

సాంకేతికత
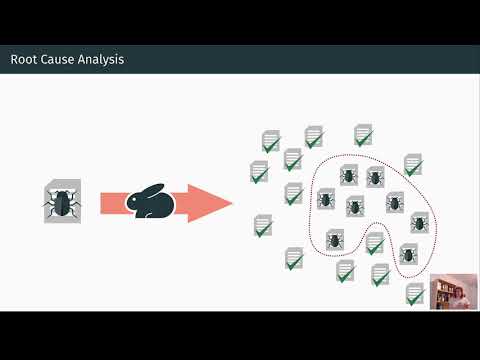
టాస్క్ విఫలమయ్యె యొక్క మూల కారణాలను ఉత్స్పోతనం: PSU మరియు డ్యూక్ పరిశోధకుల నుండి బహుళ ఏజెంట్ వ్యవస్థలలో ఆటోమేటెడ్ విఫలం కారణ నిర్ధారణపై అవగాహనలు
PSU మరియు Duke పరిశోధకులు, Google DeepMind మరియు ఇతర సహకర్తలతో కలిసి, Multi-Agent అభివృద్ధిలో ఒక శాశ్వత సమస్యను తిరగరాసుతున్నారు: దీర్ఘకాలం, జతచేసిన లాగ్లలో మూల కారణాన్ని ట్రేస్ చేయడం. వారి ICML 2025 స్పాట్లైట్ పని స్వయంచాలక అట్రిబ్యూషన్ను ప్రతిపాదిస్తుంది—ఏ ఏజెంట్ విఫలమైందో ఎప్పుడు అని గుర్తించేందుకు ఒక కఠినమైన పద్ధతి—కొత్త ఓపెన్ డేటా సెట్ మరియు బేస్లైన్ పద్ధతులతో సమర్థించబడింది. లక్ష్యం సులభం: అపారదర్శక విఫలతలను నిర్మితమైన సిస్టమ్ డయాగ్నోస్టిక్స్గా మార్చడం, ఇది పునరావృతిని వేగవంతం చేస్తుంది.
| వేగంగా కావాలా? ఇది ముఖ్యం: ⚡ | |
|---|---|
| • 🔎 కొత్త పని: LLM Multi-Agent వర్క్ఫ్లోలకు స్వయంచాలక విఫలత అట్రిబ్యూషన్. | • 🧭 బెన్చ్మార్క్: Who&When డేటాసెట్ లో Who, When, Why లేబుల్స్. |
| • 📉 సవాలు: ఉత్తమ ఏకైక పద్ధతి “Who”పై సుమారు ~53.5% మరియు “When”పై ~14.2% సాధిస్తుంది. | • 🧰 సారాంశం: మిశ్రమ, కారణపరమైన ప్రాంప్ట్లు మరియు జాగ్రత్తగా కాంటెక్స్ట్ నియంత్రణ అత్యుత్తమం. |
బహుళ ఏజెంట్ సిస్టమ్లలో స్వయంచాలక విఫలత అట్రిబ్యూషన్: మూల కారణ విశ్లేషణ ఎందుకు ముఖ్యం
బహుళ ఏజెంట్ పైప్లైన్లు సహకారాన్ని హామీ ఇస్తాయి, కానీ వాస్తవంలో ఏజెంట్ సందేశాల ధుమ్మర వేళ చాలా ముఖ్యమైన తప్పులను తప్పిస్తుంది. అభివృద్ధి దారులు తరచుగా agentలు ప్రణాళికలు ప్రతిపాదించి, ఒకరినొకరు విమర్శించి, టూల్స్ పిలచే పొడవాటి ట్రేస్లను ఎదుర్కొంటారు, అయినా తుది ఫలితం లక్ష్యాన్ని దాటదు. నిర్మిత మూల కారణ విశ్లేషణ లేకుండా, “ఏదైనా తప్పు జరిగిందా, ఎవరూ కారణం, ఎప్పుడు” శబ్దంలో మునిగిపోతుంది. PSU మరియు Duke ఈ కోల్పోయిన లంకెను AI పరిశోధనలో అధికారికముగా రూపొందించడానికి బయలుదేరి, బహుళ ఏజెంట్ ఇంటెలిజెంట్ సిస్టమ్లకు స్వయంచాలక అట్రిబ్యూషన్ని పేరు మరియు పరిమితి కేటాయించాయి.
అధిభావన ముఖ్యం ఎందుకంటే ఇది సులభం. మానవ “లాగ్ ఆయుర్కెలజీ” ద్వారా డీబ్ ఆధ్వర్యంలో డీబగ్గింగ్ గంటల నుంచి గంటలు పడుతుంది మరియు బృందాలు ఎక్కువ ఏజెంట్లతో, ఎక్కువ కాంటెక్స్ట్లతో, టూల్-భారీ వర్క్ఫ్లోలతో ప్రయోగించే కొద్దీ ఇది నాన్ని తగ్గుతుంది. ఒక సూత్రీకృత అట్రిబ్యూషన్ లేయర్ గుణాత్మక విమర్శను కొలతగల సిస్టమ్ డయాగ్నోస్టిక్స్గా మార్చుతుంది. ఈ మార్పు సంఘటన ప్రతిస్పందన నుంచి మోడల్ పాలన వరకు ప్రతీ విషయాన్ని ప్రభావితం చేస్తూ, వాస్తవ సంస్థల్లో ఉపయోగించే మెషీన్ లెర్నింగ్ సిస్టమ్ల విశ్వసనీయతను మెరుగుపరుస్తుంది.
“NovaAI”ని ఒక కల్పిత స్టార్టప్గా పరిగణించండి, స్వయం నడిచే కోడింగ్ క్రూ సృష్టిస్తోంది. ఒక ఉత్పత్తి ఏజెంట్ స్పెక్స్ సేకరిస్తుంది, ప్లానర్ పనులను విడగొడుతాడు, కోడర్ ప్యాచ్లను రాస్తాడు, టెస్టర్ CI నిర్వహిస్తాడు. ఒక విడుదల విఫలమవుతుంది ఎందుకంటే కోడర్ ఒక API మార్పును తప్పుగా అర్థం చేసుకున్నాడు, ఇది ప్లానర్ ముందుగా సూచించాడు. అట్రిబ్యూషన్ లేకుండా, బృందం ఉపసంహరణలను పరీక్షిస్తుందని భావించి—ఉదాహరణకు టెంపరేచర్ పెంచడం లేదా కోడర్ మోడల్ మారుస్తుంది—అలాగే అదే విఫలమవుతుంది. స్వయంచాలక అట్రిబ్యూషన్తో, వారికి ఒక స్పష్టమైన బాధ్యత కలిగిన ఏజెంట్, నిర్ణాయక దశ, మరియు సంక్షిప్త వివరణ లభిస్తుంది. ఇప్పుడు బృందం ప్రాంప్ట్లను నవీకరించవచ్చు, హ్యాండాఫ్లను రీవైర్ చేయవచ్చు, లేదా ఆ దశలో స్కీమా వెరీఫైయర్ను సృష్టించవచ్చు.
ఈ పని ప్రత్యేకంగా కష్టతరమైన మూడు కారణాలు ఉన్నాయి. మొదటిది, Task Failure వ్యవస్థాగతమవచ్చు, ఒక్క పెద్ద తప్పు కాకుండా చిన్న పొరపాట్ల సమాహారం. రెండవది, డీబగ్గింగ్ సమయంలో “సరైన” జవాబు తెలియకపోవచ్చు, ముఖ్యంగా ఓపెన్-ఎండెడ్ సమస్యలలో. మూడవది, పొడవాటి కాంటెక్స్ట్ విండోలు సంకేతాన్ని తరుగుతాయి; కారణపరమైన hinges కోసం మోడల్స్ వెతకాలి, కేవలం టెక్స్ట్ ఫ్రాగ్మెంట్స్ ని సరిపోల్చడం కాదు. అందుకే PSU మరియు Duke యొక్క రూపకం Who మరియు When రెండింటికీ ప్రాధాన్యం ఇస్తుంది, అవి సహజ-భాష Why తో పరిపూర్ణమవుతాయి, బాధ్యత మరియు యాంత్రికతను కలిపి.
సమానంగా ముఖ్యమైనది సంస్థ నిర్వహణపై ప్రభావం. ఆపరేషన్స్ బృందాలు అనుకూలమైన తరువాత-సమీక్షలను పొందుతాయి; పరిశోధన బృందాలు ఏజెంట్ వేరియంట్లను పంచుకున్న ప్రమాణంతో పోల్చుకుంటాయి; అనుగుణత బృందాలు విఫలత నమూనాలను ఆడిట్ చేస్తాయి. కూడా ఉత్పత్తి మేనేజర్లు ఎంతమాత్రం పూజారా స్థితులలో ఏజెంట్లను తరచూ ఆపివేస్తున్నాయో చూస్తారు. ఏజెంట్ విఫలత చుట్టూ కొత్త పదజాలం పరస్పర బహుళ కార్యాచరణ మరియు ప్రాధాన్య విధానాన్ని మెరుగుపరుస్తుంది.
- 🧩 లాభం: అపార్థమైన సంఘటనలను పైప్లైన్లో స్పష్టమైన, సవరించదగిన దశల్లోకి మార్చుతుంది.
- 🕒 సమర్థత: మానవ లాగ్ సమీక్ష సమయాన్ని దిగుమతించిన ఏజెంట్ మరియు దశ వరకు తగ్గించును.
- 🧪 ప్రయోగం: దోష ప్రొఫైల్ల ఆధారంగా ఏ/బి పరీక్షలను, కేవలం తుది మెట్రిక్స్ కాదు, సిధ్ధం చేస్తుంది.
- 🛡️ పాలన: భద్రత, అనుగుణత, తరువాతి సంఘటన సమీక్షలకు ఆడిట్ ట్రైల్స్ సృష్టిస్తుంది.
| నొప్పి స్థలం 😵 | జట్లు పై ప్రభావం 🧠 | అట్రిబ్యూషన్ విలువ ✅ |
|---|---|---|
| పొడవాటి, శబ్దమైన లాగ్లు | మందగమన స్పందన; ఊహాకల్పన | “Who” + “When”ని గుర్తించి సవరణలు |
| దాచిన కారణ సంబంధం | తప్పు పరిష్కారాలు | “Why” వివరణలు యాంత్రిక విధానాలు గమనిస్తాయి |
| పంచుకున్న పదజాలం లేదు | బృందాల మధ్య ఘర్షణ | స్థిరలేబుల్స్ పోలికలు సాధిస్తాయి |
| ఏజెంట్లు/టూల్లు విస్తరణ | సంక్లిష్టత పెరిగిపోవడం | సిస్టమ్ డయాగ్నోస్టిక్స్ రక్షణ గీతలు |
హెడ్లైన్ సూత్రం సులభం: స్వయంచాలక అట్రిబ్యూషన్ బహుళ ఏజెంట్ అభివృద్ధిలో డిఫాల్ట్ పద్ధతిగా మారినప్పుడు, నమ్మకాన్ని కథనాత్మకం కాకుండా కొలవగలిగే విధంగా చేస్తుంది.

Who&When బెన్చ్మార్క్ లో లోతుగా: PSU మరియు Duke నుండి డేటా, లేబుల్స్, మరియు డిజైన్ ఎంపికలు
సమస్యని స్థిరపరచడానికి, PSU మరియు Duke 127 బహుళ ఏజెంట్ సెటప్ల విఫలత లాగ్లతో Who&When డేటాసెట్ను తయారు చేశారు. కొన్ని ట్రేస్లు కవరేజ్ కోసం ఆల్గోరిథమిక్గా రూపొందించబడ్డాయి; మరికొన్నింటిని నైపుణ్యులే వాస్తవికత కోసం తయారు చేశారు. ప్రతి లాగ్ మూడు సూక్ష్మ హ్యూమన్ అనోటేషన్లను కలిగి ఉంటుంది: Who (బాధ్యత యాజమాని ఏజెంట్), When (నిర్ణాయక దశ), మరియు Why (సంక్షిప్త వివరణ). ఈ త్రిజత బాధ్యత, సమయం, మరియు కార్యాన్న మిషన్-ఉపయోగించదగిన రూపంలో క్యాప్చర్ చేస్తుంది.
డెవలపర్లు GitHub పై కోడ్ను బ్రౌజ్ చేయవచ్చు మరియు Hugging Face నుంచి డేటాసెట్ను పొందవచ్చు, ఈవాల్యుయేషన్ను పునరుత్పాదక పైప్లైన్లకు అనుసంధానం చేస్తూ. డిజైన్ సాధారణ ఆర్కిటైప్స్ను ప్రతిబింబిస్తుంది: ప్రణాళిక-తర్వాత-నిర్వహణ వర్క్ఫ్లోలు; వాదన-మరియు-ఎంపిక నిర్మాణాలు; మరియు టూల్-అగ్మెంటెడ్ ఏజెంట్లు బాహ్య APIల్ని పిలవడం. ఈ లేబుల్స్ ఈ నమూనాల్లో సౌకర్యవంతంగా ఉండి, టోపాలజీ, పని డొమైన్, లేదా లాగ్ పొడవుతో అట్రిబ్యూషన్ పద్ధతులను పోల్చడం సాధ్యం అవుతుంది.
రెండు మూల్యాంకన విధానాలు కాంటెక్స్ట్ కష్టం ఎలా మార్చుతుందో చూపుతాయి. “With Ground Truth” సెట్ బెన్చ్మార్క్ ప్రభుత్వ ఉత్తమ జవాబును గ్రహిస్తున్నప్పుడు, ఇది మధ్యবর্তী దశలను చివరి సమాధానంతో క్రాస్-చెక్ చేయవచ్చు. “Without Ground Truth” సెట్లలో, ఇది కేవలం ప్రక్రియ నుండి తార్కికమవ్వాలి—ఇది ಉತ್ಪత్తి సంఘటనలకు మరింత సమీపంగా ఉంటుంది. రెండింటిలోనూ, ప్రధాన అవుట్పుట్లు ఇదే ఉంటాయి, ఆలోచనలో గ్యాపులను విశ్లేషించేందుకు బృందాలకు సహాయపడుతుంది.
లేబుల్స్ మించిపోయి, డేటాసెట్లో మెటాడేటా కూడా ఉంటుంది: ఏజెంట్ పాత్రలు, టూల్ వాడకం, మరియు సోర్స్ సిస్టమ్లు. ఈ మెటాడేటా లోతైన విశ్లేషణలకు అనుమతిస్తుంది, ఉదాహరణకు విమర్శక agentలు తప్పుల్ని తగ్గిస్తారా లేదా టూల్ కాల్స్ బలహీన సమన్వయంతో అనుసంధానమవుతాయా. లాగ్ల పొడవు మారుతుండటంతో, ఈ బెన్చ్మార్క్ ప్రదర్శన కాంటెక్స్ట్ పరిమాణంతో ఎలా degrade అవుతుందో కొలవవచ్చు—ఇది ప్రస్తుత తార్కిక మోడల్స్ యొక్క తెలుసిన పరిమితి.
ఈ డేటా ఉపయోగిస్తున్న బృందాలకు వాస్తవిక మార్గం తమ సిస్టమ్ను ప్రతిబింబించే ఒక ప్రధాన భాగం నుంచి ప్రారంభించడం. ప్లానర్-కోడర్-టెస్టర్ త్రిభాగం నడిపే బృందం, ఇలాంటి టోపాలజీల కోసం ఫిల్టర్ చేయవచ్చు మరియు Who&When అనోటేషన్ స్కీమే ఉపయోగించి ప్రాంప్ట్లను(structure) సృష్టించవచ్చు. తరువాత, వారు వాదన-శైలి లేదా రిట్రీవల్-భారీ ఏజెంట్లను కూడా చేర్చవచ్చు మరియు విఫలత నమూనాలు శిల్పంతో మారుతాయా చూడవచ్చు.
- 📚 లేబుల్స్: Who (ఏజెంట్), When (దశ), Why (వివరణ).
- 🧭 సెట్టింగ్స్: వాస్తవిక వేరియన్స్ లో With vs. Without Ground Truth.
- 🧩 కవర్: 127 సిస్టమ్లు ప్రణాళిక, వాదన, టూల్ వాడకం విస్తరించాయి.
- 🔓 ఓపెన్: పేపర్ • కోడ్ • డేటాసెట్
| డేటాసెట్ అంశం 🗂️ | ముఖ్యమేమిటి 🎯 | బృందం పాఠం 🧰 |
|---|---|---|
| Who / When / Why లేబుల్స్ | నిర్మిత RCA ఏజెంట్ల మధ్య | పోస్ట్-మార్టెంలను స్థిరపరచండి |
| టోపాలజీ వైవిధ్యం | పద్ధతులను స్ట్రెస్-టెస్ట్ చేస్తుంది | మీ ఆర్కిటెక్చర్కు సరిపోయేలా |
| కాంటెక్స్ట్ పొడవు విభజన | స్థాయిల పరిమితులను కొలుస్తుంది | ప్లాన్ ను భాగాలుగా / సారాంశం చేయడం |
| ఓపెన్ సోర్స్ పైప్లైన్లు | పునరుత్పాదక బేస్లైన్లు | అంగీకరించి, తర్వాత అనుకూలీకరించండి |
బహుళ ఏజెంట్ డీబగ్గింగ్ నమూనాలు మరియు అట్రిబ్యూషన్ లక్ష్యాలకు త్వరిత పరిచయానికి, క్రింది శోధన కమ్యూనిటీ అంతటా సరిపోయే టాక్స్ మరియు డెమోలను మ్యాప్ చేయడంలో సహాయపడుతుంది.
డేటాసెట్ యొక్క బలము అకడమిక్ కఠినత మరియు షాప్-ఫ్లో ఉపయోగకరత మధ్య జత కలపడం: బృందాలు స్కీమాను నేరుగా తమ సంఘటన టూలింగ్లోకి ఉత్కంఠగా తీసుకుంటాయి మరియు “మూల్యాంకనం” నుంచి “మెరుగుదల” దిశగా లూప్ ముగుస్తుంది.
మూడు స్వయంచాలక అట్రిబ్యూషన్ వ్యూహాలు: అన్నీ ఒకేసారి, దశల వారీగా, మరియు బైనరీ సెర్చ్
బెన్చ్మార్క్ అమలు అయిన తర్వాత, బృందం మూడు వ్యూహాలను స్వయంచాలక అట్రిబ్యూషన్ కోసం మూల్యాంకనం చేసింది. ప్రతి ఒక్కటి లాగ్లను చదవడం మరియు వ్యాఖ్యానించడం పై వేర్వేరు తత్వాన్ని ప్రతిబింబిస్తుంది. అన్నీ ఒకేసారి పద్ధతి మొత్తం సంభాషణ మరియు వినియోగదారు ప్రశ్నను ఒకదానిలోకి (ఉదా: GPT-4o) పంపించి, ఒకేసారి Who మరియు Whenతో పాటు ఐచ్ఛిక వివరణను అడుగుతుంది. ఇది నియంత్రణ ప్రవాహంలో చవకనిది కానీ కాంటెక్స్ట్ పెద్దదైనా లేదా పాత్ర మార్పులలో సూక్ష్మ విరుద్ధతలు దాగి ఉండవచ్చు అని సూచన తప్పు చేస్తుంది.
దశల వారీగా వ్యూహం మానవ డీబగ్గింగ్ని అనుసరిస్తుంది: లాగ్ను వరుసగా నడిపించి, ప్రతి దశను అంచనా వేసి, నిర్ణాయక తప్పు కనిపించిన వెంటనే ఆగిపోతుంది. ఇది నిర్దిష్ట దశను మంచి విధంగా గుర్తించగలదు కాని టోకెన్ ఖర్చు మరియు బహుళ-దశ निर्णयాలలో పొరపాటు పెరుగుదల ప్రమాదం ఉంటుంది. దీన్ని వేగాన్ని precision కోసం మార్చే జాగ్రత్తైంది సమీక్షకునిగా భావించండి.
మధ్యమార్గం బైనరీ సెర్చ్. లాగ్ను రెండు భాగాలుగా విడగొట్టి, ఏ భాగంలో తప్పు ఉందో మోడల్ని అడిగి, తర్వాత అమలు చేయండి. ఇది కాంటెక్స్ట్ను త్వరగా కుదించగలదు మరియు ఒకేచోట అన్ని చదవక తప్పిస్తుంది. ఇది cost మరియు ఖచ్చితత్వంను సమతుల్యతగా ఉంచుతుంది, అయితే అనిశ్చిత సరిహద్దులకు సాపేక్షంగా ఉంటుంది—ఉదా: ముందస్తుగా తప్పు మొదలవుతుందో కానీ తరవాత వెలుగులోకి వస్తుంది.
ఈ మూడు మధ్య ఎంచుకోవడం నిర్బంధాలపై ఆధారపడి ఉంటుంది. బృందాలు డాలర్ ఖర్చు మరియు ఇంజనీరింగ్ సమయాన్ని ఆప్టిమైజ్ చేస్తే, All-at-Once ఉత్తమ ప్రారంభం, ముఖ్యంగా ప్రత్యక్ష తర్కాన్ని డిమాండ్ చేసే ప్రాంప్ట్లకు. ఖచ్చితమైన దశ గుర్తింపుకు ప్రాధాన്യം ఉంటే Step-by-Step ఉత్తమం. Binary Search పెద్ద లాగ్లకు ఆకర్షణీయమైనది, స్పష్టమైన భావవ్యాఖ్యలకు (ప్రణాళిక వర్సెస్ అమలు). మిశ్రమాలు—All-at-Once తో agent ను పర్యవేక్షించి Step-by-Step తో సమయం గుర్తించడం—అయితే compute లో ఆవిర్భావాన్ని తీసుకురాగలవు.
- ⚙️ అన్నీ ఒకేసారి: సులభమైన నియంత్రణ ప్రవాహం; కాంటెక్స్ట్ పరిమితులు జాగ్రత్తగా చూడండి.
- 🧭 దశల వారీగా: “When”పై అధిక ఖచ్చితత్వం; సమన్వయ పొరపాట్లను గమనించండి.
- ✂️ బైనరీ సెర్చ్: సమర్థవంతమైన కుదింపులు; అపార్థమైన సరిహద్దులపై సున్నితంగా ఉంటుంది.
- 🧪 మిశ్రమం: బలాలను కలపండి; టోకెన్లు మరియు సమయానికి అదనపు చెల్లించాలి.
| పద్ధతి 🔬 | బలం 💪 | ప్రమాదం ⚠️ | ఉత్తమ ఉపయోగం 🚀 |
|---|---|---|---|
| అన్నీ ఒకేసారి | తక్కువ ఆర్కెస్ట్రేషన్, వేగవంతమైనది | సూక్ష్మ దశ తప్పులను మిస్ అవుతుంది | చిన్న-తరరా మధ్య లాగ్లు |
| దశల వారీగా | దశ ఖచ్చితత్వం | టోకెన్ మరియు ఆలస్యం వ్యయం | భద్రతా-క్రిటికల్ ఆడిట్లు |
| బైనరీ సెర్చ్ | పొడవాటి లాగ్లకు స్తాయి | అస్పష్ట విభజన | గంభీర ట్రేస్లు pivot లతో |
| మిశ్రమం | రెండింటిలో మంచి | కంప్యూట్ భారమైనది | ఉన్నత-ప్రమాద సంఘటనలు |
ప్రయోగాత్మక heuristic గా, అన్ని మూడు పద్ధతులను అమలు చేసి ట్రేస్ పరిమాణం మరియు ప్రమాదం ద్వారా మార్గదర్శనం చేయండి: చిన్న ట్రేస్లకు All-at-Once, పెద్ద ట్రేస్లకు Binary Search, మరియు కీలక ప్రవాహాలకు Step-by-Step. ఈ విధానం తక్కువ సమయంలో వేగవంతమైన సాఫల్యాలను అందించే సమయంలో అవసరమైన చోట ఖచ్చితత్వాన్ని రిజ్వరు చేస్తుంది.

ప్రయోగాత్మక ఫలితాలు మరియు వాస్తవ ప్రపంచ వినియోగాలు: ఏది విఫలమవుతుంది, ఎవరు విఫలమవుతారు, ఎప్పుడు
Who&When పై, ఒకే ఉత్తమ పద్ధతి దాదాపు 53.5% ఖచ్చితత్వంతో బాధ్యత agent ను గుర్తించడంలో మరియు సుమారు 14.2% ఖచ్చితత్వంతో ఖచ్చిత తప్పు దశను గుర్తించడంలో సాధించింది—అన్ని బేస్లైన్ల కన్నా మెరుగు, అయినా ఉత్పత్తి-రెడియ్ nirvana నుండి చాలా దూరం. ముఖ్యంగా, బలమైన తర్కాత్మక మోడల్స్, ఉదా: OpenAI o1 మరియు DeepSeek R1, సున్నితమైన, బహుళ దశ కారణాలను సరిగా పట్టుకోలేకపోయాయి. ఈ గ్యాప్ ఏజెంట్ సమూహాల విఫలతలను వివరించడం మరియు పనులను పరిష్కరించడం మధ్య వ్యత్యాసాన్ని చాటిస్తుంది.
రెండు ముఖ్య శక్తులు సహాయపడ్డాయి: ప్రాంప్ట్లలో స్పష్టమైన తర్కంను డిమాండ్ చేయడం (ఉదా: చైన్-ఆఫ్-థాట్ శైలి కారణాలు) మరియు కాంటెక్స్ట్ను భాగాలుగా చేయడం లేదా మార్గనిర్దేశం ద్వారా పరిమితం చేయడం. అయినా, “When” లేబుల్పై లాగ్ పొడవు పెరిగేకొద్దీ ప్రదర్శన కొమ్మేస్తూ వచ్చింది—కాలానుగుణ స్థలీకరణ ఇంకా కఠినమైన భాగం. బైనరీ సెర్చ్ వ్యూహం కాంటెక్స్ట్ బరువును తగ్గించింది, మరియు దశల వారీగా అధిక ధర వద్ద కాల స్వభావమైన ఖచ్చితత్వాన్ని మెరుగుపరుస్తుంది.
వేదికపై, “Orion Labs”ని ఒక ఊహాత్మక అనలిటిక్స్ సంస్థగా పరిగణించండి, బహుళ ఏజెంట్ రిపోర్ట్ జనరేటర్ను చేర్చింది. ప్లానర్ డేటా ప్రణాళికను తయారు చేస్తాడు, రిట్రీవర్ టేబుల్లను తెస్తాడు, రచయిత కథనం కలుపుతుంది, మరియు వెరిఫైయర్ సాందర్భ్యతను తనిఖీ చేస్తుంది. ఒక క్లయింట్ త్రైమాసిక ఆదాయం ఒక ప్రాంతంలో తప్పు అని గమనిస్తారు. అట్రిబ్యూషన్ రిట్రీవర్ ఒక పాత స్కీమాను టూల్ కాల్పు అనంతరం ఉపయోగించినట్లు వెల్లడిస్తుంది. నిర్ణాయక తప్పు మెడిటన్ ట్రేస్లో జరిగింది, కాని లక్షణం తుది వెరిఫికేషన్ లో మాత్రమే తెలుస్తుంది. స్వయంచాలక డయాగ్నోస్టిక్స్తో, Orion రిట్రీవర్ను స్కీమా వెర్షన్ను డ్ర fetch సమయములో సరిచూడడానికి మరియు వెర్షన్లు సరిపోలకపోతే కఠిన తప్పుని పొందుపరచడానికి మార్చుతుంది.
మిశ్రమ వ్యూహాలు కూడా వాస్తవ వినియోగం చూశాయి: మొదట All-at-Once తో సంభావ్య agent ను ఎంపిక చేసి, తర్వాత దశల వారీగా ఆ agent హ్యాండాఫ్ల పై కేంద్రీకరించబడింది. మిశ్రమం అనేక సందర్భాల్లో ఖచ్చితతను పెంచింది, అయినా టోకెన్ ఖర్చులు పెరిగాయి. బృందాలు ఈ వ్యత్యాసాలను ఆలోచించి, ముఖ్యమైన సంఘటనలను మిశ్రమాలకు, సాధారణ regressions ను తక్కువ ఖర్చైన పద్ధతులకు రూట్ చేస్తాయి.
- 📉 వాస్తవత తనిఖీ: ప్రస్తుత మోడల్లకు పని అట్రిబ్యూషన్ పనితన కంటే కష్టం.
- 🧠 స్పష్టమైన తర్కం “Who” మరియు “When” రెండింటినీ మెరుగుపరుస్తుంది.
- 🧱 కాంటెక్స్ట్ పొడవు పరిమితి కొనసాగుతుంది; భాగాలీకరణ సహాయపడుతుంది.
- 🧯 మిశ్రమాలు అధిక ఖర్చు ఉన్నా కీలక సంఘటనలకు ఉత్తమం.
| కనుగొన్నది 🔎 | సాక్ష్యాలు 📊 | సూచనలు 🧭 |
|---|---|---|
| “Who” “When” కంటే సులభం | 53.5% vs. 14.2% | దశ స్థానీకరణ పరిశోధనకు ప్రాధాన్యత ఇవ్వండి |
| తర్కం సహాయపడుతుంది | స్పష్టమైన కారణాలతో మెరుగైన ఫలితాలు | తర్కంతో కూడిన ప్రాంప్ట్లను అవసరం చేయండి |
| కాంటెక్స్ట్ హాని చేస్తుంది | పొడవాటి లాగ్లు ఖచ్చితత్వాన్ని తగ్గిస్తాయి | బైనరీ సెర్చ్ + సారాంశం విడదీయండి |
| మిశ్రమాలు ప్రయోజనభరితాలు | ఫలితంగా మెరుగైన ఖచ్చితత్వం | ముఖ్య ప్రమాదాలకు మిశ్రమ విధానంతో రూట్ చేయండి |
సంక్లిష్టమైన సిస్టమ్ విఫలతలు మరియు డయాగ్నోస్టిక్ వర్క్ఫ్లోలపై అదనపు దృష్టికోణాలకు, ఈ శోధన ప్రాక్టీషనర్లు మరియు పరిశోధకులకి సంబంధిత టాక్స్ మరియు కేస్ స్టడీని surface చేస్తుంది.
అంతిమ విషయం: అట్రిబ్యూషన్ ఇప్పుడు కొలవగలిగేలా మారింది. సగటు స్కోర్లు తక్కువగా ఉంటే కూడా, ఆపరేషనల్ నమ్మకతకు దారి అనుభవశూన్యంగానే కాక, పునరావృతంగాను ఉంటుంది.
డెవలపర్లకోసం అమలు చేయదగిన పథకం: సిస్టమ్ డయాగ్నోస్టిక్స్ నుంచి నిరంతర నమ్మకత వరకు
పరిశోధనని విధానంగా మార్చడం పైప్లైన్ మైండ్సెట్ తో మొదలవుతుంది. స్వయంచాలక అట్రిబ్యూషన్ను బహుళ ఏజెంట్ విడుదలల CIలో సాంప్రదాయ దశగా పరిగణించండి. లాగ్లు తీసుకోండి, పాత్రలను సాధారణపరచండి, మరియు విఫలమైన ప్రతి రన్ తర్వాత ఆటోమేటిగ్గా అట్రిబ్యూషన్ నిర్వహించండి. తర్వాత ఫలితాలను టికెట్లుగా మార్చండి,.agent, దశ, మరియు సంక్షిప్త “ఎందుకు”ని స్పష్టంగా పేర్కొంటాయి. కాలక్రమేణా, ఇది ఫెయిల్యూర్ మోటిఫ్స్—for example prompt misreads, stale tools, brittle handoffs—జీవంతమైన కేటలాగ్గా తయారు అవుతుంది, ఇంజనీరిగ్ వాటిని క్రమబద్దంగా తొలగిస్తుంది.
వాస్తవిక అమలుకు ఒక ఉదాహరణ భావించండి. చిన్న ట్రేస్లపై All-at-Once తో మొదలు పెట్టి, కాంటెక్స్ట్ పొడవు పరిమితిని మించిపోయినప్పుడు Binary Search ను జోడించండి. కస్టమర్-ముఖ్యమైన లేదా భద్రతా-క్రిటికల్ వర్క్ఫ్లోల కోసం Step-by-Step లేదా హైబ్రిడ్ను ఎనేబుల్ చేయండి. స్పష్టమైన తర్కాన్ని డిమాండ్ చేసే ప్రాంప్ట్లు బండ్ చేయండి, మోడల్ తీర్పులు లాగ్ లైన్లకు మెషన్ చేయాలని కోరండి, మరియు ఖర్చును నియంత్రించేందుకు సబ్-విశ్లేషణలను క్యాచ్ చేయండి. సాధ్యమైన చోట సున్నితమైన దశలపై లైట్వెయిట్ వెరిఫైయర్లను జోడించండి: స్కీమా వెర్షన్ తనిఖీలు, టూల్ అవుట్పుట్ల యూనిట్ పరీక్షలు, మరియు అపార్ధమైన హ్యాండాఫ్లను నిరోధించేవి.
ప్రాంప్ట్ మరియు డేటా శుభ్రత ముఖ్యం. Who&When స్కీమేను అంతర్గతంగా ఉపయోగించి, బృందాల మధ్య పోస్ట్-మార్టెమ్స్ స్థిరంగా ఉండాలి. ఏజెంట్లను JSON వంటి, “claim,” “evidence,” “confidence”తో చిన్న, మెషన్-పార్సబుల్ తర్కాలు రాయడానికి ప్రేరేపించండి. అట్రిబ్యూషన్ agent లాజిక్ తప్పులని ఇన్ఫ్రాస్ట్రక్చర్ సమస్యల నుండి వైవిధ్యం చేయడానికి టూల్ మెటాడేటా—వెర్షన్, ఎండ్పాయింట్, లేటెన్సీ—లాగ్ చేయండి. బహుళ-టెనెంట్ వాతావరణాల్లో, ట్రేస్లను పంచే ముందు వ్యక్తిగత గుర్తింపుబడిన డేటాను స్క్రబ్ చేయండి.
చివరగా, ప్రముఖులతో అందుబాటులో ఉండండి. ఉత్పత్తి యూజర్ ప్రభావం వల్ల సన్నివేశాలను ప్రాధాన్యం ఇస్తుంది, పరిశోధన బలహీనమైన “When” స్థానీకరణలపై దృష్టి పెడుతుంది, మరియు ఆపరేషన్స్ ప్రతి agent మరియు దశల వారీగా సంఘటన రేట్లు చూపించే డాష్బోర్డ్స్ నిర్వహిస్తుంది. నాయకత్వం ట్రెండ్లైన్లను పొందుతుంది: అట్రిబ్యూషన్ రేట్లు మెరుగైనంతగా, సంఘటన MTTR తగ్గుతుంది. నెలలకొద్దీ, సంస్థ విఫలతలకు స్పందించటం నుండి వాటిని నివారించటానికి మారుతుంది, కొలవదగిన డయాగ్నోస్టిక్స్ మద్దతుతో.
- 🧪 చిన్నదనంగా మొదలుపెట్టండి: ఒక అధిక-వరకు వర్క్ఫ్లోపై పైలట్ చేయండి, తరువాత విస్తరించండి.
- 🪜 స్థాయి విధానం: లాగ్ పొడవు మరియు వ్యాపార ప్రమాదం ప్రకారం మార్గదర్శనం చేయండి.
- 🧰 టూలింగ్: సున్నితమైన లింక్ల వద్ద వెరిఫైయర్స్ మరియు టైప్డ్ హ్యాండాఫ్లను జోడించండి.
- 📈 మెట్రిక్స్: అట్రిబ్యూషన్ ఖచ్చితత్వాన్ని MTTR తో కలిసి ట్రాక్ చేయండి.
| దశ 🚀 | ఏం అమలు చేయాలి 🧩 | ఫలితం 🎯 |
|---|---|---|
| ఇన్స్ట్రుమెంటేషన్ | నిర్మిత లాగ్స్, పాత్ర టాగ్లు, టూల్ మెటాడేటా | అట్రిబ్యూషన్ కోసం క్లీనైన ఇన్పుట్లు |
| అట్రిబ్యూషన్ ఇంజిన్ | అన్నీ ఒకేసారి + బైనరీ సెర్చ్ + దశల వారీగా | ట్రేస్ ఆకారాలకు కవరేజ్ |
| గార్డ్రైల్స్ | స్కీమా తనిఖీలు, టూల్ యూనిట్ పరీక్షలు, టైప్డ్ హ్యాండాఫ్స్ | పునరావృత విఫలతలు తగ్గాయి |
| ఆపరేషన్స్ | Who/When/Whyతో ఆటో-టికెటింగ్ | వేగవంతమైన, ఫోకస్డ్ సవరణలు |
| లెర్నింగ్ లూప్ | ట్రెండ్ డాష్బోర్డ్స్, ఏ/బి ఏజెంట్ మార్పులు | నిరంతర నమ్మకత పెరుగుదల |
ఉత్పత్తిలో ఎప్పుడు గ్రౌండ్ ట్రూత్ అందుబాటులో ఉండదు, అందువల్ల అనిశ్చితికి బలమైన పద్ధతులను ప్రాధాన్యం ఇవ్వండి మరియు మీ ప్రమాద ప్రొఫైల్ను ప్రతిబింబించే సింటెటికిష ఇవాల్యుయేషన్లలో పెట్టుబడి పెట్టండి. అట్రిబ్యూషన్ కేవలం పరిశోధనా దశ కాదు; అది భారీగా ఇంటెలిజెంట్ సిస్టమ్స్ ని నమ్మకమైనవి చేయడానికి ఒక వాస్తవిక లీవర్.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”స్వయంచాలక విఫలత అట్రిబ్యూషన్ ను ప్రామాణిక డీబగ్గింగ్ నుండి ఎలా వేరుపరుస్తారు?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”ఇది బాధ్యత మరియు సమయాన్ని అధికారికంగా ఉంచుతుంది—ఖచ్చిత agent (Who) మరియు నిర్ణాయక దశ (When)ని గుర్తించడం—మరియు వాటితో పాటు సంక్షిప్త వివరణ (Why)ని జత చేస్తుంది. దీనివల్ల ఉచిత రూపంలోని లాగ్ సమీక్షలను metrics, audits, మరియు ఆటోమేషన్కు అనుకూలమైన నిర్మిత సిస్టమ్ డయాగ్నోస్టిక్స్గా మార్చుతుంది.”}},{“@type”:”Question”,”name”:”PSU మరియు Duke పద్ధతులను సమానంగా ఎలా మూల్యాంకనం చేస్తారు?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”వారు Who&When బెన్చ్మార్క్ను రెండు విధానాలతో ఉపయోగిస్తారు: With Ground Truth (మోడల్ సరైన జవాబు తెలుసుకున్నప్పుడు) మరియు Without Ground Truth (పధకాన్ని మాత్రమే ఆధారపడి ఉంటుంది). ఇది తర్క సామర్థ్యాన్ని జవాబు చూడటం నుంచి వేరుచేసి పోలికలను సరిపోయేలా చేస్తుంది.”}},{“@type”:”Question”,”name”:”ఎందుకు OpenAI o1 మరియు DeepSeek R1 వంటి శక్తిన మోడల్స్ ఇప్పటికీ కొంత్విధంగా ఇబ్బంది పడతాయి?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”అట్రిబ్యూషన్ బహుళ దశ కారణ తర్కం మరియు పొడవాటి కాంటెక్స్ట్లలో కాలానుగుణ స్థలీకరణను కోరుతుంది. ఇవి తుది జవాబు రూపొందించడం కంటే కష్టం, ముఖ్యంగా తప్పులు సంయోజిస్తూనే లేదా టూల్ వాడకం ద్వారా సారూప్యం కాకుండా వెలువడుతున్నప్పుడు.”}},{“@type”:”Question”,”name”:”ఎప్పుడు బృందం Step-by-Step కంటే Binary Search ను ప్రాధాన్యం ఇవ్వాలి?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”పొడవాటి ట్రేస్లకు Binary Search ఉపయోగించండి, ఎక్కడ తప్పు ప్రధాన భావ విభాగాల వెనుక ఉంటుందో (ప్రణాళిక vs అమలు). ఖచ్చితమైన దశపై ఎక్కువ ప్రాధాన్యం ఉంటే Step-by-Step ఎంచుకోండి, ఖర్చు లేదా ఆలస్యం కంటే.”}},{“@type”:”Question”,”name”:”డెవలపర్లు ఓపెన్ వనరులతో ఎక్కడ నుండి ప్రారంభించాలి?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”ICML 2025 స్పాట్లైట్ పేపర్ చదవండి, GitHub రిపొలో పైప్లైన్లకు క్లోన్ చేయండి, మరియు Who&When డేటాసెట్ను Hugging Face నుంచి పొందండి. మీ స్వంత ఏజెంట్ టోపాలజీని అనుకరించి అಂತರంగโพస్ట్-మార్టెంలో Who/When/Why స్కీమ్ను ఉపయోగించడం ప్రారంభించండి.”}}]}స్వయంచాలక విఫలత అట్రిబ్యూషన్ ను ప్రామాణిక డీబగ్గింగ్ నుండి ఎలా వేరుపరుస్తారు?
ఇది బాధ్యత మరియు సమయాన్ని అధికారికంగా ఉంచుతుంది—ఖచ్చిత agent (Who) మరియు నిర్ణాయక దశ (When)ని గుర్తించడం—మరియు వాటితో పాటు సంక్షిప్త వివరణ (Why)ని జత చేస్తుంది. దీనివల్ల ఉచిత రూపంలోని లాగ్ సమీక్షలను metrics, audits, మరియు ఆటోమేషన్కు అనుకూలమైన నిర్మిత సిస్టమ్ డయాగ్నోస్టిక్స్గా మార్చుతుంది.
PSU మరియు Duke పద్ధతులను సమానంగా ఎలా మూల్యాంకనం చేస్తారు?
వారు Who&When బెన్చ్మార్క్ను రెండు విధానాలతో ఉపయోగిస్తారు: With Ground Truth (మోడల్ సరైన జవాబు తెలుసుకున్నప్పుడు) మరియు Without Ground Truth (పధకాన్ని మాత్రమే ఆధారపడి ఉంటుంది). ఇది తర్క సామర్థ్యాన్ని జవాబు చూడటం నుంచి వేరుచేసి పోలికలను సరిపోయేలా చేస్తుంది.
ఎందుకు OpenAI o1 మరియు DeepSeek R1 వంటి శక్తిన మోడల్స్ ఇప్పటికీ కొంత్విధంగా ఇబ్బంది పడతాయి?
అట్రిబ్యూషన్ బహుళ దశ కారణ తర్కం మరియు పొడవాటి కాంటెక్స్ట్లలో కాలానుగుణ స్థలీకరణను కోరుతుంది. ఇవి తుది జవాబు రూపొందించడం కంటే కష్టం, ముఖ్యంగా తప్పులు సంయోజిస్తూనే లేదా టూల్ వాడకం ద్వారా సారూప్యం కాకుండా వెలువడుతున్నప్పుడు.
ఎప్పుడు బృందం Step-by-Step కంటే Binary Search ను ప్రాధాన్యం ఇవ్వాలి?
పొడవాటి ట్రేస్లకు Binary Search ఉపయోగించండి, ఎక్కడ తప్పు ప్రధాన భావ విభాగాల వెనుక ఉంటుందో (ప్రణాళిక vs అమలు). ఖచ్చితమైన దశపై ఎక్కువ ప్రాధాన్యం ఉంటే Step-by-Step ఎంచుకోండి, ఖర్చు లేదా ఆలస్యం కంటే.
డెవలపర్లు ఓపెన్ వనరులతో ఎక్కడ నుండి ప్రారంభించాలి?
ICML 2025 స్పాట్లైట్ పేపర్ చదవండి, GitHub రిపొలో పైప్లైన్లకు క్లోన్ చేయండి, మరియు Who&When డేటాసెట్ను Hugging Face నుంచి పొందండి. మీ స్వంత ఏజెంట్ టోపాలజీ ని అనుకరించి అಂತರంగ పోస్టుమార్టెాలలో Who/When/Why స్కీమ్ను ఉపయోగించడం ప్రారంభించండి.



అత్యంత ఆహ్లాదకరమైన షెల్ పేర్లు మరియు వాటి అర్థాలను వెతకండి
సముద్ర వాస్తుకళల దాగున్న డేటాను డీకోడ్ చేయడం సముద్రం జీవ శ్రేణుల చరిత్ర యొక్క విస్తారమైన, వికేంద్రీకృత ఆర్కైవ్గా పనిచేస్తుంది. ఈ విస్తీర్ణంలో, సముద్ర శంఖాలు కేవలం...


Funko pop వార్తలు: 2025 లో పెట్టుబడులు మరియు ప్రత్యేక డ్రాప్స్
2025 ముఖ్యమైన Funko Pop వార్తలు మరియు 2026లో కొనసాగుతున్న ప్రభావం సేకరణ రంగం గత పన్నెండు నెలల్లో గణనీయంగా మారింది. మనం 2026కి అడుగుపెడుతున్నప్పుడల్లా, Funko...


హాన్స్ వాల్టర్స్ ఎవరు? 2025లో పేరుకు వెనుక కథను ఆవిష్కరించడం
హాన్స్ వాటిలర్స్ యొక్క మిస్టరీ: 2026లో డిజిటల్ ఫుట్ప్రింట్ విశ్లేషణ ఇప్పటి విస్తృత సమాచారం సముద్రంలో, హాన్స్ వాటిలర్స్ అనే పేరు ఇలాగే రెండు విభిన్నతలను కలిగిన...


మైక్రోసాఫ్ట్ బిల్డింగ్ 30ని అన్వేషించడం: 2025లో వారి ఆవిష్కరణ మరియు సాంకేతికత హబ్
వర్క్స్పేస్ను పునঃనిర్వచించడం: రెడ్మండ్ టెక్నాలజీ అభివృద్ధి హృదయంలో లోతుగా విస్తారమైన రెడ్మండ్ క్యాంపస్లోని ఆకులతో నిండిన ప్రదేశంలో, Microsoft Building 30 కార్పొరేట్ ఆర్కిటెక్చర్లో ఒక పరస్పర...


2025 లో హోమ్వర్క్ సహాయానికి టాప్ AI టూల్స్
<h2 ఆధునిక తరగతి గదిలో విద్యార్థి మద్దతు AI అభివృద్ధి ఒక ఆదివారం రాత్రి సమయసীমా కోసం ఆందోళన పాతికాలపు విషయం అవుతుంది. 2025 అకాడమిక్ పరిసరాలలోకి...


OpenAI vs Mistral: 2025లో మీ సహజ భాషా ప్రాసెసింగ్ అవసరాలకు ఏ AI మోడల్ ఉత్తమంగా సరిపోతుంది?
2026లో మనం సాగుతున్న క్రమంలో కృత్రిమ బుద్ధి పరిమాణంలో భారీ మార్పు వచ్చింది. గత సంవత్సరం నిర్వచించిన పెట్టుబడి—అందులోని స్థిరమైన అధికారం గల దిగ్గజులు మరియు చురుకైన...


వీడ్కోలు చెప్పడం ఎట్లా: మనసుకు సాంత్వనివ్వే వీడ్కోలు మరియు ముగింపులు నిర్వహించే సహజమైన మార్లు
2026లో సున్నితమైన వీడ్కోలు కళను నావిగేట్ చేయడం వీడ్కోలు చెప్పడం అరుదుగా సులభమైన పనిగా ఉంటుంది. మీరు టెక్ రంగంలో కొత్త కెరీర్ వైపు మారుతుండగా, ఒక...


దొంగ ఓడ పేరు జనరేటర్: మీ లెజెండరీ నావుకు పేరు ఈ రోజు సృష్టించండి
మీ సముద్ర సాహసానికి పరిపూర్ణ గుర్తింపును రూపకల్పన చేయడం ఒక నౌకను పేరు పెట్టడం ఒక సరళమైన లేబెలింగ్ వ్యాయామం మాత్రమే కాదు; ఇది తెరుచుకున్న సముద్రంపై...


2025లో డైమండ్ బాడీ AI ప్రాంప్ట్లతో సృజనాత్మకతను అన్లాక్ చేయడం
AI నిష్ణాతత్వానికి డైమండ్ బాడీ ఫ్రేమ్వర్క్ పూర్ణం చేయడం 2025 యొక్క వేగంగా మారుతున్న పరిస్తితిలో, సాధారణ అవుట్పుట్ మరియు అద్భుత కృషి మధ్య వ్యత్యాసం తరచుగా...


కేన్వాస్ అంటే ఏంటి? 2025లో తెలుసుకోవాల్సిన అన్ని విషయాలు
ఆధునిక డిజిటల్ సంస్థలో క్యాన్వాస్ నిర్వచనం 2026 పరిసరాలలో, “క్యాన్వాస్” అనే పదం ఒకే నిర్వచనాన్ని దాటి, డేటా విజువలైజేషన్, విద్యా సాంకేతికత మరియు సృజనాత్మక ఇంటర్ఫేస్ల...


ల్యాప్టాప్ కీబోర్డ్ లైట్ను ఎలా ఆన్ చేయాలి: ఒక దశల వారీ గైడ్
కీబోర్డ్ ఇల్యూమినేషన్లో నైపుణ్యం సంపాదించడం: అవసరమైన అడుగు-దశ మార్గదర్శకము మందయోగ్యంగా వెలిగే గదిలో, రాత్రి విమానంలో, లేదా రాత్రి గేమింగ్ సెషన్ సమయంలో టైపింగ్ చేయడం కేవలం...


మిడ్జర్నీ కోసం 2025లో ఉత్తమ పుస్తకం మాక్అప్ ప్రాంప్ట్స్
పోస్ట్-2025 యుగంలో మెడ్జర్నీతో డిజిటల్ పుస్తక విజువలైజేషన్ 최적화 2025 అప్డేట్ల తర్వాత డిజిటల్ పుస్తక విజువలైజేషన్ పటమం దృశ్యం అత్యంత మారిందని చెప్పవచ్చు. రచయితలు, మార్కెటర్లు,...


AI-చालित వయస్క వీడియో జనరేటర్లు: 2025లో గమనించవలసిన ప్రధాన ఆవిష్కరణలు
సింథటిక్ ఇంటిమసి యొక్క ఉదయం: 2026 లో వయోజన కంటెంట్ పునర్నిర్మాణం డిజిటల్ వ్యక్తీకరణ పరిపాటిలో విప్లవాత్మక మార్పు సంభవించింది, ముఖ్యంగా వయోజన వీడియో ఉత్పత్తి ক্ষেত্রে....


ChatGPT vs LLaMA: 2025లో ఏ భాషా మోడల్ ఆధిపత్యం ఏర్పాటు చేసుకుంటుంది?
ఏఐ ఆధిపత్యానికి భారీ పోరాటం: ఓపెన్ ఎకోసిస్టమ్స్ మరియు వాల్డ్ గార్డెన్స్ త్వరగా మారుతున్న కృత్రిమ మేధస్సు ప్రదేశంలో, మెటా యొక్క LLaMA మరియు OpenAI యొక్క...


మాస్టరింగ్ ప్రారంభ ch పదాలు: ప్రారంభ పాఠకుల కోసం చిట్కాలు మరియు కార్యకలాపాలు
ప్రారంభ CH పదాల యంత్రాంగాన్ని ప్రారంభ సాహిత్యంలో డీకోడ్ చేయడం ప్రారంభ పాఠకులు లో భాషా అభివృద్ధి అనేది ఒక క్లిష్టమైన ఆపరేటింగ్ సిస్టమ్లాగా పనిచేస్తుంది: ఇది...


Howmanyofme సమీక్ష: మీ పేరు ఎంత ప్రత్యేకమైందో కనుగొనండి
డేటాతో మీ పేరు గుర్తింపులోని రహస్యాలను వెలికితీయడం మీ పేరు డ్రైవర్ లైసెన్స్పై లేబుల్ కంటే ఎక్కువ; ఇది మీ బ్రాండ్ యొక్క మూలస్తంభం మరియు మీ...


gpt-2 అవుట్పుట్ డిటెక్టర్ను అర్థం చేసుకోవడం: ఇది ఎలా పనిచేస్తుంది మరియు 2025లో ఇది ఎందుకు ముఖ్యంగా ఉంటుంది
సంయోజనాత్మక AI యుగంలో GPT-2 ఔట్పుట్ డిటెక్టర్ వెనుక ఉన్న యాంత్రికత 2026 యొక్క వేగంగా అభివృద్ధి చెందుతున్న పరిసరాల్లో, మానవుల ద్వారా రాయబడిన కథనాలు మరియు...


pirate weather ను home assistant తో ఏలా కలపాలి: పూర్తి స్థాయి దశల వారీ గైడ్
స్మార్ట్హోమ్ వ్యవస్థలలో హైపర్-స్థానిక వాతావరణ డేటా అభివృద్ధి విశ్వసనీయత అనేది ఏదైనా సమర్థవంతమైన స్మార్ట్హోమ్ సెటప్ప్ యొక్క మూలస్తంభం. 2026 పరిసరాలలో, క్లౌడ్ సేవలపై ఆధారపడి ఉండటం...


2025 యొక్క టాప్ NSFW AI ఆర్ట్ క్రియేటర్ల సమగ్ర మార్గదర్శకం: ప్రవర్తనలు మరియు అవసరమైన సాధనలు
డిజిటల్ ఎరోటికా పరిణామం మరియు 2025 యొక్క సాంకేతిక మార్పు డిజిటల్ ఆర్ట్ పరిశ్రమ పెనే విప్లవాత్మక మార్పు సాధించింది, స్థిరంగానున్న, మానవుల చేత డ్రాయింగ్ చేసిన...


OpenAI vs Meta: 2025 లో ChatGPT మరియు Llama 3 మధ్య ప్రధాన భేదాలను పరిశీలించడం
లేట్ 2025లో AI వాతావరణం: దిగ్గజాల మధ్య పోరు ఆర్టిఫిషియల్ ఇంటెలిజెన్స్ రంగం 2025 ఏప్రిల్లో Meta’s Llama 4 విడుదల తర్వాత భారీ మార్పులు చూసింది....
-

 Open Ai7 days ago
Open Ai7 days agoChatGPT ప్లగఇన్ల శక్తిని అన్లాక్ చేయండి: 2025 లో మీ అనుభవాన్ని మెరుగుపరచండి
-

 Open Ai6 days ago
Open Ai6 days agoGPT ఫైన్-ట్యూనింగ్లో నైపుణ్యం సాధించడం: 2025లో మీ మోడల్స్ను సమర్థవంతంగా కస్టమైజ్ చేయడానికి మార్గదర్శకం
-

 ఏఐ మోడల్స్6 days ago
ఏఐ మోడల్స్6 days agoGPT-4 మోడల్స్: ఆర్టిఫిషియల్ ఇంటెలిజెన్స్ 2025 లో ఎలా మారుస్తోంది
-
 Open Ai6 days ago
Open Ai6 days agoOpenAI యొక్క ChatGPT, Anthropic యొక్క Claude, మరియు Google యొక్క Bard ను పోల్చడం: 2025 లో ఏ జనరేటివ్ AI టూల్ అగ్రగామి అవుతుంది?
-

 Open Ai6 days ago
Open Ai6 days agoChatGPT 2025లో ధరలు: రేట్లు మరియు సబ్స్క్రిప్షన్ల గురించి మీరు తెలుసుకోవాల్సిన అన్ని విషయాలు
-

 Open Ai6 days ago
Open Ai6 days agoGPT మోడళ్ల దశ వికాసం ముగింపు: 2025లో వినియోగదారులు ఎం ఆశించవచ్చు