

Tecnologia
Revelando las Causas Fundamentales de los Fallos en las Tareas: Perspectivas de Investigadores de PSU y Duke sobre la Atribución Automática de Fallos en Sistemas Multiagente
Investigadores de PSU y Duke, junto con colaboradores de Google DeepMind y otros, están replanteando un problema persistente en el desarrollo Multi-Agente: rastrear la causa raíz de un fallo en la tarea a lo largo de registros largos e intrincados. Su trabajo destacado en ICML 2025 propone la Atribución Automatizada, una manera rigurosa de identificar qué agente falló y cuándo, respaldada por un nuevo conjunto de datos abierto y métodos base. El objetivo es simple: convertir las fallas opacas en Diagnósticos del Sistema estructurados que aceleren la iteración.
| ¿Con prisa? Esto es lo importante: ⚡ | |
|---|---|
| • 🔎 Nueva tarea: atribución automatizada de fallos para flujos de trabajo Multi-Agente LLM. | • 🧭 Benchmark: conjunto de datos Who&When con etiquetas Who, When y Why. |
| • 📉 Desafío: Mejor método individual alcanza ~53.5% en “Who” y ~14.2% en “When”. | • 🧰 Conclusión: Prompts híbridos, ricos en razonamiento y con control cuidadoso del contexto funcionan mejor. |
Atribución Automatizada de Fallos en Sistemas Multi-Agente: Por Qué Importa el Análisis de Causa Raíz
Los pipelines Multi-Agente prometen colaboración, pero en la práctica una avalancha de mensajes de agentes puede ocultar errores críticos. Los desarrolladores a menudo enfrentan largas trazas donde varios agentes proponen planes, critican entre sí y llaman a herramientas, pero el resultado final falla en el objetivo. Sin un Análisis de Causa Raíz estructurado, el “qué salió mal, quién lo causó y cuándo” permanece enterrado en el ruido. PSU y Duke se propusieron formalizar este eslabón perdido en la Investigación de IA nombrando y delimitando la Atribución Automatizada para Sistemas Inteligentes Multi-Agente.
La importancia de la formalización es directa. Depurar mediante una “arqueología de logs” manual consume horas, requiere gran conocimiento del sistema y escala mal conforme los equipos experimentan con más agentes, contextos más largos y flujos de trabajo con muchas herramientas. Una capa de atribución con principios transforma la culpa cualitativa en Diagnósticos del Sistema cuantificables. Este cambio afecta todo, desde la respuesta a incidentes hasta la gobernanza del modelo, mejorando finalmente la confiabilidad de los sistemas de Machine Learning implementados en organizaciones reales.
Consideremos “NovaAI”, una startup ficticia que construye un equipo autónomo de codificación. Un agente de producto recopila especificaciones, un planificador descompone tareas, un codificador escribe parches y un tester ejecuta CI. Una versión falla porque el codificador entendió mal un cambio en la API insinuado antes por el planificador. Sin atribución, el equipo parchea síntomas superficiales —quizás ajustando la temperatura o cambiando el modelo del codificador— sólo para repetir el mismo patrón de fallo. Con atribución automatizada, obtienen una asignación concreta: agente responsable, paso decisivo y una breve explicación. Ahora el equipo puede actualizar prompts, reconfigurar entregas o crear un validador de esquema en ese paso.
Hay tres razones que hacen esta tarea especialmente difícil. Primero, el Fallo en la Tarea puede ser sistémico, con pequeños errores acumulativos en lugar de un único fallo catastrófico. Segundo, la “respuesta correcta” puede no conocerse durante la depuración, especialmente en problemas abiertos. Tercero, las ventanas de contexto largas diluyen la señal; los modelos de razonamiento deben buscar puntos causales, no solo correlacionar fragmentos de texto. Por eso el enfoque de PSU y Duke enfatiza tanto el Quién como el Cuándo, complementándolos después con un Por Qué en lenguaje natural, uniendo la responsabilidad y el mecanismo.
Igualmente importante es el impacto en los procesos organizacionales. Los equipos operativos obtienen informes post-mortem consistentes; los equipos de investigación comparan variantes de agentes con un criterio compartido; los equipos de cumplimiento auditan patrones de fallos. Incluso los gerentes de producto se benefician al ver qué escenarios de usuario rutinariamente descarrilan agentes. Un nuevo vocabulario sobre fallos de agentes mejora la comunicación y la priorización interfuncional.
- 🧩 Beneficio: Convierte incidentes vagos en pasos concretos y corregibles a lo largo del pipeline.
- 🕒 Eficiencia: Reduce el tiempo de revisión manual de logs al enfocar la búsqueda en un solo agente y paso.
- 🧪 Experimentación: Permite pruebas A/B de agentes basadas en perfiles de error causales, no solo métricas finales.
- 🛡️ Gobernanza: Crea trazas de auditoría para seguridad, cumplimiento y revisiones post-incidente.
| Punto problemático 😵 | Impacto en equipos 🧠 | Valor de la atribución ✅ |
|---|---|---|
| Registros largos y ruidosos | Triages lentos; conjeturas | Precisar “Quién” + “Cuándo” para enfocar soluciones |
| Cadenas causales ocultas | Mitigaciones equivocadas | Explicaciones “Por Qué” revelan mecanismos |
| Sin vocabulario común | Fricción entre equipos | Etiquetas estándar habilitan comparaciones |
| Escala de agentes/herramientas | Picos de complejidad | Diagnósticos del Sistema como guardarraíles |
La idea principal es simple: cuando la Atribución Automatizada se convierte en una capa estándar en el desarrollo Multi-Agente, la confiabilidad deja de ser anecdótica y comienza a ser medible.

Dentro del Benchmark Who&When: Datos, Etiquetas y Decisiones de Diseño de PSU y Duke
Para fundamentar el problema, PSU y Duke curaron el conjunto de datos Who&When — registros de fallos que abarcan 127 configuraciones Multi-Agente. Algunas trazas se generan algorítmicamente para cobertura; otras son creadas por expertos para preservar el realismo. Cada registro cuenta con tres anotaciones humanas detalladas: Who (el agente responsable), When (el paso decisivo) y Why (una explicación breve). Esta tríada captura responsabilidad, momento y mecanismo en una forma usable por máquina.
Los desarrolladores pueden explorar el código en GitHub y obtener el conjunto de datos en Hugging Face, enlazando la evaluación con pipelines reproducibles. El diseño refleja arquetipos comunes: flujos de trabajo de planificación y ejecución; estructuras de debate y selección; y agentes augmentados con herramientas que llaman APIs externas. Las etiquetas son consistentes a lo largo de estos patrones, haciendo posible comparar métodos de atribución por topología, dominio de tarea o longitud de registro.
Dos regímenes de evaluación revelan cómo el cambio de contexto altera la dificultad. En la configuración “Con verdad fundamental”, el modelo que hace la atribución conoce la respuesta final correcta; puede verificar pasos intermedios contra esa respuesta. En la configuración “Sin verdad fundamental”, debe razonar sólo desde el proceso — un espejo más cercano a incidentes en producción. En ambos casos, las salidas centrales permanecen iguales, lo que ayuda a los equipos a analizar brechas en el razonamiento en lugar de memorizar resultados.
Más allá de las etiquetas, el conjunto de datos incluye metadatos: roles de agentes, uso de herramientas y sistemas de origen. Esos metadatos permiten análisis más ricos, como si agentes críticos reducen errores o si llamadas a herramientas correlacionan con coordinación frágil. Debido a que los registros varían en longitud, el benchmark puede cuantificar cómo se degrada el rendimiento con el tamaño del contexto — una limitación conocida de los modelos de razonamiento actuales.
Para equipos que adopten estos datos, un camino pragmático es comenzar con una porción estrecha que refleje su stack. Si un equipo tiene un trío planificador-codificador-tester, puede filtrar topologías similares y construir prompts usando el esquema de anotación Who&When. Luego, pueden expandirse a agentes tipo debate o con bastante recuperación y ver si los patrones de fallo cambian con la arquitectura.
- 📚 Etiquetas: Who (agente), When (paso), Why (explicación).
- 🧭 Configuraciones: Con y Sin verdad fundamental para variaciones realistas.
- 🧩 Cobertura: 127 sistemas que abarcan planificación, debate y uso de herramientas.
- 🔓 Abierto: artículo • código • conjunto de datos
| Aspecto del conjunto de datos 🗂️ | Por qué importa 🎯 | Conclusión para el equipo 🧰 |
|---|---|---|
| Etiquetas Who / When / Why | RCA estructurado entre agentes | Estandarizar post-mortems |
| Diversidad topológica | Pruebas de estrés para métodos | Ajustar a tu arquitectura |
| Variación en la longitud del contexto | Mide límites de escala | Planificar fragmentación/condensación |
| Pipelines open-source | Bases reproducibles | Adoptar, luego adaptar |
Para una orientación rápida sobre patrones de depuración Multi-Agente y objetivos de atribución, la siguiente búsqueda puede ayudar a mapear charlas y demos relevantes en la comunidad.
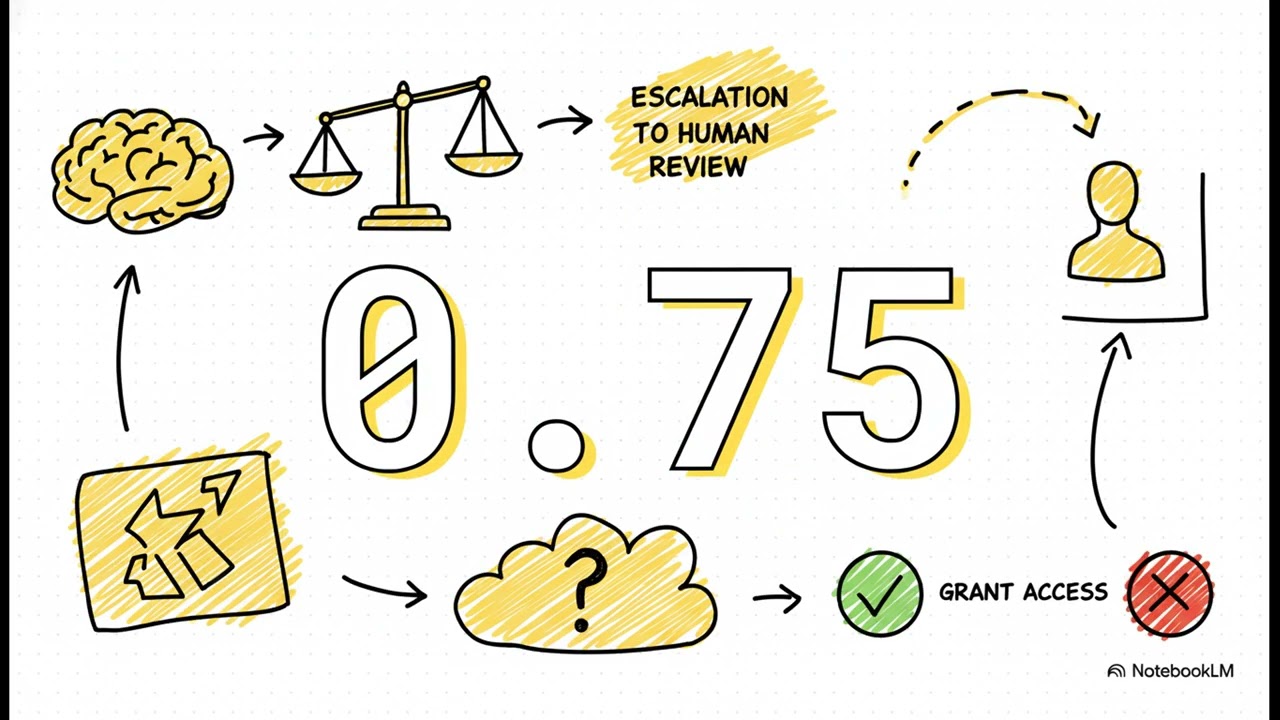
La fortaleza del conjunto de datos es su puente entre rigor académico y utilidad práctica: los equipos pueden incorporar el esquema directamente en sus herramientas para incidentes y cerrar el ciclo desde la “evaluación” hasta la “mejora”.
Tres Estrategias de Atribución Automatizada: Todo de una Vez, Paso a Paso y Búsqueda Binaria
Con el benchmark en marcha, el equipo evaluó tres estrategias para la Atribución Automatizada. Cada una refleja una filosofía distinta de lectura y razonamiento sobre los registros. El método Todo de una Vez alimenta toda la conversación y la consulta del usuario a un modelo (p. ej., GPT-4o), solicitando el Quién y el Cuándo en un solo paso, además de una explicación opcional. Es barato en control de flujo pero puede pasar por alto errores sutiles cuando los contextos son largos o cuando contradicciones veladas se esconden dentro de las entregas de roles.
La estrategia Paso a Paso imita la depuración humana: recorre el registro secuencialmente, evalúa cada paso y se detiene cuando aparece un error decisivo. Tiende a ubicar mejor el paso específico, aunque incrementa el costo en tokens y corre el riesgo de acumulación de errores en juicios de múltiples etapas. Piénselo como un revisor meticuloso que sacrifica rapidez por precisión.
Un camino intermedio es la Búsqueda Binaria. Divide el registro a la mitad, pregunta al modelo qué segmento contiene el error, luego recurre de nuevo. Esto reduce el contexto rápidamente y evita leer todo de una vez. A menudo equilibra costo y precisión, aunque aún puede ser sensible a límites ambiguos — por ejemplo, cuando una mala interpretación comienza antes pero se manifiesta después.
La elección depende de las restricciones. Si los equipos optimizan costos y tiempo de ingeniería, Todo de una Vez es un punto de partida, especialmente si los prompts requieren razonamiento explícito. Si la prioridad es precisar el paso de error en flujos críticos para seguridad, gana Paso a Paso. Búsqueda Binaria es atractiva para registros largos con pivotes semánticos claros (planificación vs. ejecución). Los híbridos —como Todo de una Vez para identificar al agente y Paso a Paso para localizar el tiempo— a menudo brillan pero añaden sobrecostos de cómputo.
- ⚙️ Todo de una Vez: flujo de control simple; cuidado con los límites de contexto.
- 🧭 Paso a Paso: mayor precisión en “Cuándo”; monitorear errores acumulativos.
- ✂️ Búsqueda Binaria: reducción eficiente; sensible a límites difusos.
- 🧪 Híbrido: combina fortalezas; paga extra en tokens y tiempo.
| Método 🔬 | Fortaleza 💪 | Riesgo ⚠️ | Mejor caso de uso 🚀 |
|---|---|---|---|
| Todo de una Vez | Baja orquestación, rápido | Pasa por alto errores sutiles | Registros cortos a medianos |
| Paso a Paso | Precisión en paso | Costo en tokens y latencia | Auditorías críticas para seguridad |
| Búsqueda Binaria | Escala a registros largos | Segmentación ambigua | Trazas profundas con pivotes |
| Híbrido | Lo mejor de ambos | Cóputo intensivo | Incidentes de alta gravedad |
La heurística práctica es instrumentar los tres y enrutar según tamaño de traza y riesgo: trazas cortas a Todo de una Vez, trazas largas a Búsqueda Binaria, y flujos críticos a Paso a Paso. Esta política captura victorias rápidas, reservando precisión para donde importa.

Resultados Experimentales y Casos de Uso Reales: Qué falla, Quién falla y Cuándo
En Who&When, un método único de mejor desempeño alcanzó cerca de 53.5% de exactitud en identificar al agente responsable y alrededor de 14.2% en precisar el paso exacto del error — mejor que muchas bases, pero lejos de la perfección productiva. Notablemente, incluso modelos potentes, incluyendo OpenAI o1 y DeepSeek R1, lucharon con la causalidad matizada de múltiples saltos. Esa brecha subraya la diferencia entre resolver tareas y explicar fallos de colectivos de agentes.
Dos palancas ayudaron consistentemente: exigir razonamiento explícito en prompts (por ejemplo, racionales estilo cadena de pensamiento) y restringir contexto mediante fragmentación o navegación guiada. Sin embargo, el desempeño bajó conforme crecían los registros, especialmente en la etiqueta “Cuándo” — evidencia de que la localización temporal sigue siendo la parte más difícil. La estrategia de Búsqueda Binaria mitigó la sobrecarga de contexto, mientras que Paso a Paso mejoró la precisión temporal a mayor costo.
En la práctica, consideremos “Orion Labs”, una firma hipotética de análisis que construye un generador de reportes Multi-Agente. Un planificador diseña un plan de datos, un recuperador obtiene tablas, un escritor compila una narrativa y un verificador revisa la consistencia. Un cliente nota que los ingresos trimestrales están desviados en una región. La atribución revela que el recuperador usó un esquema obsoleto tras una llamada a una herramienta que devolvió un índice desactualizado. El paso de error decisivo ocurrió a mitad de la traza, pero el síntoma solo se mostró en la verificación final. Con diagnósticos automatizados, Orion reconecta el recuperador para validar la versión del esquema al momento de la recuperación y para mostrar un error severo si las versiones no coinciden.
Las estrategias híbridas también vieron uso real: primero ejecutar Todo de una Vez para nominar al agente probable, luego realizar Paso a Paso enfocado solo en las entregas de ese agente. El híbrido aumentó la precisión en varios casos, aunque subió el costo en tokens. Los equipos ponderaron el costo-beneficio enroutando incidentes de alto valor a híbridos y regresiones rutinarias a métodos más económicos.
- 📉 Chequeo de realidad: La atribución de tareas es más difícil que la ejecución para los modelos actuales.
- 🧠 Razonamiento explícito mejora ambos “Quién” y “Cuándo”.
- 🧱 Longitud de contexto sigue siendo factor limitante; fragmentar ayuda.
- 🧯 Híbridos funcionan mejor en incidentes críticos a pesar del costo.
| Hallazgo 🔎 | Prueba 📊 | Implicación 🧭 |
|---|---|---|
| “Quién” más fácil que “Cuándo” | 53.5% vs. 14.2% | Priorizar investigación en localización de pasos |
| Razonamiento ayuda | Mejores resultados con racionales explícitos | Exigir prompts racionalizados |
| Contexto perjudica | Registros largos degradan precisión | Adoptar Búsqueda Binaria + resumen |
| Híbridos valen la pena | Mejora combinada en precisión | Dirigir incidentes críticos a política híbrida |
Para perspectivas adicionales sobre fallas complejas de sistemas y flujos de trabajo de diagnóstico, esta búsqueda mostrará charlas y casos relevantes tanto para practicantes como investigadores.
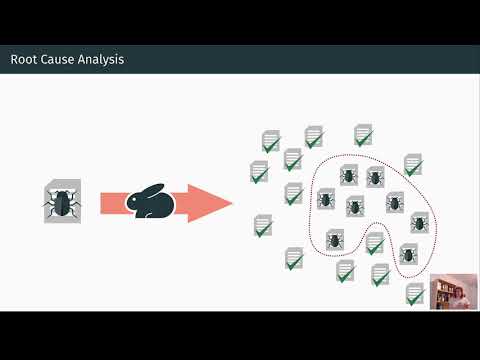
El resultado: la atribución ahora es medible. Aunque las puntuaciones sean modestas, el camino hacia la confiabilidad operativa se vuelve empírico e iterativo.
Manual Práctico para Desarrolladores: De Diagnósticos del Sistema a Confiabilidad Continua
Convertir la investigación en práctica comienza con una mentalidad de pipeline. Trate la Atribución Automatizada como una etapa estándar en CI para lanzamientos Multi-Agente. Capture logs, normalice roles y ejecute automáticamente la atribución tras cualquier ejecución fallida. Luego convierta los resultados en tickets que especifiquen el agente, paso y un breve “por qué”. Con el tiempo, esto genera un catálogo vivo de motivos de fallo — malos entendidos en prompts, herramientas obsoletas, entregas frágiles — que la ingeniería puede eliminar sistemáticamente.
Considere un despliegue práctico. Comience con Todo de una Vez en trazas cortas y añada Búsqueda Binaria por encima de un umbral de longitud de contexto. Para flujos con clientes o críticos para seguridad, habilite Paso a Paso o un híbrido. Agrupe prompts que exijan razonamiento explícito, requieran que el modelo cite líneas del log en su veredicto y almacene sub-análisis para controlar costos. Donde sea posible, añada validadores livianos en pasos sensibles: controles de versión de esquema, tests unitarios para resultados de herramientas y guardarraíles que bloqueen entregas ambiguas.
La higiene de prompts y datos importa. Use el esquema Who&When internamente para que los post-mortems permanezcan consistentes entre equipos. Incentive que los agentes escriban racionales cortos y máquina-parsables (por ejemplo, JSON con “claim”, “evidence”, “confidence”). Registre metadata de herramientas — versión, endpoint, latencia — para que la atribución pueda distinguir errores lógicos de agentes de problemas de infraestructura. En ambientes multi-inquilino, limpie datos personales antes de exportar trazas a benchmarks compartidos.
Finalmente, alinee a los interesados. Producto prioriza escenarios según impacto usuario, investigación apunta a las localizaciones “Cuándo” más difíciles y operaciones mantiene dashboards con tasas de incidentes por agente y paso. La dirección recibe líneas de tendencia: a medida que mejoran las tasas de atribución, baja el MTTR de incidentes. En meses, la organización pasa de reaccionar a fallos a prevenirlos, apoyada en diagnósticos medibles.
- 🧪 Comience pequeño: Pilote en un flujo de alto tráfico antes de escalar.
- 🪜 Política escalonada: Enrute según longitud de log y riesgo de negocio.
- 🧰 Herramientas: Añada validadores y entregas tipadas en enlaces frágiles.
- 📈 Métricas: Rastree precisión de atribución y MTTR juntos.
| Fase 🚀 | Qué implementar 🧩 | Resultado 🎯 |
|---|---|---|
| Instrumentación | Registros estructurados, etiquetas de roles, metadatos de herramientas | Entradas limpias para atribución |
| Motor de atribución | Todo de una Vez + Búsqueda Binaria + Paso a Paso | Cobertura a través de formas de trazas |
| Guardarraíles | Controles de esquema, tests unitarios para herramientas, entregas tipadas | Menos fallos recurrentes |
| Operaciones | Ticket automático con Who/When/Why | Correcciones rápidas y enfocadas |
| Bucle de aprendizaje | Dashboards de tendencias, swaps A/B de agentes | Ganancias de confiabilidad continua |
La verdad fundamental no siempre está disponible en producción, así que prefiera métodos robustos a la incertidumbre e invierta en evaluaciones sintéticas que reflejen su perfil de riesgo. La atribución no es sólo un hito de investigación; es una palanca práctica para hacer los Sistemas Inteligentes confiables a escala.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”¿Qué hace diferente a la atribución automatizada de fallos respecto a la depuración estándar?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Formaliza la responsabilidad y el tiempo: identifica el agente exacto (Quién) y el paso decisivo (Cuándo), y los vincula con una breve explicación (Por Qué). Esto convierte las revisiones de logs en formato libre en Diagnósticos del Sistema estructurados aptos para métricas, auditorías y automatización.”}},{“@type”:”Question”,”name”:”¿Cómo evalúan PSU y Duke los métodos de manera justa?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Usan el benchmark Who&When con dos regímenes: Con verdad fundamental (el modelo conoce la respuesta correcta) y Sin verdad fundamental (el modelo se basa sólo en el proceso). Esto aísla la habilidad de razonamiento de la consulta de respuestas y mantiene comparaciones consistentes.”}},{“@type”:”Question”,”name”:”¿Por qué modelos potentes como OpenAI o1 y DeepSeek R1 aún tienen dificultades?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”La atribución requiere razonamiento causal de múltiples pasos y localización temporal en contextos largos. Estas demandas son más difíciles que producir una respuesta final, especialmente cuando los errores se acumulan o emergen indirectamente mediante el uso de herramientas.”}},{“@type”:”Question”,”name”:”¿Cuándo debe un equipo preferir la Búsqueda Binaria sobre Paso a Paso?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Use Búsqueda Binaria para trazas largas donde el error probablemente esté detrás de límites semánticos importantes (planificación vs. ejecución). Elija Paso a Paso cuando la precisión en el paso exacto sea más importante que el costo o la latencia.”}},{“@type”:”Question”,”name”:”¿Dónde pueden los desarrolladores comenzar con los recursos abiertos?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Lea el artículo destacado de ICML 2025, clone el repositorio de GitHub para pipelines y descargue el conjunto de datos Who&When de Hugging Face. Comience por replicar su propia topología de agentes y adopte el esquema Who/When/Why en post-mortems internos.”}}]}¿Qué hace diferente a la atribución automatizada de fallos respecto a la depuración estándar?
Formaliza la responsabilidad y el tiempo—identificando el agente exacto (Quién) y el paso decisivo (Cuándo)—y los vincula con una breve explicación (Por Qué). Esto convierte las revisiones de logs en formato libre en Diagnósticos del Sistema estructurados aptos para métricas, auditorías y automatización.
¿Cómo evalúan PSU y Duke los métodos de manera justa?
Usan el benchmark Who&When con dos regímenes: Con verdad fundamental (el modelo conoce la respuesta correcta) y Sin verdad fundamental (el modelo se basa sólo en el proceso). Esto aísla la habilidad de razonamiento de la consulta de respuestas y mantiene comparaciones consistentes.
¿Por qué modelos potentes como OpenAI o1 y DeepSeek R1 aún tienen dificultades?
La atribución requiere razonamiento causal de múltiples pasos y localización temporal en contextos largos. Estas demandas son más difíciles que producir una respuesta final, especialmente cuando los errores se acumulan o emergen indirectamente mediante el uso de herramientas.
¿Cuándo debe un equipo preferir la Búsqueda Binaria sobre Paso a Paso?
Use Búsqueda Binaria para trazas largas donde el error probablemente esté detrás de límites semánticos importantes (planificación vs. ejecución). Elija Paso a Paso cuando la precisión en el paso exacto sea más importante que el costo o la latencia.
¿Dónde pueden los desarrolladores comenzar con los recursos abiertos?
Lea el artículo destacado de ICML 2025, clone el repositorio de GitHub para pipelines y descargue el conjunto de datos Who&When de Hugging Face. Comience por replicar su propia topología de agentes y adopte el esquema Who/When/Why en post-mortems internos.



descubre los nombres de conchas más fascinantes y sus significados
Decodificando los Datos Ocultos de las Arquitecturas Marinas El océano funciona como un vasto archivo descentralizado de la historia biológica....


Funko pop noticias: últimos lanzamientos y exclusivas en 2025
Principales Noticias de Funko Pop 2025 y el Impacto Continuo en 2026 El panorama del coleccionismo cambió drásticamente en los...


¿quién es hans walters? descubriendo la historia detrás del nombre en 2025
El Enigma de Hans Walters: Analizando la Huella Digital en 2026 En la vasta extensión de información disponible hoy en...


Explorando microsoft building 30: un centro de innovación y tecnología en 2025
Redefiniendo el Espacio de Trabajo: Dentro del Corazón de la Evolución Tecnológica de Redmond Ubicado en medio de la vegetación...


Principales herramientas de IA para asistencia con las tareas en 2025
La evolución de la IA de apoyo estudiantil en el aula moderna El pánico de un plazo del domingo por...


OpenAI vs Mistral: ¿Qué modelo de IA se adaptará mejor a tus necesidades de procesamiento de lenguaje natural en 2025?
El panorama de la Inteligencia Artificial ha cambiado drásticamente mientras navegamos a través de 2026. La rivalidad que definió el...


cómo decir adiós: maneras suaves de manejar despedidas y finales
Navegando el arte de una despedida amable en 2026 Decir adiós rara vez es una tarea sencilla. Ya sea que...


generador de nombres de barcos pirata: crea el nombre de tu legendaria embarcación hoy
Diseñando la Identidad Perfecta para Tu Aventura Marítima Nombrar una embarcación es mucho más que un simple ejercicio de etiquetado;...


Desbloqueando la creatividad con prompts de cuerpo diamond AI en 2025
Dominar el Marco del Cuerpo Diamante para la Precisión en IA En el paisaje en rápida evolución de 2025, la...


¿Qué es canvas? Todo lo que necesitas saber en 2025
Definiendo Canvas en la Empresa Digital Moderna En el panorama de 2026, el término “Canvas” ha evolucionado más allá de...


cómo encender la luz del teclado de tu portátil: una guía paso a paso
Dominar la Iluminación del Teclado: La Guía Esencial Paso a Paso Escribir en una habitación con poca luz, en un...


mejores prompts de maquetas de libros para midjourney en 2025
Optimizando la Visualización de Libros Digitales con Midjourney en la Era Post-2025 El panorama de la visualización de libros digitales...


Generadores de Videos para Adultos Impulsados por IA: Las Principales Innovaciones a Seguir en 2025
El Amanecer de la Intimidad Sintética: Redefiniendo el Contenido para Adultos en 2026 El panorama de la expresión digital ha...


ChatGPT vs LLaMA: ¿Cuál modelo de lenguaje dominará en 2025?
La Batalla Colosal por la Supremacía de la IA: Ecosistemas Abiertos vs. Jardines Amurallados En el panorama de rápida evolución...


Dominar las palabras iniciales con ch: consejos y actividades para lectores tempranos
Decodificando el Mecanismo de las Palabras Iniciales con CH en la Alfabetización Temprana La adquisición del lenguaje en lectores tempranos...


Howmanyofme reseña: descubre cuán único es realmente tu nombre
Descubriendo los secretos de la identidad de tu nombre con datos Tu nombre es más que una etiqueta en una...


Comprendiendo el detector de salida de gpt-2: cómo funciona y por qué es importante en 2025
La Mecánica Detrás del Detector de Salida GPT-2 en la Era de la IA Generativa En el panorama de rápido...


Cómo integrar pirate weather con home assistant: una guía completa paso a paso
La evolución de los datos meteorológicos hiperlocales en los ecosistemas de hogares inteligentes La fiabilidad es la piedra angular de...


Guía Integral 2025 de los Mejores Creadores de Arte AI NSFW: Tendencias y Herramientas Esenciales
La Evolución de la Erotica Digital y el Cambio Tecnológico de 2025 El panorama del Arte Digital ha sufrido un...


OpenAI vs Meta: Explorando las diferencias clave entre ChatGPT y Llama 3 en 2025
El panorama de la IA a finales de 2025: un choque de titanes El sector de la inteligencia artificial ha...
-

 Open Ai7 days ago
Open Ai7 days agoDesbloqueando el Poder de los Plugins de ChatGPT: Mejora Tu Experiencia en 2025
-

 Open Ai6 days ago
Open Ai6 days agoDominando la Fine-Tuning de GPT: Una guía para personalizar eficazmente tus modelos en 2025
-
 Open Ai6 days ago
Open Ai6 days agoComparando ChatGPT de OpenAI, Claude de Anthropic y Bard de Google: ¿Qué herramienta de IA generativa reinará suprema en 2025?
-

 Open Ai6 days ago
Open Ai6 days agoPrecios de ChatGPT en 2025: Todo lo que necesitas saber sobre tarifas y suscripciones
-

 Open Ai6 days ago
Open Ai6 days agoLa eliminación progresiva de los modelos GPT: qué pueden esperar los usuarios en 2025
-

 Modelos de IA6 days ago
Modelos de IA6 days agoModelos GPT-4: Cómo la inteligencia artificial está transformando 2025