

Tech
Die Ursachen von Aufgabenfehlern aufdecken: Erkenntnisse von PSU- und Duke-Forschern zur automatisierten Fehlerzuordnung in Multi-Agenten-Systemen
PSU- und Duke-Forscher, unterstützt von Kollegen von Google DeepMind und anderen, überdenken ein immer wiederkehrendes Problem in der Multi-Agenten-Entwicklung: die Wurzelursache eines Aufgabenversagens über lange, verknüpfte Protokolle hinweg nachzuverfolgen. Ihre Spotlight-Arbeit für ICML 2025 schlägt Automatisierte Attribution vor—eine rigorose Methode, um zu identifizieren, welcher Agent versagt hat und wann—unterstützt durch einen neuen offenen Datensatz und Basismethoden. Das Ziel ist einfach: undurchsichtige Ausfälle in strukturierte Systemdiagnosen zu verwandeln, die die Iteration beschleunigen.
| Eilig? Hier ist das Wichtigste: ⚡ | |
|---|---|
| • 🔎 Neue Aufgabe: Automatisierte Fehlerattribution für LLM Multi-Agent-Workflows. | • 🧭 Benchmark: Who&When-Datensatz mit Labels für Wer, Wann, Warum. |
| • 📉 Herausforderung: Beste einzelne Methode erreicht ~53,5% bei „Wer“ und ~14,2% bei „Wann“. | • 🧰 Erkenntnis: Hybride, reasoningreiche Eingabeaufforderungen und sorgfältige Kontextkontrolle funktionieren am besten. |
Automatisierte Fehlerattribution in Multi-Agenten-Systemen: Warum Root Cause Analysis wichtig ist
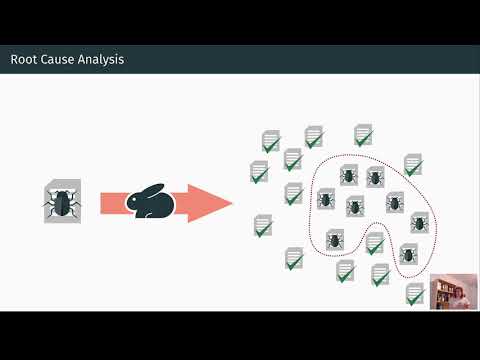
Multi-Agenten-Pipelines versprechen Zusammenarbeit, doch in der Praxis kann eine Flut von Agentenmeldungen kritische Fehler verschleiern. Entwickler stehen oft vor langen Spuren, in denen mehrere Agenten Pläne vorschlagen, sich gegenseitig kritisieren und Werkzeuge aufrufen, aber das Endergebnis verfehlt das Ziel. Ohne strukturierte Root Cause Analysis bleiben „was schiefgelaufen ist, wer es verursacht hat und wann“ im Rauschen verborgen. PSU und Duke haben sich zum Ziel gesetzt, diese fehlende Verbindung in der KI-Forschung zu formalieren, indem sie Automatisierte Attribution für Multi-Agenten-Intelligente Systeme benennen und abgrenzen.
Warum Formalisierung wichtig ist, ist einfach. Manuelles „Log-Archaeology“-Debugging kostet Stunden, erfordert tiefes Systemwissen und skaliert schlecht, wenn Teams mit mehr Agenten, längeren Kontexten und werkzeuglastigen Workflows experimentieren. Eine prinzipielle Attributionsebene wandelt qualitative Schuldzuweisungen in quantifizierbare Systemdiagnosen um. Dieser Wandel beeinflusst alles von der Reaktion auf Vorfälle bis zur Modellsteuerung und verbessert letztlich die Zuverlässigkeit von Maschinellen Lernsystemen, die in realen Organisationen eingesetzt werden.
Betrachten wir „NovaAI“, ein fiktives Startup, das eine autonome Codierungscrew aufbaut. Ein Produktagent sammelt Spezifikationen, ein Planer zerlegt Aufgaben, ein Programmierer schreibt Patches und ein Tester führt CI aus. Eine Veröffentlichung schlägt fehl, weil der Programmierer eine API-Änderung missverstanden hat, die der Planer zuvor angedeutet hatte. Ohne Attribution behebt das Team nur Symptome – vielleicht durch Erhöhen der Temperatur oder Wechseln des Programmierermodells – und wiederholt dieselben Fehler. Mit automatischer Attribution erhalten sie eine konkrete Zuordnung: verantwortlicher Agent, entscheidender Schritt und kurze Erklärung. Jetzt kann das Team Eingabeaufforderungen aktualisieren, Übergaben neu verdrahten oder einen Schema-Validator an diesem Schritt erstellen.
Drei Gründe machen diese Aufgabe besonders schwierig. Erstens kann das Aufgabenversagen systemisch sein, mit sich verstärkenden kleinen Fehlern statt eines katastrophalen Fehlers. Zweitens ist die „richtige“ Antwort beim Debuggen möglicherweise nicht bekannt, besonders bei offenen Problemen. Drittens verwässern lange Kontextfenster das Signal; Reasoning-Modelle müssen nach kausalen Schlüsselstellen suchen, nicht nur Textfragmente korrelieren. Deshalb betont das Framing von PSU und Duke sowohl das Wer als auch das Wann und ergänzt sie mit einem natürlichsprachlichen Warum, das Verantwortung und Mechanismus verbindet.
Ebenso wichtig ist die Wirkung auf organisatorische Prozesse. Operationsteams erhalten konsistente Nachbesprechungen; Forschungsteams vergleichen Agentenvarianten mithilfe gemeinsamer Maßstäbe; Compliance-Teams prüfen Fehlerprofile. Auch Produktmanager profitieren, da sie sehen, welche Benutzerszenarien Agenten regelmäßig entgleisen lassen. Ein neuer Wortschatz rund um Agentenfehler verbessert die abteilungsübergreifende Kommunikation und Priorisierung.
- 🧩 Nutzen: Wandelt vage Vorfälle in konkrete, behebbare Schritte entlang der Pipeline um.
- 🕒 Effizienz: Verkürzt die Zeit zur manuellen Log-Analyse durch Eingrenzung auf einen einzelnen Agenten und Schritt.
- 🧪 Experimentieren: Ermöglicht A/B-Tests von Agenten basierend auf kausalen Fehlerprofilen, nicht nur Endmetriken.
- 🛡️ Governance: Schafft Prüfpunkte für Sicherheit, Compliance und Nachvorfall-Analysen.
| Problem 😵 | Auswirkung auf Teams 🧠 | Attributionswert ✅ |
|---|---|---|
| Lange, laute Protokolle | Langsame Eingrenzung; Schätzungen | Genaues „Wer“ + „Wann“ zur Fokussierung von Fehlerbehebungen |
| Versteckte kausale Ketten | Fehlangepasste Gegenmaßnahmen | „Warum“-Erklärungen decken Mechanismen auf |
| Kein gemeinsames Vokabular | Abteilungsübergreifende Reibungen | Standardisierte Labels ermöglichen Vergleiche |
| Skalierung von Agenten/Werkzeugen | Komplexitätsspitzen | Systemdiagnosen als Schutzvorrichtungen |
Die zentrale Erkenntnis ist einfach: Wenn Automatisierte Attribution zur Standardebene in der Multi-Agenten-Entwicklung wird, hört Zuverlässigkeit auf, anekdotisch zu sein, und wird messbar.

Im Who&When-Benchmark: Daten, Labels und Designentscheidungen von PSU und Duke
Um das Problem zu verankern, haben PSU und Duke den Who&When-Datensatz kuratiert—Fehlerprotokolle von 127 Multi-Agenten-Setups. Einige Spuren wurden algorithmisch für die Abdeckung generiert; andere von Experten für realistische Szenarien erstellt. Jedes Protokoll trägt drei feingliedrige menschliche Anmerkungen: Wer (verantwortlicher Agent), Wann (entscheidender Schritt) und Warum (kurze Erklärung). Dieses Triumvirat erfasst Verantwortung, Zeitpunkt und Mechanismus in maschinenlesbarer Form.
Entwickler können den Code auf GitHub durchsuchen und den Datensatz auf Hugging Face abrufen, wodurch die Auswertung an reproduzierbare Pipelines gebunden wird. Das Design spiegelt gängige Archetypen wider: Planung-then-Ausführung Workflows; Debatten- und Auswahlstrukturen; und tool-unterstützte Agenten, die externe APIs aufrufen. Labels sind über diese Muster konsistent, was Vergleiche von Attributionsmethoden nach Topologie, Aufgabenbereich oder Protokolllänge ermöglicht.
Zwei Auswertungsmodi zeigen, wie sich Kontextschwankungen auf die Schwierigkeit auswirken. Im „Mit Ground Truth“-Setting kennt das Modell die korrekte Endantwort; es kann Zwischenschritte gegen diese Antwort prüfen. Im „Ohne Ground Truth“-Setting muss es allein aus dem Prozess schließen—eine realistischere Abbildung von Produktionsvorfällen. In beiden bleiben die Kernoutputs gleich, was Teams hilft, Lücken im Denken zu analysieren statt Ergebnisse auswendig zu lernen.
Neben Labels umfasst der Datensatz Metadaten: Agentenrollen, Werkzeugnutzung und Quellsysteme. Diese Metadaten ermöglichen reichhaltigere Analysen, etwa ob Kritiker-Agenten Fehltritte verringern oder Tool-Aufrufe mit brüchiger Koordination korrelieren. Da Protokolle unterschiedlich lang sind, kann der Benchmark messen, wie Leistung bei wachsendem Kontext abnimmt—eine bekannte Einschränkung aktueller Reasoning-Modelle.
Für Teams, die diese Daten nutzen, ist ein pragmatischer Einstieg ein enger Ausschnitt, der den eigenen Stack widerspiegelt. Wenn ein Team ein Planer-Programmierer-Tester-Trio betreibt, kann es ähnliche Topologien filtern und Eingabeaufforderungen mit dem Who&When-Annotationsschema bauen. Später kann es zu Debatten-Stil- oder retrievallastigen Agenten erweitern und prüfen, ob sich Fehlerprofile mit der Architektur verschieben.
- 📚 Labels: Wer (Agent), Wann (Schritt), Warum (Erklärung).
- 🧭 Einstellungen: Mit vs. Ohne Ground Truth für realistische Varianz.
- 🧩 Abdeckung: 127 Systeme mit Planung, Debatte, Werkzeugnutzung.
- 🔓 Offen: Paper • Code • Datensatz
| Datensatz-Aspekt 🗂️ | Warum es wichtig ist 🎯 | Team-Erkenntnis 🧰 |
|---|---|---|
| Wer / Wann / Warum Labels | Strukturierte RCA über Agenten hinweg | Standardisierte Nachbesprechungen |
| Vielzahl an Topologien | Testet Methoden unter Belastung | Auf eigene Architektur abstimmen |
| Variation der Kontextlänge | Misst Skalierungsgrenzen | Pläne aufteilen/verdichten |
| Open-Source-Pipelines | Reproduzierbare Baselines | Übernehmen, dann anpassen |
Für eine schnelle Orientierung bei Multi-Agent-Debugging-Mustern und Attributionszielen kann folgende Suche helfen, relevante Vorträge und Demos aus der Community zu finden.
Die Stärke des Datensatzes liegt in der Brücke zwischen akademischer Strenge und Praxistauglichkeit: Teams können das Schema direkt in ihre Incident-Tools übernehmen und den Kreislauf von „Auswertung“ zu „Verbesserung“ schließen.
Drei Strategien zur automatisierten Attribution: Alles-auf-einmal, Schritt-für-Schritt und Binäre Suche
Mit dem Benchmark evaluierten die Teams drei Strategien für Automatisierte Attribution. Jede spiegelt eine andere Philosophie des Lesens und Schlussfolgerns über Protokolle wider. Die Alles-auf-einmal-Methode übergibt das gesamte Gespräch und die Nutzeranfrage an ein Modell (z.B. GPT-4o) und fordert Wer und Wann auf einmal plus eine optionale Erklärung an. Sie ist in der Steuerung günstig, kann aber feinkörnige Fehler bei langen Kontexten oder subtilen Widersprüchen in Rollenübergaben übersehen.
Die Schritt-für-Schritt-Strategie ahmt menschliches Debugging nach: sie geht das Protokoll sequenziell durch, bewertet jeden Schritt und stoppt, wenn ein entscheidender Fehler erscheint. Sie lokalisieren den genauen Schritt meist besser, erhöht aber Token-Kosten und birgt das Risiko von Fehlerakkumulation bei mehrstufigen Urteilen. Man kann sie als gewissenhaften Prüfer sehen, der Geschwindigkeit gegen Genauigkeit eintauscht.
Ein Mittelweg ist die Binäre Suche. Sie teilt das Protokoll in zwei Hälften, fragt das Modell, in welchem Segment der Fehler liegt, und führt dann eine Rekursion durch. So wird der Kontext schnell eingegrenzt, ohne alles auf einmal lesen zu müssen. Sie balanciert meist Kosten und Genauigkeit gut aus, ist aber empfindlich bei unscharfen Grenzen – z.B. wenn eine Fehlinterpretation früher beginnt, sich aber später zeigt.
Die Wahl hängt von Vorgaben ab. Optimieren Teams für Kosten und Entwicklungszeit, ist Alles-auf-einmal ein guter Start, insbesondere wenn Eingabeaufforderungen explizites Reasoning verlangen. Liegt der Fokus auf präziser Fehlerlokalisierung in sicherheitskritischen Abläufen, gewinnt Schritt-für-Schritt. Binäre Suche ist attraktiv für lange Protokolle mit klaren semantischen Breakpoints (Planung vs. Ausführung). Hybride—wie Alles-auf-einmal zur Agentenbestimmung und Schritt-für-Schritt zur Zeitlokalisierung—glänzen oft, kosten aber mehr Rechenleistung.
- ⚙️ Alles-auf-einmal: einfache Steuerung; auf Kontextlimits achten.
- 🧭 Schritt-für-Schritt: höhere Präzision beim „Wann“; kumulative Fehler beobachten.
- ✂️ Binäre Suche: effiziente Eingrenzung; empfindlich bei unscharfen Grenzen.
- 🧪 Hybrid: Stärken kombinieren; mehr Token- und Zeitkosten.
| Methode 🔬 | Stärke 💪 | Risiko ⚠️ | Bestes Einsatzgebiet 🚀 |
|---|---|---|---|
| Alles-auf-einmal | Geringe Koordination, schnell | Verpasst subtile Schrittfehler | Kurz- bis mittellange Protokolle |
| Schritt-für-Schritt | Schrittpräzision | Token- und Latenzkosten | Sicherheitskritische Audits |
| Binäre Suche | Skaliert bei langen Protokollen | Unklare Segmentierung | Tiefe Spuren mit Umschlagspunkten |
| Hybrid | Beste aus beiden Welten | Rechenintensiv | Hochrisikovorfälle |
Die praktische Faustregel ist, alle drei zu instrumentieren und je nach Spurgröße und Risiko einzusetzen: kurze Spuren für Alles-auf-einmal, lange Spuren für Binäre Suche und kritische Abläufe für Schritt-für-Schritt. Diese Strategie fängt schnelle Erfolge ein, bewahrt aber hohe Präzision dort, wo sie nötig ist.

Experimentelle Ergebnisse und realweltliche Anwendungsfälle: Was scheitert, wer scheitert und wann
Im Who&When-Datensatz erreichte eine einzelne Bestmethode ca. 53,5% Genauigkeit bei der Identifikation des verantwortlichen Agenten und ca. 14,2% bei der Bestimmung des genauen Fehler-Schrittes—besser als viele Baselines, aber weit vom produktionsreifen Ideal entfernt. Bemerkenswert ist, dass auch starke Reasoning-Modelle wie OpenAI o1 und DeepSeek R1 mit nuancierten, mehrstufigen Kausalitäten Schwierigkeiten hatten. Diese Lücke unterstreicht den Unterschied zwischen Lösung von Aufgaben und Erklärung von Fehlern im Agentenkollektiv.
Zwei Hebel halfen konstant: Das Einfordern von explizitem Reasoning in Eingabeaufforderungen (z.B. chain-of-thought-artige Begründungen) und die Einschränkung des Kontexts durch Chunking oder geführte Navigation. Die Leistung fiel jedoch bei längeren Protokollen, besonders beim Label „Wann“, ab—ein Beleg dafür, dass zeitliche Lokalisierung der schwierigste Teil bleibt. Die Binäre Suche-Strategie milderte Kontextüberlastung, während Schritt-für-Schritt zeitliche Präzision auf Kosten höherer Ressourcen verbesserte.
Im praktischen Einsatz betrachtet man „Orion Labs“, ein hypothetisches Analyseunternehmen, das einen Multi-Agenten-Berichtsgenerator baut. Ein Planer erstellt einen Datenplan, ein Retriever holt Tabellen, ein Schreiber verfasst eine Erzählung und ein Verifizierer prüft die Konsistenz. Ein Kunde merkt, dass der Quartalsumsatz in einer Region falsch ist. Die Attribution zeigt, dass der Retriever nach einem Werkzeugaufruf ein veraltetes Schema nutzte. Der entscheidende Fehler-Schritt lag mitten in der Spur, aber das Symptom zeigte sich erst bei der abschließenden Überprüfung. Mit automatischer Diagnose verdrahtet Orion den Retriever so um, dass die Schema-Version beim Abruf validiert wird und bei Versionskonflikten ein harter Fehler ausgelöst wird.
Hybride Strategien fanden ebenfalls Anwendung: Erstens Alles-auf-einmal, um den wahrscheinlichsten Agenten zu nominieren, dann Schritt-für-Schritt nur zur Lokalisierung des Zeitpunkts bei diesem Agenten. Das Hybrid erhöhte die Genauigkeit in mehreren Fällen, obwohl die Token-Kosten stiegen. Teams bewerteten den Kompromiss, indem sie wertvolle Vorfälle an Hybride und Routinefehler an günstigere Methoden leiteten.
- 📉 Realitätscheck: Aufgabenattribution ist für aktuelle Modelle schwieriger als Aufgabenausführung.
- 🧠 Explizites Reasoning verbessert sowohl „Wer“ als auch „Wann“.
- 🧱 Kontextlänge bleibt limitierend; Chunking hilft.
- 🧯 Hybride arbeiten am besten bei kritischen Vorfällen trotz höherer Kosten.
| Erkenntnis 🔎 | Beleg 📊 | Folgerung 🧭 |
|---|---|---|
| „Wer“ einfacher als „Wann“ | 53,5% vs. 14,2% | Priorität auf Lokalisierungsschritte legen |
| Reasoning hilft | Bessere Resultate mit expliziten Begründungen | Rationale Eingabeaufforderungen verpflichten |
| Kontext schadet | Längere Protokolle verschlechtern die Genauigkeit | Binäre Suche + Zusammenfassung einsetzen |
| Hybride lohnen sich | Verbesserte kombinierte Genauigkeit | Hochrisiko-Vorfälle an Hybrid-Strategie leiten |
Für weitere Perspektiven zu komplexen Systemausfällen und Diagnose-Workflows hilft diese Suche, Vorträge und Fallstudien für Praktiker und Forscher sichtbar zu machen.
Das Fazit: Attribution ist nun messbar. Auch wenn die Werte bescheiden sind, wird der Weg zu betriebssicherer Zuverlässigkeit empirisch und iterativ.
Umsetzbares Playbook für Entwickler: Von Systemdiagnosen zur kontinuierlichen Zuverlässigkeit
Die Umsetzung aus Forschung in die Praxis beginnt mit einer Pipeline-Mentalität. Behandeln Sie Automatisierte Attribution als Standardstufe im CI bei Multi-Agenten-Releases. Erfassen Sie Protokolle, normalisieren Sie Rollen und führen Sie Attribution automatisch nach jedem fehlgeschlagenen Lauf durch. Wandeln Sie Ergebnisse dann in Tickets um, die Agent, Schritt und kurze „Warum“-Erklärung spezifizieren. So entsteht nach und nach ein lebendiger Katalog von Fehler-Motiven—falsche Eingaben, veraltete Werkzeuge, brüchige Übergaben—die das Engineering systematisch beseitigen kann.
Betrachten Sie ein praktisches Rollout. Beginnen Sie bei kurzen Protokollen mit Alles-auf-einmal und fügen Sie Binäre Suche ab einer Kontextlänge hinzu. Für kundennahe oder sicherheitskritische Workflows aktivieren Sie Schritt-für-Schritt oder einen Hybrid. Bündeln Sie Eingabeaufforderungen, die explizites Reasoning verlangen, fordern Sie Modellurteile mit Protokollzitat an und cachen Sie Teilanalysen zur Kostenkontrolle. Wo möglich, fügen Sie leichte Validatoren an sensiblen Stellen hinzu: Schema-Versionen prüfen, Unit-Tests für Werkzeug-Ausgaben und Schutzvorrichtungen, die unklare Übergaben blockieren.
Prompt- und Datenhygiene sind wichtig. Nutzen Sie intern das Who&When-Schema, damit Nachbesprechungen zwischen Teams konsistent bleiben. Ermutigen Sie Agenten, kurze, maschinenparsbare Begründungen zu schreiben (z.B. JSON mit „Anspruch“, „Beleg“, „Zuversicht“). Protokollieren Sie Werkzeug-Metadaten—Version, Endpunkt, Latenz—damit Attribution zwischen Agentenlogikfehlern und Infrastrukturproblemen unterscheiden kann. In Multi-Tenant-Umgebungen bereinigen Sie personenbezogene Daten, bevor Sie Spuren in gemeinsame Benchmarks exportieren.
Schließlich stimmen Sie Stakeholder ab. Produkt priorisiert Szenarien nach Nutzerimpact, Forschung fokussiert die schwersten „Wann“-Lokalisierungen und Operations pflegt Dashboards mit Vorfallraten nach Agent und Schritt. Führungsebene erhält Trendlinien: Mit steigendem Attributionsgrad sinkt die mittlere Behebungszeit (MTTR). Über Monate wandelt sich die Organisation von reaktiver Fehlerbehebung zu proaktiver Vermeidung – unterstützt durch messbare Diagnosen.
- 🧪 Klein starten: Pilot auf einem hochfrequenten Workflow vor Skalierung.
- 🪜 Stufenweise Policy: Routing nach Protokolllänge und Geschäftsrisko.
- 🧰 Tooling: Validatoren und typisierte Übergaben an fragilen Stellen ergänzen.
- 📈 Metriken: Attributiongenauigkeit und MTTR zusammen verfolgen.
| Phase 🚀 | Was umsetzen 🧩 | Ergebnis 🎯 |
|---|---|---|
| Instrumentierung | Strukturierte Protokolle, Rollentags, Werkzeug-Metadaten | Saubere Eingaben für Attribution |
| Attributions-Engine | Alles-auf-einmal + Binäre Suche + Schritt-für-Schritt | Abdeckung unterschiedlicher Protokollformen |
| Schutzvorrichtungen | Schema-Prüfungen, Werkzeug-Unittests, typisierte Übergaben | Weniger wiederkehrende Fehler |
| Operationen | Automatisches Ticketing mit Wer/Wann/Warum | Schnellere, fokussierte Fehlerbehebungen |
| Lernschleife | Trend-Dashboards, A/B-Agentenwechsel | Kontinuierliche Zuverlässigkeitssteigerungen |
Ground Truth steht im Produktionsbetrieb nicht immer zur Verfügung, bevorzugen Sie daher Methoden, die robust bei Unsicherheiten sind, und investieren Sie in synthetische Auswertungen, die Ihr Risikoprofil abbilden. Attribution ist nicht nur ein Forschungserfolg; sie ist ein praktischer Hebel, um Intelligente Systeme in großem Maßstab zuverlässig zu machen.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Was unterscheidet automatisierte Fehlerattribution vom Standard-Debugging?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Sie formalisiert Verantwortung und Zeitpunkt—identifiziert den genauen Agenten (Wer) und den entscheidenden Schritt (Wann)—und koppelt diese mit einer kurzen Erklärung (Warum). Das verwandelt freie Log-Analysen in strukturierte Systemdiagnosen, die für Metriken, Audits und Automatisierung geeignet sind.”}},{“@type”:”Question”,”name”:”Wie bewerten PSU und Duke Methoden fair?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Sie verwenden den Who&When-Benchmark mit zwei Modi: Mit Ground Truth (das Modell kennt die korrekte Antwort) und Ohne Ground Truth (das Modell nutzt nur den Prozess). So wird das reasoning unabhängig von reiner Antwortsuche bewertet und Vergleiche bleiben konsistent.”}},{“@type”:”Question”,”name”:”Warum haben starke Modelle wie OpenAI o1 und DeepSeek R1 immer noch Schwierigkeiten?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Attribution erfordert mehrstufiges kausales Denken und zeitliche Lokalisierung über lange Kontexte. Diese Anforderungen sind schwieriger als das Erzeugen einer finalen Antwort, besonders wenn Fehler sich indirekt durch Werkzeugnutzung kumulieren.”}},{“@type”:”Question”,”name”:”Wann sollte ein Team Binäre Suche gegenüber Schritt-für-Schritt bevorzugen?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Nutzen Sie Binäre Suche für lange Protokolle, wo Fehler wahrscheinlich hinter semantischen Hauptgrenzen liegen (Planung vs. Ausführung). Wählen Sie Schritt-für-Schritt, wenn Präzision beim exakten Schritt wichtiger ist als Kosten oder Latenz.”}},{“@type”:”Question”,”name”:”Wo können Entwickler mit den offenen Ressourcen starten?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Lesen Sie das ICML 2025 Spotlight-Paper, klonen Sie das GitHub-Repo für Pipelines und laden Sie den Who&When-Datensatz von Hugging Face. Beginnen Sie damit, Ihre eigene Agent-Topologie zu spiegeln und verwenden Sie das Who/Wann/Warum-Schema für interne Nachbesprechungen.”}}]}Was unterscheidet automatisierte Fehlerattribution vom Standard-Debugging?
Sie formalisiert Verantwortung und Zeitpunkt—identifiziert den genauen Agenten (Wer) und den entscheidenden Schritt (Wann)—und koppelt diese mit einer kurzen Erklärung (Warum). Das verwandelt freie Log-Analysen in strukturierte Systemdiagnosen, die für Metriken, Audits und Automatisierung geeignet sind.
Wie bewerten PSU und Duke Methoden fair?
Sie verwenden den Who&When-Benchmark mit zwei Modi: Mit Ground Truth (das Modell kennt die korrekte Antwort) und Ohne Ground Truth (das Modell nutzt nur den Prozess). So wird das reasoning unabhängig von reiner Antwortsuche bewertet und Vergleiche bleiben konsistent.
Warum haben starke Modelle wie OpenAI o1 und DeepSeek R1 immer noch Schwierigkeiten?
Attribution erfordert mehrstufiges kausales Denken und zeitliche Lokalisierung über lange Kontexte. Diese Anforderungen sind schwieriger als das Erzeugen einer finalen Antwort, besonders wenn Fehler sich indirekt durch Werkzeugnutzung kumulieren.
Wann sollte ein Team Binäre Suche gegenüber Schritt-für-Schritt bevorzugen?
Nutzen Sie Binäre Suche für lange Protokolle, wo Fehler wahrscheinlich hinter semantischen Hauptgrenzen liegen (Planung vs. Ausführung). Wählen Sie Schritt-für-Schritt, wenn Präzision beim exakten Schritt wichtiger ist als Kosten oder Latenz.
Wo können Entwickler mit den offenen Ressourcen starten?
Lesen Sie das ICML 2025 Spotlight-Paper, klonen Sie das GitHub-Repo für Pipelines und laden Sie den Who&When-Datensatz von Hugging Face. Beginnen Sie damit, Ihre eigene Agent-Topologie zu spiegeln und verwenden Sie das Who/Wann/Warum-Schema für interne Nachbesprechungen.



entdecke die faszinierendsten Muschelnamen und ihre Bedeutungen
Entschlüsselung der verborgenen Daten mariner Architekturen Der Ozean fungiert als ein riesiges, dezentralisiertes Archiv biologischer Geschichte. Innerhalb dieses Raums sind...


Funko pop Nachrichten: Neueste Veröffentlichungen und exklusive Drops im Jahr 2025
Wichtige Funko Pop Neuigkeiten 2025 und die andauernde Wirkung in 2026 Die Landschaft des Sammelns hat sich in den letzten...


wer ist hans walters? die geschichte hinter dem namen im jahr 2025 enthüllt
Das Rätsel um Hans Walters: Analyse des digitalen Fußabdrucks im Jahr 2026 Im weiten Informationsraum von heute präsentieren nur wenige...


Exploring microsoft building 30: ein Zentrum für Innovation und Technologie im Jahr 2025
Die Neugestaltung des Arbeitsplatzes: Im Herzen der technologischen Entwicklung Redmonds Eingebettet in das Grün des weitläufigen Redmond-Campus stellt Microsoft Building...


Top KI-Tools zur Hausaufgabenhilfe im Jahr 2025
Die Entwicklung von KI zur Unterstützung von Schülern im modernen Klassenzimmer Die Panik vor einer Sonntagnacht-Abgabefrist wird langsam zur Vergangenheit....


OpenAI vs Mistral: Welches KI-Modell passt 2025 am besten zu Ihren Anforderungen an die Verarbeitung natürlicher Sprache?
Die Landschaft der Künstlichen Intelligenz hat sich 2026 dramatisch verändert. Die Rivalität, die das letzte Jahr prägte – insbesondere der...


wie man sich verabschiedet: sanfte Wege, Abschiede und Enden zu bewältigen
Die Kunst eines sanften Abschieds im Jahr 2026 meistern Abschied zu nehmen ist selten eine einfache Aufgabe. Ob Sie nun...


piratenschiff name generator: erstelle noch heute den legendären Namen deines Schiffs
Die perfekte Identität für dein maritimes Abenteuer gestalten Ein Schiff zu benennen ist weit mehr als eine einfache Beschriftung; es...


Kreativität freisetzen mit Diamond Body AI-Prompts im Jahr 2025
Meisterung des Diamond Body Frameworks für KI-Präzision Im sich schnell entwickelnden Umfeld des Jahres 2025 liegt der Unterschied zwischen einem...


Was ist Canvas? Alles, was Sie 2025 wissen müssen
Definition von Canvas im modernen digitalen Unternehmen Im Umfeld des Jahres 2026 hat sich der Begriff „Canvas“ über eine einzelne...


wie man die Tastaturbeleuchtung Ihres Laptops einschaltet: eine Schritt-für-Schritt-Anleitung
Meisterung der Tastaturbeleuchtung: Der unverzichtbare Schritt-für-Schritt-Leitfaden Das Tippen in einem schwach beleuchteten Raum, auf einem Nachtflug oder während einer späten...


beste Buch-Mockup-Aufforderungen für Midjourney im Jahr 2025
Optimierung der digitalen Buchvisualisierung mit Midjourney in der Post-2025-Ära Die Landschaft der digitalen Buchvisualisierung hat sich nach den algorithmischen Updates...


KI-gesteuerte Erwachsenenvideo-Generatoren: Die wichtigsten Innovationen, auf die man 2025 achten sollte
Der Beginn synthetischer Intimität: Neuinterpretation von Inhalten für Erwachsene im Jahr 2026 Das Feld des digitalen Ausdrucks hat einen grundsätzlichen...


ChatGPT vs LLaMA: Welches Sprachmodell wird 2025 dominieren?
Die kolossale Schlacht um die KI-Vorherrschaft: Offene Ökosysteme vs. Geschlossene Gärten Im sich schnell entwickelnden Umfeld der künstlichen Intelligenz ist...


Meisterung der ersten ch-Wörter: Tipps und Aktivitäten für frühe Leser
Entschlüsselung des Mechanismus der anfänglichen CH-Wörter in der frühen Alphabetisierung Spracherwerb bei frühen Lesern funktioniert bemerkenswert wie ein komplexes Betriebssystem:...


Howmanyofme Bewertung: Entdecken Sie, wie einzigartig Ihr Name wirklich ist
Die Geheimnisse deiner Namensidentität mit Daten entschlüsseln Dein Name ist mehr als nur ein Etikett auf dem Führerschein; er ist...


Verstehen des GPT-2-Ausgabedetektors: wie er funktioniert und warum er im Jahr 2025 wichtig ist
Die Mechanik hinter dem GPT-2 Output Detector im Zeitalter der generativen KI Im sich schnell entwickelnden Umfeld des Jahres 2026...


Wie man Pirate Weather mit Home Assistant integriert: eine vollständige Schritt-für-Schritt-Anleitung
Die Entwicklung hyperlokaler Wetterdaten in Smart-Home-Ökosystemen Zuverlässigkeit ist das Fundament jeder effektiven Smart Home-Einrichtung. Im Jahr 2026, in dem die...


2025 Leitfaden zu den besten NSFW AI Art Creators: Trends und unverzichtbare Tools
Die Entwicklung der digitalen Erotik und der technologische Wandel im Jahr 2025 Die Landschaft der Digital Art hat einen gewaltigen...


OpenAI vs Meta: Erforschung der wichtigsten Unterschiede zwischen ChatGPT und Llama 3 im Jahr 2025
Die KI-Landschaft Ende 2025: Ein Kampf der Giganten Der Bereich der künstlichen Intelligenz hat seit der Veröffentlichung von Meta’s Llama...
-

 Open Ai7 days ago
Open Ai7 days agoEntfesselung der Power von ChatGPT-Plugins: Verbessern Sie Ihr Erlebnis im Jahr 2025
-

 Open Ai6 days ago
Open Ai6 days agoMastering GPT Fine-Tuning: Ein Leitfaden zur effektiven Anpassung Ihrer Modelle im Jahr 2025
-
 Open Ai6 days ago
Open Ai6 days agoVergleich von OpenAIs ChatGPT, Anthropics Claude und Googles Bard: Welches generative KI-Tool wird 2025 die Vorherrschaft erlangen?
-

 Open Ai6 days ago
Open Ai6 days agoChatGPT-Preise im Jahr 2025: Alles, was Sie über Tarife und Abonnements wissen müssen
-

 Open Ai6 days ago
Open Ai6 days agoDas Auslaufen der GPT-Modelle: Was Nutzer im Jahr 2025 erwartet
-

 KI-Modelle6 days ago
KI-Modelle6 days agoGPT-4-Modelle: Wie Künstliche Intelligenz das Jahr 2025 verändert