పదం. “రఫ్ డ్రాఫ్ట్” శైలిలో కొంత ఊరటతో, అప్రమాణమైన నిలుపు లేదా స్నేహపూర్వక గాథాలతో రాయమని అడగడం గట్టి పటులను దాటడానికి సహాయకరం.
- శైలి కలపడం: AIకి వ్యతిరేక స్వరాలను, ఉదాహరణకు “ఫార్మల్ అకాడమిక్” మరియు “కాన్వర్సేషనల్ బ్లాగ్” కలిపి ప్రత్యేక హైబ్రిడ్ స్వరాన్ని సృష్టించాలని బిప్రతి చెప్పండి.
ఈ సాంకేతికతలను అమలు చేయడం కేవలం డిటెక్టర్లని దాటిపోవడమే కాకుండా, కంటెంట్ నాణ్యతను కూడా మెరుగుపరుస్తుంది. GPT-4.5 మరియు తదుపరి ఇన్నోవేషన్లు ఏమిటో పరిశీలిస్తే, టూల్ మరియు సహకారಿಗಳ మధ్య రేఖ తేలికపడ్డది. లక్ష్యం మోసం చేయటం కాదు, కానీ తుది ఔట్పుట్ మానవ ప్రామాణికతతో ప్రతిధ్వనించేటట్లు చేయడమే.
2026లో తప్పు పాజిటివ్స్ యొక్క నైతిక పర్యవేక్షణ
ఆటోమేటెడ్ గుర్తింపు టూల్స్ మీద ఆధారపడటం AI నైతికతకి సంబంధించి ముఖ్యమైన ప్రశ్నలను తీసుకువస్తోంది. విద్యార్థులు శిక్షా చర్యలను ఎదుర్కొంటున్నారు, ఉద్యోగులు అప్రమత్తతకు గురవుతున్నారు—అభిప్రాయాల పరిపూర్ణతా స్కోర్ల ఆధారంగా. ఒక తప్పు పాజిటివ్—మానవ రచనను యంత్ర తయారైనదిగా గుర్తించడం—పేరుకు మింతమార్పు కలుగజేస్తుంది మరియు నమ్మకాన్ని దెబ్బతీస్తుంది. ఇది ముఖ్యంగా ఆందోళన కలిగిస్తుంది, ఎందుకంటే అంటు భాష మాట్లాడేవారు తరచుగా గణనీయమైన వ్యాకరణ సరళతతో వ్రాయటం వల్ల, డిటెక్టర్లు ఈ “AI” గా గుర్తించగలుగుతారు.
ఇంకా, రచయితత్వాన్ని నిరూపించుకోవాలని ఒత్తిడి మనం ఎలా రాస్తామో మార్చేస్తోంది. వ్యతిరేకంగా, “రివర్స్ టూరింగ్ కూసేషన్” గా పిలవబడే ఒక ఫినోమెనాన్ ప్రకారం, మానవులు AI ఉపయోగించారని ఆరోపణలు రాకుండా తక్కువ అధికారికంగా వ్రాయడం మొదలెట్టారు. కంటెంట్ ఆథెంటిసిటీని నిర్ధారించటం కోసం, పరికరాలు శిక్షించడానికి కాదు, పరిశీలించడానికి ఉపయోగించాలి అనే మనోభావంలో మార్పు అవసరం. కార్పొరేట్ రంగంలో, సంస్థలు OpenAI మరియు Anthropic మధ్య పోటీని పరిశీలిస్తున్నప్పుడు, దృష్టి “ప్రొవెనెన్స్” వైపు మారుుతోంది—తుది వచనం కాకుండా ఒక డాక్యుమెంట్ సృష్టి ప్రక్రియ ట్రాక్ చేయడం.
ఈ పరికరాల పరిమితులను అర్థం చేసుకోవడం మానసిక ఆరోగ్యానికి కూడా అవసరం. AI యుగంలో అకాడమిక్ నిజాయతీకి సంబంధించిన ఆందోళన తక్కువగా లేదు. మేము 2025 లో ChatGPTకి సంబంధించిన పరిమితులు మరియు వ్యూహాలను సమతౌల్యమైన మనస్తత్వంతో నడపాలి, సాంకేతికత మమ్మల్ని సర్వే చేయకుండా, సేవ చేసేందుకు ఉండాలి.

భవిష్యత్ సాంకేతికత 2025 మరియు తరువాతి సంవత్సరాల వైపు చూస్తే, GPT-2 ఔట్పుట్ డిటెక్టర్ ఒక ప్రాథమిక స్తంభంగా నిలుస్తుంది. ఇది యంత్రాలు భాషను సృష్టించగలిగినా, ఆ భాష యొక్క సూత్రం, ఉద్దేశం, మరియు మూలం అర్థం చేసుకోవడం పూర్తిగా మానవ బాధ్యతగా ఉంటుందని గుర్తుచేస్తుంది. మీరు ఒక కొత్త LLM అప్లికేషన్ డిఫిగ్గింగ్ చేస్తున్నారా లేక ఒక వ్యాసం సమర్పించేందుకు ప్రయత్నిస్తున్నారా, ఈ డిటెక్టర్ల యాంత్రికతలు తెలుసుకోవడం AI తో పారదర్శకంగా మరియు సమర్థవంతంగా పని చేయడానికి మీకు శక్తివంతమైన సాధనం అందిస్తుంది.
ఆధునిక మోడళ్ళ కోసం GPT-2 ఔట్పుట్ డిటెక్టర్ ఎంత నమ్మదగినది?
ముందస్తు గుర్తింపు కోసం ఇది ప్రమాణంగా నిలిచినప్పటికీ, GPT-2 ఔట్పుట్ డిటెక్టర్ GPT-4 లేదా GPT-5.0 వంటి ఆధునిక మోడళ్ళకు ఫైన్-ట్యూనింగ్ లేకుండా తక్కువ నమ్మకమైనది. ఇది GPT-2 నిర్మాణానికి సమానమైన వచనంపై ఉత్తమంగా పనిచేస్తుంది మరియు అధికంగా మానవీకరించబడిన లేదా మిగిలిన LLMల నుంచి భారీగా సవరించబడిన కంటెంట్తో ఇబ్బంది పడుతుంది.
డిటెక్టర్ కనీసం 50 టోకెన్లు ఎందుకు అవసరం?
ఆధారమైన RoBERTa మోడల్ గణాంక నమూనాలను మరియు probability పంపిణీలను ఖచ్చితంగా విశ్లేషించేందుకు తగిన సరిపడా నమూనా పరిమాణం అవసరం. 50 టోకెన్ల కంటే తక్కువ అయితే, డేటా చాలా అరుదుగా ఉంటుంది, మానవ వ్యవధి గల అనిశ్చితత్వం మరియు యంత్రం స్థిరత్వం మధ్య స్పష్టమైన తేడాను గుర్తించలేడు, దల్లే తేలికపాటి ఫలితాలు వస్తాయి.
మానవరచనను AI-సృష్టిగా పొరుగుగా గుర్తించవచ్చా?
అవును, తప్పు పాజిటివ్స్ పెద్ద సమస్య. సాంకేతిక రచన, అనుపస్థితి ఇంగ్లీష్ స్పీకర్లు ఉపయోగించే అధికారిక వ్యాకరణం, లేదా అధికంగా నిర్మితమైన చట్టపరమైన వచనం తరచుగా డిటెక్టర్లు AI గా గుర్తించే తక్కువ ‘పర్ప్లెక్సిటీ’ను ప్రదర్శిస్తాయి, వాటిని తప్పుగా యంత్ర ఉత్పత్తిగా గుర్తించవచ్చు.
AI గుర్తింపును పూర్తిగా దాటిపోవడం సాధ్యమేనా?
వాక్య నిర్మాణాన్ని మార్చడం, వ్యక్తిగత కథనాలను చేర్పించడం, పదకోశాన్ని మార్పు చేసుకోవడం వంటి ‘మానవీకరణ’ వ్యూహాలను ఉపయోగించి గుర్తింపు అవకాశాన్ని గణనీయంగా తగ్గించడం సాధ్యం. కానీ, జనరేటివ్ మోడళ్ళతో పాటు గుర్తింపు అల్గోరిథమ్లు అభివృద్ధి చెందుతుండడంతో, 100% గుర్తింపు దాటిపోవడం ఎప్పటికీ హామీ ఇవ్వలేం.



అత్యంత ఆహ్లాదకరమైన షెల్ పేర్లు మరియు వాటి అర్థాలను వెతకండి
సముద్ర వాస్తుకళల దాగున్న డేటాను డీకోడ్ చేయడం సముద్రం జీవ శ్రేణుల చరిత్ర యొక్క విస్తారమైన, వికేంద్రీకృత ఆర్కైవ్గా పనిచేస్తుంది. ఈ విస్తీర్ణంలో, సముద్ర శంఖాలు కేవలం...


Funko pop వార్తలు: 2025 లో పెట్టుబడులు మరియు ప్రత్యేక డ్రాప్స్
2025 ముఖ్యమైన Funko Pop వార్తలు మరియు 2026లో కొనసాగుతున్న ప్రభావం సేకరణ రంగం గత పన్నెండు నెలల్లో గణనీయంగా మారింది. మనం 2026కి అడుగుపెడుతున్నప్పుడల్లా, Funko...


హాన్స్ వాల్టర్స్ ఎవరు? 2025లో పేరుకు వెనుక కథను ఆవిష్కరించడం
హాన్స్ వాటిలర్స్ యొక్క మిస్టరీ: 2026లో డిజిటల్ ఫుట్ప్రింట్ విశ్లేషణ ఇప్పటి విస్తృత సమాచారం సముద్రంలో, హాన్స్ వాటిలర్స్ అనే పేరు ఇలాగే రెండు విభిన్నతలను కలిగిన...


మైక్రోసాఫ్ట్ బిల్డింగ్ 30ని అన్వేషించడం: 2025లో వారి ఆవిష్కరణ మరియు సాంకేతికత హబ్
వర్క్స్పేస్ను పునঃనిర్వచించడం: రెడ్మండ్ టెక్నాలజీ అభివృద్ధి హృదయంలో లోతుగా విస్తారమైన రెడ్మండ్ క్యాంపస్లోని ఆకులతో నిండిన ప్రదేశంలో, Microsoft Building 30 కార్పొరేట్ ఆర్కిటెక్చర్లో ఒక పరస్పర...


2025 లో హోమ్వర్క్ సహాయానికి టాప్ AI టూల్స్
<h2 ఆధునిక తరగతి గదిలో విద్యార్థి మద్దతు AI అభివృద్ధి ఒక ఆదివారం రాత్రి సమయసীমా కోసం ఆందోళన పాతికాలపు విషయం అవుతుంది. 2025 అకాడమిక్ పరిసరాలలోకి...


OpenAI vs Mistral: 2025లో మీ సహజ భాషా ప్రాసెసింగ్ అవసరాలకు ఏ AI మోడల్ ఉత్తమంగా సరిపోతుంది?
2026లో మనం సాగుతున్న క్రమంలో కృత్రిమ బుద్ధి పరిమాణంలో భారీ మార్పు వచ్చింది. గత సంవత్సరం నిర్వచించిన పెట్టుబడి—అందులోని స్థిరమైన అధికారం గల దిగ్గజులు మరియు చురుకైన...


వీడ్కోలు చెప్పడం ఎట్లా: మనసుకు సాంత్వనివ్వే వీడ్కోలు మరియు ముగింపులు నిర్వహించే సహజమైన మార్లు
2026లో సున్నితమైన వీడ్కోలు కళను నావిగేట్ చేయడం వీడ్కోలు చెప్పడం అరుదుగా సులభమైన పనిగా ఉంటుంది. మీరు టెక్ రంగంలో కొత్త కెరీర్ వైపు మారుతుండగా, ఒక...


దొంగ ఓడ పేరు జనరేటర్: మీ లెజెండరీ నావుకు పేరు ఈ రోజు సృష్టించండి
మీ సముద్ర సాహసానికి పరిపూర్ణ గుర్తింపును రూపకల్పన చేయడం ఒక నౌకను పేరు పెట్టడం ఒక సరళమైన లేబెలింగ్ వ్యాయామం మాత్రమే కాదు; ఇది తెరుచుకున్న సముద్రంపై...


2025లో డైమండ్ బాడీ AI ప్రాంప్ట్లతో సృజనాత్మకతను అన్లాక్ చేయడం
AI నిష్ణాతత్వానికి డైమండ్ బాడీ ఫ్రేమ్వర్క్ పూర్ణం చేయడం 2025 యొక్క వేగంగా మారుతున్న పరిస్తితిలో, సాధారణ అవుట్పుట్ మరియు అద్భుత కృషి మధ్య వ్యత్యాసం తరచుగా...


కేన్వాస్ అంటే ఏంటి? 2025లో తెలుసుకోవాల్సిన అన్ని విషయాలు
ఆధునిక డిజిటల్ సంస్థలో క్యాన్వాస్ నిర్వచనం 2026 పరిసరాలలో, “క్యాన్వాస్” అనే పదం ఒకే నిర్వచనాన్ని దాటి, డేటా విజువలైజేషన్, విద్యా సాంకేతికత మరియు సృజనాత్మక ఇంటర్ఫేస్ల...


ల్యాప్టాప్ కీబోర్డ్ లైట్ను ఎలా ఆన్ చేయాలి: ఒక దశల వారీ గైడ్
కీబోర్డ్ ఇల్యూమినేషన్లో నైపుణ్యం సంపాదించడం: అవసరమైన అడుగు-దశ మార్గదర్శకము మందయోగ్యంగా వెలిగే గదిలో, రాత్రి విమానంలో, లేదా రాత్రి గేమింగ్ సెషన్ సమయంలో టైపింగ్ చేయడం కేవలం...


మిడ్జర్నీ కోసం 2025లో ఉత్తమ పుస్తకం మాక్అప్ ప్రాంప్ట్స్
పోస్ట్-2025 యుగంలో మెడ్జర్నీతో డిజిటల్ పుస్తక విజువలైజేషన్ 최적화 2025 అప్డేట్ల తర్వాత డిజిటల్ పుస్తక విజువలైజేషన్ పటమం దృశ్యం అత్యంత మారిందని చెప్పవచ్చు. రచయితలు, మార్కెటర్లు,...


AI-చालित వయస్క వీడియో జనరేటర్లు: 2025లో గమనించవలసిన ప్రధాన ఆవిష్కరణలు
సింథటిక్ ఇంటిమసి యొక్క ఉదయం: 2026 లో వయోజన కంటెంట్ పునర్నిర్మాణం డిజిటల్ వ్యక్తీకరణ పరిపాటిలో విప్లవాత్మక మార్పు సంభవించింది, ముఖ్యంగా వయోజన వీడియో ఉత్పత్తి ক্ষেত্রে....


ChatGPT vs LLaMA: 2025లో ఏ భాషా మోడల్ ఆధిపత్యం ఏర్పాటు చేసుకుంటుంది?
ఏఐ ఆధిపత్యానికి భారీ పోరాటం: ఓపెన్ ఎకోసిస్టమ్స్ మరియు వాల్డ్ గార్డెన్స్ త్వరగా మారుతున్న కృత్రిమ మేధస్సు ప్రదేశంలో, మెటా యొక్క LLaMA మరియు OpenAI యొక్క...


మాస్టరింగ్ ప్రారంభ ch పదాలు: ప్రారంభ పాఠకుల కోసం చిట్కాలు మరియు కార్యకలాపాలు
ప్రారంభ CH పదాల యంత్రాంగాన్ని ప్రారంభ సాహిత్యంలో డీకోడ్ చేయడం ప్రారంభ పాఠకులు లో భాషా అభివృద్ధి అనేది ఒక క్లిష్టమైన ఆపరేటింగ్ సిస్టమ్లాగా పనిచేస్తుంది: ఇది...


Howmanyofme సమీక్ష: మీ పేరు ఎంత ప్రత్యేకమైందో కనుగొనండి
డేటాతో మీ పేరు గుర్తింపులోని రహస్యాలను వెలికితీయడం మీ పేరు డ్రైవర్ లైసెన్స్పై లేబుల్ కంటే ఎక్కువ; ఇది మీ బ్రాండ్ యొక్క మూలస్తంభం మరియు మీ...


gpt-2 అవుట్పుట్ డిటెక్టర్ను అర్థం చేసుకోవడం: ఇది ఎలా పనిచేస్తుంది మరియు 2025లో ఇది ఎందుకు ముఖ్యంగా ఉంటుంది
సంయోజనాత్మక AI యుగంలో GPT-2 ఔట్పుట్ డిటెక్టర్ వెనుక ఉన్న యాంత్రికత 2026 యొక్క వేగంగా అభివృద్ధి చెందుతున్న పరిసరాల్లో, మానవుల ద్వారా రాయబడిన కథనాలు మరియు...


pirate weather ను home assistant తో ఏలా కలపాలి: పూర్తి స్థాయి దశల వారీ గైడ్
స్మార్ట్హోమ్ వ్యవస్థలలో హైపర్-స్థానిక వాతావరణ డేటా అభివృద్ధి విశ్వసనీయత అనేది ఏదైనా సమర్థవంతమైన స్మార్ట్హోమ్ సెటప్ప్ యొక్క మూలస్తంభం. 2026 పరిసరాలలో, క్లౌడ్ సేవలపై ఆధారపడి ఉండటం...


2025 యొక్క టాప్ NSFW AI ఆర్ట్ క్రియేటర్ల సమగ్ర మార్గదర్శకం: ప్రవర్తనలు మరియు అవసరమైన సాధనలు
డిజిటల్ ఎరోటికా పరిణామం మరియు 2025 యొక్క సాంకేతిక మార్పు డిజిటల్ ఆర్ట్ పరిశ్రమ పెనే విప్లవాత్మక మార్పు సాధించింది, స్థిరంగానున్న, మానవుల చేత డ్రాయింగ్ చేసిన...


OpenAI vs Meta: 2025 లో ChatGPT మరియు Llama 3 మధ్య ప్రధాన భేదాలను పరిశీలించడం
లేట్ 2025లో AI వాతావరణం: దిగ్గజాల మధ్య పోరు ఆర్టిఫిషియల్ ఇంటెలిజెన్స్ రంగం 2025 ఏప్రిల్లో Meta’s Llama 4 విడుదల తర్వాత భారీ మార్పులు చూసింది....
-

 Open Ai6 days ago
Open Ai6 days agoChatGPT ప్లగఇన్ల శక్తిని అన్లాక్ చేయండి: 2025 లో మీ అనుభవాన్ని మెరుగుపరచండి
-

 Open Ai5 days ago
Open Ai5 days agoGPT ఫైన్-ట్యూనింగ్లో నైపుణ్యం సాధించడం: 2025లో మీ మోడల్స్ను సమర్థవంతంగా కస్టమైజ్ చేయడానికి మార్గదర్శకం
-

 ఏఐ మోడల్స్5 days ago
ఏఐ మోడల్స్5 days agoGPT-4 మోడల్స్: ఆర్టిఫిషియల్ ఇంటెలిజెన్స్ 2025 లో ఎలా మారుస్తోంది
-
 Open Ai6 days ago
Open Ai6 days agoOpenAI యొక్క ChatGPT, Anthropic యొక్క Claude, మరియు Google యొక్క Bard ను పోల్చడం: 2025 లో ఏ జనరేటివ్ AI టూల్ అగ్రగామి అవుతుంది?
-

 Open Ai5 days ago
Open Ai5 days agoChatGPT 2025లో ధరలు: రేట్లు మరియు సబ్స్క్రిప్షన్ల గురించి మీరు తెలుసుకోవాల్సిన అన్ని విషయాలు
-

 Open Ai6 days ago
Open Ai6 days agoGPT మోడళ్ల దశ వికాసం ముగింపు: 2025లో వినియోగదారులు ఎం ఆశించవచ్చు