

Tech
Het onthullen van de hoofdoorzaken van taakfouten: inzichten van PSU- en Duke-onderzoekers over geautomatiseerde fouttoewijzing in multi-agentensystemen
Onderzoekers van PSU en Duke, samen met medewerkers van Google DeepMind en anderen, herformuleren een terugkerend probleem in Multi-Agent ontwikkeling: het traceren van de oorzaak van een Taakfout over lange, verstrengelde logs. Hun ICML 2025 spotlight werk stelt Geautomatiseerde Toeschrijving voor—een rigoureuze manier om te identificeren welke agent faalde en wanneer—ondersteund door een nieuwe open dataset en basismethoden. Het doel is eenvoudig: ondoorzichtige storingen omzetten in gestructureerde Systeemdiagnostiek die iteratie versnelt.
| Gehaast? Dit is wat telt: ⚡ | |
|---|---|
| • 🔎 Nieuwe taak: Geautomatiseerde faaltoeschrijving voor LLM Multi-Agent workflows. | • 🧭 Benchmark: Who&When dataset met Who, When, Why labels. |
| • 📉 Uitdaging: Beste enkele methode scoort ~53,5% op “Who” en ~14,2% op “When”. | • 🧰 Conclusie: Hybride, redeneerrijke prompts en zorgvuldige contextcontrole werken het beste. |
Geautomatiseerde Faaltoeschrijving in Multi-Agent Systemen: Waarom Oorzaakanalyse Belangrijk Is
Multi-Agent pipelines beloven samenwerking, maar in de praktijk kan een stortvloed aan agentberichten cruciale fouten verbergen. Ontwikkelaars krijgen vaak lange sporen waarbij meerdere agenten plannen voorstellen, elkaar bekritiseren en tools aanroepen, maar het uiteindelijke resultaat mist het doel. Zonder gestructureerde Oorzaakanalyse blijft het “wat ging er mis, wie veroorzaakte het en wanneer” begraven in ruis. PSU en Duke zetten zich in om deze ontbrekende schakel in AI-onderzoek te formaliseren door Geautomatiseerde Toeschrijving voor Multi-Agent Intelligente Systemen te benoemen en af te bakenen.
Waarom formalisering belangrijk is, is helder. Debuggen via handmatig “log-archeologisch onderzoek” kost uren, vereist diepgaande systeemspecialisatie en schaalt slecht naarmate teams meer agenten, langere contexten en tools-intensieve workflows experimenteren. Een principiële toeschijvingslaag zet kwalitatieve schuld om in kwantificeerbare Systeemdiagnostiek. Die verschuiving beïnvloedt alles van incidentrespons tot modelbeheer, en verbetert uiteindelijk de betrouwbaarheid van Machine Learning systemen die in echte organisaties worden ingezet.
Neem “NovaAI,” een fictieve startup die een autonoom codeerteam bouwt. Een productagent verzamelt specificaties, een planner decomposeert taken, een coder schrijft patches en een tester voert continue integratie uit. Een release faalt omdat de coder een API-wijziging verkeerd begreep die eerder door de planner werd gesuggereerd. Zonder toeschrijving repareert het team oppervlakkige symptomen—misschien de temperatuur verhogen of het coder-model wisselen—maar herhaalt zo het falingspatroon. Met geautomatiseerde toeschrijving krijgen ze een concrete opdracht: verantwoordelijke agent, beslissende stap en een korte uitleg. Nu kan het team prompts bijwerken, overdrachten herconfigureren of een schema-validator op dat punt maken.
Drie redenen maken deze taak bijzonder moeilijk. Ten eerste kan Taakfout systemisch zijn, met cumulatieve kleine fouten in plaats van een enkele catastrofale misstap. Ten tweede is het “juiste” antwoord tijdens het debuggen mogelijk onbekend, vooral bij open-eindproblems. Ten derde verwateren lange contextvensters het signaal; redeneermodellen moeten zoeken naar causale scharnierpunten, niet alleen tekstfragmenten correleren. Daarom benadrukt de aanpak van PSU en Duke zowel Wie als Wanneer en vult die aan met een natuurlijke-taal Waarom, waarmee verantwoordelijkheid en mechanisme verbonden worden.
Even belangrijk is de impact op organisatorische processen. Operatieteams krijgen consistente post-mortems; onderzoeksteams vergelijken agentvarianten op een gedeelde meetlat; compliance-teams auditen faalpatronen. Zelfs productmanagers profiteren doordat ze zien welke gebruiksscenario’s routinematig agenten ontsporen. Een nieuwe vocabulaire rond agentfalen verbetert cross-functionele communicatie en prioritering.
- 🧩 Voordeel: Zet vage incidenten om in concrete, oplosbare stappen langs de hele pipeline.
- 🕒 Efficiëntie: Vermindert handmatige logreviews door zoekgebied te beperken tot één agent en stap.
- 🧪 Experimentatie: Maakt A/B-testen van agenten mogelijk op basis van causale foutprofielen, niet alleen eindmetrieken.
- 🛡️ Governance: Creëert auditrails voor veiligheid, compliance en post-incidentreviews.
| Pijnpunt 😵 | Impact op teams 🧠 | Waarde van toeschrijving ✅ |
|---|---|---|
| Lange, rumoerige logs | Trage triage; giswerk | Precieze “Wie” + “Wanneer” voor gerichte reparaties |
| Verborgen causale ketens | Misgerichte mitigaties | “Waarom” verklaringen onthullen mechanismen |
| Geen gedeeld vocabulaire | Teamoverschrijdende frustratie | Standaard labels maken vergelijkingen mogelijk |
| Schaalvergroting agenten/tools | Complexiteitspieken | Systeemdiagnostiek als vangrails |
De kerninzichten zijn eenvoudig: zodra Geautomatiseerde Toeschrijving een standaardlaag wordt in Multi-Agent ontwikkeling, stopt betrouwbaarheid anekdotisch te zijn en wordt het meetbaar.

Inside de Who&When Benchmark: Data, Labels en Ontwerpkeuzes van PSU en Duke
Om het probleem te verankeren, schreven PSU en Duke de Who&When dataset samen—foutlogs over 127 Multi-Agent opstellingen. Sommige sporen zijn algoritmisch gegenereerd voor dekking; andere zijn door experts gemaakt om realisme te behouden. Elke log bevat drie gedetailleerde menselijke annotaties: Wie (de verantwoordelijke agent), Wanneer (de beslissende stap) en Waarom (een korte uitleg). Deze drie-eenheid vat verantwoordelijkheid, timing en mechanisme samen in een machine-bewerkbare vorm.
Ontwikkelaars kunnen de code op GitHub doorzoeken en de dataset ophalen via Hugging Face, waarmee evaluatie aan reproduceerbare pipelines wordt gekoppeld. Het ontwerp weerspiegelt gangbare archetypen: plan-then-uitvoering workflows; debat-en-select structuren; en via tools ondersteunde agenten die externe API’s aanroepen. Labels zijn consistent over deze patronen, wat vergelijking van toeschrijvingsmethodes mogelijk maakt naar topologie, taakdomein of loglengte.
Twee evaluatieregimes tonen hoe context de moeilijkheid beïnvloedt. In de “Met Waarheidsgetrouwheid” setting kent het toeschrijvingsmodel het juiste eindantwoord; het kan tussenliggende stappen daarmee vergelijken. In de “Zonder Waarheidsgetrouwheid” setting redeneert het alleen vanuit het proces—een realistischer spiegel van productie-incidenten. In beide blijven de kernuitkomsten gelijk, wat teams helpt gaten in redeneervermogen te analyseren zonder uitkomsten uit het hoofd te leren.
Buiten labels bevat de dataset metadata: agentrollen, toolgebruik en bronsystemen. Deze metadata maakt diepere analyses mogelijk, zoals of critici-agenten fouten verminderen of toolaanroepen samenhangen met fragiele coördinatie. Omdat logs in lengte variëren, kan de benchmark meten hoe prestaties achteruitgaan met contextgrootte—een bekende beperking van huidige redeneermodellen.
Teams die deze data adopteren, kiezen best voor een smalle slice die hun stack weerspiegelt. Als een team werkt met een planner-coder-tester trio, kunnen ze filteren op soortgelijke topologieën en prompts bouwen met het Who&When annotatieschema. Later kunnen ze uitbreiden naar debat- of retrieval-intensieve agenten en zien of faalpatronen met architectuur verschuiven.
- 📚 Labels: Wie (agent), Wanneer (stap), Waarom (uitleg).
- 🧭 Instellingen: Met vs. Zonder Waarheidsgetrouwheid voor realistische variatie.
- 🧩 Dekking: 127 systemen met planning, debat, toolgebruik.
- 🔓 Open: paper • code • dataset
| Dataset aspect 🗂️ | Waarom relevant 🎯 | Team conclusie 🧰 |
|---|---|---|
| Who / When / Why labels | Gestructureerde RCA over agenten | Post-mortems standaardiseren |
| Topologie diversiteit | Test methoden onder druk | Match met eigen architectuur |
| Variatie in contextlengte | Meet schaalbeperkingen | Plan chunking/condensing |
| Open-source pipelines | Reproduceerbare baselines | Adopteren, dan aanpassen |
Voor een snelle oriëntatie op Multi-Agent debugpatronen en toeschrijvingsdoelen kan de volgende zoekopdracht relevante talks en demo’s in de community zichtbaar maken.
De kracht van de dataset is de brug tussen academische strengheid en praktische bruikbaarheid: teams kunnen het schema direct in hun incidenttools tillen en de cyclus sluiten van “evaluatie” naar “verbetering.”
Drie Geautomatiseerde Toeschrijvingsstrategieën: Alles-in-1-keer, Stap-voor-Stap, en Binaire Zoektocht
Met de benchmark aanwezig, evalueerde het team drie strategieën voor Geautomatiseerde Toeschrijving. Elk reflecteert een andere filosofie van lezen en redeneren over logs. De Alles-in-1-keer methode geeft het hele gesprek en de gebruikersvraag aan een model (bijv. GPT-4o), waarbij in één keer gevraagd wordt naar Wie en Wanneer, plus een optionele uitleg. Deze methode is goedkoop in besturingslogica maar mist fijne fouten als contexten lang zijn of wanneer subtiele tegenstrijdigheden verstopt zitten in roloverdrachten.
De Stap-voor-Stap strategie bootst menselijk debuggen na: de log wordt sequentieel bekeken, iedere stap beoordeeld, en gestopt als een beslissende fout zichtbaar is. Dit vindt de precieze stap beter, hoewel het hogere tokenkosten en risico op foutenstapeling bij multi-hop oordelen brengt. Zie het als een secuur beoordelaar die snelheid ruilt voor precisie.
Een tussenweg is Binaire Zoektocht. De log wordt in tweeën gedeeld, het model wordt gevraagd welk segment de fout bevat, waarna dat segment weer wordt doorzocht. Dit beperkt de context snel en vermijdt alles in één keer lezen. Het balanceert vaak kosten en nauwkeurigheid, maar is gevoelig voor vage grenzen—bijv. als een misinterpretatie eerder begint maar later zichtbaar wordt.
De keuze tussen deze methoden hangt af van randvoorwaarden. Bij optimalisatie voor kosten en engineer-tijd is Alles-in-1-keer een startpunt, vooral als prompts expliciet redeneren vereisen. Prioriteit bij het nauwkeurig vinden van de foutstap in safety-kritische flows ligt bij Stap-voor-Stap. Binaire Zoektocht is aantrekkelijk bij lange logs met duidelijke semantische scharnierpunten (planning vs. uitvoering). Hybriden—zoals Alles-in-1-keer om de agent te raden en Stap-voor-Stap om timing te vinden—schitteren vaak, maar vragen om extra rekenkracht.
- ⚙️ Alles-in-1-keer: eenvoudige besturingslogica; let op contextlimieten.
- 🧭 Stap-voor-Stap: hogere precisie op “Wanneer”; let op cumulatieve fouten.
- ✂️ Binaire Zoektocht: efficiënte afbakening; gevoelig voor vage grenzen.
- 🧪 Hybride: combineert sterke punten; hogere token- en tijdkosten.
| Methode 🔬 | Sterkte 💪 | Risico ⚠️ | Beste gebruiksgeval 🚀 |
|---|---|---|---|
| Alles-in-1-keer | Weinig coördinatie, snel | Mist subtiele stapfouten | Korte tot middellange logs |
| Stap-voor-Stap | Stapprecisie | Token- en latentie-kosten | Veiligheidskritische audits |
| Binaire Zoektocht | Schaalt bij lange logs | Ambigu segmenteren | Diepe sporen met schakels |
| Hybride | Beste van beide | Rekenintensief | Incidenten met hoge impact |
De praktische vuistregel is: implementeer alle drie en stuur aan op trace-grootte en risico: korte sporen naar Alles-in-1-keer, lange sporen naar Binaire Zoektocht, en kritische workflows naar Stap-voor-Stap. Dit beleid pakt snelle successen terwijl precisie wordt gereserveerd voor waar het telt.

Experimentele Resultaten en Praktijkvoorbeelden: Wat Faalt, Wie Faalt, en Wanneer
Op Who&When bereikte een beste enkele methode circa 53,5% nauwkeurigheid op het identificeren van de verantwoordelijke agent en circa 14,2% op het exact aanwijzen van de foutstap—beter dan veel baselines, maar nog ver van productie-klaar. Opvallend is dat zelfs sterke redeneermodellen, waaronder OpenAI o1 en DeepSeek R1, worstelen met genuanceerde, multi-hop causaliteit. Die kloof benadrukt het verschil tussen het oplossen van taken en het uitleggen van fouten binnen agentcollectieven.
Twee hefbomen hielpen consequent: het eisen van expliciete redenering in prompts (bijv. keten-van-gedachte-stijl verklaringen) en het beperken van context via chunking of gerichte navigatie. Echter daalden prestaties bij langere logs, vooral op het “Wanneer” label—bewijs dat temporele lokalisatie het moeilijkste blijft. De Binaire Zoektocht strategie matigde contextoverbelasting, terwijl Stap-voor-Stap temporele precisie verbetert tegen hogere kosten.
In de praktijk, kijk naar “Orion Labs,” een hypothetisch analysebedrijf met een Multi-Agent rapportgenerator. Een planner maakt een dataplan, een retriever haalt tabellen op, een schrijver componeert een verhaal en een verifier controleert consistentie. Een klant merkt dat het kwartaalinkomen in één regio afwijkt. Toeschrijving onthult dat de retriever een verouderd schema gebruikte nadat een tool een oude index teruggaf. De beslissende foutstap gebeurde midden in het spoor, maar het symptoom verscheen pas bij de laatste verificatie. Met geautomatiseerde diagnostiek herconfigureert Orion de retriever om schema-versies tijdens ophalen te valideren en harde fouten te melden bij mismatch.
Hybride strategieën zagen ook praktijkgebruik: eerst Alles-in-1-keer om de waarschijnlijke agent te nomineren, daarna Stap-voor-Stap gericht op alleen de overdrachten van die agent. Het hybride gebruik verhoogde de nauwkeurigheid in meerdere gevallen, hoewel tokenkosten stegen. Teams wegen de afweging door belangrijke incidenten naar hybriden te routeren en routine regressies naar goedkopere methodes.
- 📉 Realiteitscheck: Taaktoeschrijving is moeilijker dan taakuitvoering voor huidige modellen.
- 🧠 Expliciete redenering verhoogt zowel “Wie” als “Wanneer.”
- 🧱 Contextlengte blijft beperkende factor; chunking helpt.
- 🧯 Hybriden werken het beste voor kritische incidenten ondanks hogere kosten.
| Bevinding 🔎 | Bewijs 📊 | Implicatie 🧭 |
|---|---|---|
| “Wie” makkelijker dan “Wanneer” | 53,5% vs. 14,2% | Prioriteer onderzoek naar staplokalisatie |
| Redeneren helpt | Beter met expliciete verklaringen | Verplicht rationaliserende prompts |
| Context schaadt | Lange logs verlagen nauwkeurigheid | Gebruik Binaire Zoektocht + samenvatten |
| Hybriden lonen | Verbeterde gecombineerde nauwkeurigheid | Leid kritieke gevallen naar hybride beleid |
Voor aanvullende perspectieven op complexe systeemfouten en diagnostische workflows toont deze zoekopdracht relevante presentaties en casestudies voor zowel praktijkmensen als onderzoekers.
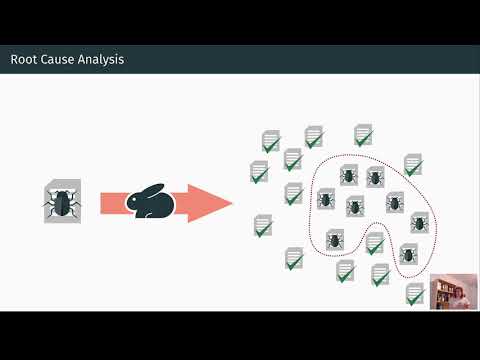
De conclusie: toeschrijving is nu meetbaar. Ook al zijn de scores bescheiden, de weg naar operationele betrouwbaarheid wordt empirisch en iteratief.
Actiegericht Handboek voor Ontwikkelaars: Van Systeemdiagnostiek naar Continue Betrouwbaarheid
Onderzoek omzetten in praktijk begint met een pipeline-mentaliteit. Behandel Geautomatiseerde Toeschrijving als een standaardfase in CI voor Multi-Agent releases. Neem logs op, normaliseer rollen en voer na elke mislukte run automatisch toeschrijving uit. Converteer daarna resultaten in tickets die agent, stap, en korte “waarom” specificeren. Dit produceert over tijd een levend overzicht van faalmoties—prompt misinterpretaties, verouderde tools, fragiele overdrachten—die engineering systematisch kan elimineren.
Denk aan een praktische uitrol. Begin met Alles-in-1-keer voor korte sporen en voeg Binaire Zoektocht toe boven een contextlengte-drempel. Voor klantgerichte of veiligheidskritische workflows zet Stap-voor-Stap of een hybride in. Bundel prompts die expliciete redenering eisen, laat modelbesluiten logregels citeren en cacheer deelanalyses om kosten te beheersen. Voeg waar mogelijk lichte validators toe bij gevoelige stappen: schema-controles, unittests voor tooluitvoer, en vangrails die vage overdrachten blokkeren.
Prompt- en datahygiëne zijn belangrijk. Gebruik intern het Who&When-schema zodat post-mortems consistent blijven binnen teams. Moedig agenten aan korte, machine-parseerbare motiveringen te schrijven (bijv. JSON met “claim,” “bewijs,” “vertrouwen”). Log tool-metadata—versie, endpoint, latency—zodat toeschrijving agentlogica fouten kan onderscheiden van infrastructuurproblemen. In multi-tenant omgevingen moet persoonlijk identificeerbare data worden geanonimiseerd voordat sporen in gedeelde benchmarks gaan.
Tot slot stakeholders afstemmen. Product prioriteert scenario’s naar gebruikersimpact, onderzoek richt zich op de moeilijkste “Wanneer”-lokalisaties, en operations beheert dashboards met incidentgraad per agent en stap. Leidinggevenden zien trendlijnen: naarmate toeschrijvingspercentages verbeteren, daalt MTTR. Over maanden verschuift de organisatie van reactief falen oplossen naar preventie, gesteund door meetbare diagnostiek.
- 🧪 Begin klein: Piloot op één drukke workflow voor opschaling.
- 🪜 Gelaagd beleid: Routeer op loglengte en zakelijk risico.
- 🧰 Tools: Voeg validators en getypeerde overdrachten toe op kwetsbare schakels.
- 📈 Metrieken: Volg toeschrijvingsnauwkeurigheid en MTTR samen.
| Fase 🚀 | Wat te implementeren 🧩 | Uitkomst 🎯 |
|---|---|---|
| Instrumentatie | Gestructureerde logs, rol-tags, tool-metadata | Schone input voor toeschrijving |
| Toeschrijving-engine | Alles-in-1-keer + Binaire Zoektocht + Stap-voor-Stap | Dekking over trace-uitvormingen |
| Vangrails | Schema-controles, tool unittests, getypeerde overdrachten | Minder terugkerende fouten |
| Operations | Auto-ticketing met Wie/Wanneer/Waarom | Snellere, gerichte reparaties |
| Leerloop | Trenddashboards, agent swaps A/B | Continue betrouwbaarheidsgroei |
Waarheidsgetrouwheid is in productie niet altijd beschikbaar, geef daarom voorkeur aan methoden die robuust zijn tegen onzekerheid en investeer in synthetische evaluaties die je risicoprofiel spiegelen. Toeschrijving is niet alleen een onderzoeksmijlpaal; het is een praktische hefboom om Intelligente Systemen schaalbaar betrouwbaar te maken.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Wat maakt geautomatiseerde faaltoeschrijving anders dan standaard debuggen?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Het formaliseert verantwoordelijkheid en timing—het identificeren van de exacte agent (Wie) en beslissende stap (Wanneer)—en koppelt deze aan een korte uitleg (Waarom). Dit verandert vrije logreviews in gestructureerde Systeemdiagnostiek geschikt voor metrics, audits en automatisering.”}},{“@type”:”Question”,”name”:”Hoe evalueren PSU en Duke methodes eerlijk?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Ze gebruiken de Who&When benchmark met twee regimes: Met Waarheidsgetrouwheid (het model kent het juiste antwoord) en Zonder Waarheidsgetrouwheid (het model vertrouwt uitsluitend op het proces). Dit isoleert redeneervaardigheid van antwoorden opzoeken en houdt vergelijkingen consistent.”}},{“@type”:”Question”,”name”:”Waarom worstelen sterke modellen zoals OpenAI o1 en DeepSeek R1 nog steeds?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Toeschrijving vereist multi-hop causaal redeneren en temporele lokalisatie over lange contexten. Deze eisen zijn moeilijker dan een eindantwoord produceren, vooral wanneer fouten zich opstapelen of indirect via toolgebruik ontstaan.”}},{“@type”:”Question”,”name”:”Wanneer moet een team liever Binaire Zoektocht kiezen dan Stap-voor-Stap?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Gebruik Binaire Zoektocht bij lange logs waar de fout waarschijnlijk achter grote semantische grenzen ligt (planning versus uitvoering). Kies Stap-voor-Stap als precisie over de exacte stap belangrijker is dan kosten of latentie.”}},{“@type”:”Question”,”name”:”Waar kunnen ontwikkelaars starten met de open bronnen?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Lees het ICML 2025 spotlight paper, kloon de GitHub-repo voor pipelines, en haal de Who&When dataset van Hugging Face. Begin met het spiegelen van je eigen agenttopologie en adopteer het Who/Wanneer/Waarom schema in interne post-mortems.”}}]}Wat maakt geautomatiseerde faaltoeschrijving anders dan standaard debuggen?
Het formaliseert verantwoordelijkheid en timing—het identificeren van de exacte agent (Wie) en beslissende stap (Wanneer)—en koppelt deze aan een korte uitleg (Waarom). Dit verandert vrije logreviews in gestructureerde Systeemdiagnostiek geschikt voor metrics, audits en automatisering.
Hoe evalueren PSU en Duke methodes eerlijk?
Ze gebruiken de Who&When benchmark met twee regimes: Met Waarheidsgetrouwheid (het model kent het juiste antwoord) en Zonder Waarheidsgetrouwheid (het model vertrouwt uitsluitend op het proces). Dit isoleert redeneervaardigheid van antwoorden opzoeken en houdt vergelijkingen consistent.
Waarom worstelen sterke modellen zoals OpenAI o1 en DeepSeek R1 nog steeds?
Toeschrijving vereist multi-hop causaal redeneren en temporele lokalisatie over lange contexten. Deze eisen zijn moeilijker dan een eindantwoord produceren, vooral wanneer fouten zich opstapelen of indirect via toolgebruik ontstaan.
Wanneer moet een team liever Binaire Zoektocht kiezen dan Stap-voor-Stap?
Gebruik Binaire Zoektocht bij lange logs waar de fout waarschijnlijk achter grote semantische grenzen ligt (planning versus uitvoering). Kies Stap-voor-Stap als precisie over de exacte stap belangrijker is dan kosten of latentie.
Waar kunnen ontwikkelaars starten met de open bronnen?
Lees het ICML 2025 spotlight paper, kloon de GitHub-repo voor pipelines, en haal de Who&When dataset van Hugging Face. Begin met het spiegelen van je eigen agenttopologie en adopteer het Who/Wanneer/Waarom schema in interne post-mortems.



ontdek de meest fascinerende schelpennamen en hun betekenissen
Het ontcijferen van de verborgen gegevens van maritieme architecturen De oceaan functioneert als een enorm, gedecentraliseerd archief van biologische geschiedenis....


Funko pop nieuws: nieuwste releases en exclusieve drops in 2025
Belangrijke Funko Pop Nieuws in 2025 en de Voortdurende Impact in 2026 Het verzamelveld is het afgelopen jaar drastisch veranderd....


wie is hans walters? het verhaal achter de naam onthuld in 2025
De Enigma van Hans Walters: Een Analyse van de Digitale Voetafdruk in 2026 In de uitgestrekte hoeveelheid informatie die tegenwoordig...


Ontdekking van microsoft gebouw 30: een knooppunt van innovatie en technologie in 2025
De werkplek herdefiniëren: binnen het hart van Redmonds technologische evolutie Gelegen te midden van het groen van de uitgestrekte campus...


Top AI Tools voor Hulp bij Huiswerk in 2025
De evolutie van AI voor studentenondersteuning in het moderne klaslokaal De paniek van een deadline op zondagavond wordt langzaam een...


OpenAI vs Mistral: Welk AI-model past het beste bij uw behoeften op het gebied van Natural Language Processing in 2025?
Het landschap van Artificial Intelligence is drastisch veranderd terwijl we door 2026 navigeren. De rivaliteit die vorig jaar de toon...


hoe je afscheid zegt: zachte manieren om om te gaan met vaarwel en eindes
De kunst van een zachte afscheidsneming in 2026 navigeren Afscheid nemen is zelden een eenvoudige taak. Of je nu overstapt...


piratenschip naam generator: creëer vandaag nog de naam van jouw legendarische schip
Het Perfecte Identiteitsontwerp voor je Maritieme Avontuur Het benoemen van een schip is veel meer dan een eenvoudige etikettering; het...


Creativiteit ontsluiten met diamond body AI prompts in 2025
Beheersen van het Diamond Body Framework voor AI-nauwkeurigheid In het snel evoluerende landschap van 2025 ligt het verschil tussen een...


Wat is canvas? Alles wat je moet weten in 2025
Definiëren van Canvas in het Moderne Digitale Bedrijf In het landschap van 2026 is de term “Canvas” geëvolueerd voorbij een...


hoe je het toetsenbordlicht van je laptop aanzet: een stapsgewijze handleiding
Beheer van toetsenbordverlichting: de essentiële stapsgewijze handleiding Typen in een schemerige kamer, tijdens een nachtelijke vlucht of tijdens een late...


beste boek mockup prompts voor midjourney in 2025
Optimaliseren van digitale boekvisualisatie met Midjourney in het post-2025 tijdperk Het landschap van digitale boekvisualisatie veranderde drastisch na de algoritmische...


AI-Driven Volwassenenvideo Generators: De Topinnovaties om in 2025 in de Gaten te Houden
De Dageraad van Synthetische Intimiteit: Het Herdefiniëren van Volwasseneninhoud in 2026 Het landschap van digitale expressie heeft een ingrijpende verschuiving...


ChatGPT vs LLaMA: Welk taalmodel zal domineren in 2025?
De Kolossale Strijd om AI-Dominantie: Open Ecosystemen vs. Gesloten Tuinen In het snel evoluerende landschap van kunstmatige intelligentie is de...


Masteren van beginwoordjes met ch: tips en activiteiten voor beginnende lezers
De Mechaniek van Initieel CH Woorden in Vroege Geletterdheid Ontcijferen Taalverwerving bij jonge lezers functioneert opmerkelijk als een complex besturingssysteem:...


Howmanyofme review: ontdek hoe uniek jouw naam echt is
Het ontsluiten van de geheimen van je naamidentiteit met data Je naam is meer dan alleen een label op een...


Begrijpen van gpt-2 output detector: hoe het werkt en waarom het belangrijk is in 2025
De Mechanica Achter de GPT-2 Output Detector in het Tijdperk van Generatieve AI In het snel veranderende landschap van 2026...


Hoe pirate weather te integreren met home assistant: een complete stapsgewijze handleiding
De Evolutie van Hyper-Lokale Weergegevens in Smart Home Ecosystemen Betrouwbaarheid is de hoeksteen van elke effectieve Smart Home installatie. In...


De uitgebreide gids van 2025 voor top NSFW AI-kunstenaars: trends en essentiële tools
De Evolutie van Digitale Erotica en de Technologische Verschuiving van 2025 Het landschap van Digitale Kunst heeft een enorme wijziging...


OpenAI vs Meta: De Belangrijkste Verschillen tussen ChatGPT en Llama 3 in 2025 Verkennen
Het AI-landschap in eind 2025: Een botsing van giganten De sector van kunstmatige intelligentie heeft een ingrijpende verschuiving doorgemaakt sinds...
-
Ongecategoriseerd4 days ago
hoe je afscheid zegt: zachte manieren om om te gaan met vaarwel en eindes
-

 Open Ai7 days ago
Open Ai7 days agoDe Kracht van ChatGPT-plugins Ontsluiten: Verbeter je Ervaring in 2025
-

 Uncategorized1 week ago
Uncategorized1 week agoOntdek het oak and ember-menu van 2025: wat te verwachten en topgerechten om te proberen
-

 Open Ai6 days ago
Open Ai6 days agoMeesterschap in GPT Fine-Tuning: Een Gids voor het Effectief Aanpassen van Uw Modellen in 2025
-

 Open Ai7 days ago
Open Ai7 days agoChatGPT in 2025: De belangrijkste beperkingen en strategieën om deze te overwinnen verkend
-

 Tools6 days ago
Tools6 days agoChatGPT Typefouten: Hoe Veelvoorkomende Fouten te Herstellen en te Voorkomen