

Actualités
Des conversations étranges avec ChatGPT apparaissent dans Google Analytics : des journaux de chat maladroits fuitent en ligne
Les requêtes ChatGPT apparaissent dans les workflows de Google Analytics : comment des invites maladroites se sont retrouvées dans Search Console
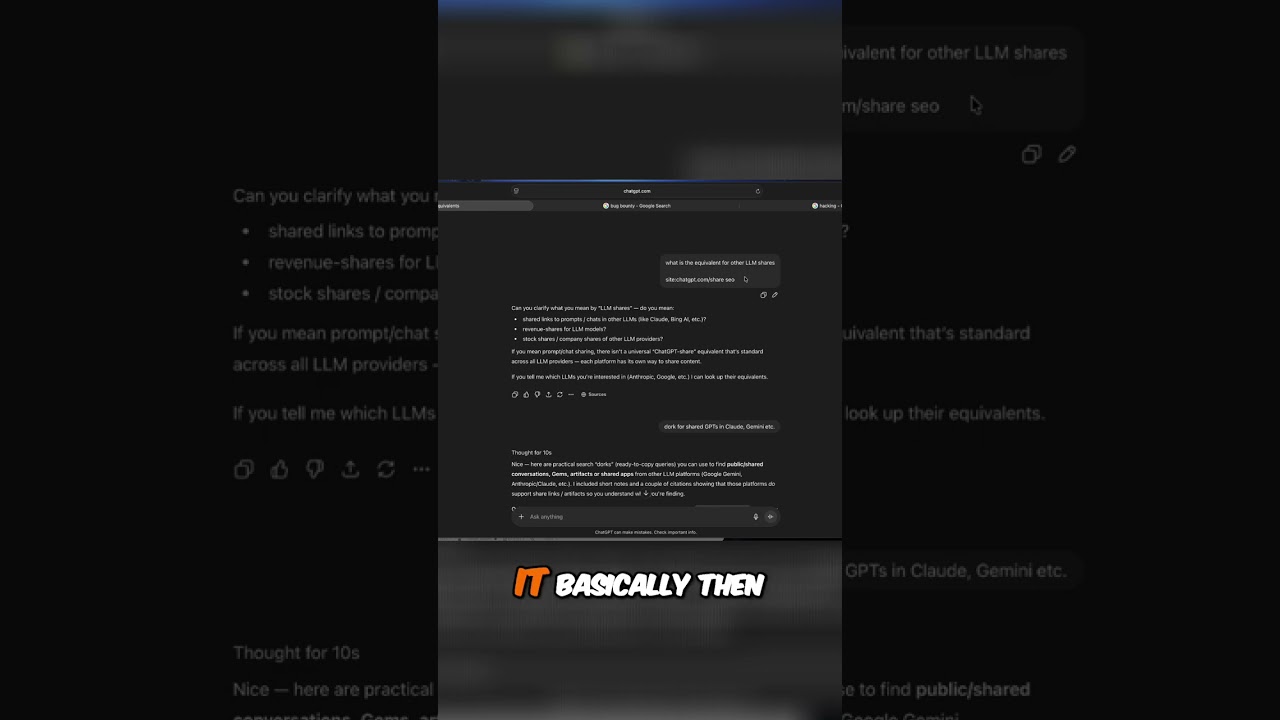
Ce qui ressemblait à une journée d’analyse typique est devenu étrange lorsque les conversations IA ont commencé à apparaître à des endroits où elles ne devraient jamais se trouver : les journaux de requêtes dans les workflows de Google Analytics liés à Search Console. Les développeurs examinant les rapports de performance ont découvert des chaînes extrêmement longues — parfois plus de 300 caractères — reflétant des invites brutes de ChatGPT portant sur des relations, des conflits en milieu de travail, voire des brouillons de politique RTO. Ce n’étaient pas des extraits copiés de billets de blog ; cela ressemblait à des saisies utilisateur directes qui avaient en quelque sorte glissé dans les chemins d’indexation de Google avant de réapparaître dans les rapports de Google Search Console (GSC) liés aux tableaux de bord SEO et, pour certaines équipes, exportés dans des piles de reporting connectées à Google Analytics.
Les analystes ont remarqué un préfixe particulier attaché à beaucoup de ces chaînes : une trace tokenisée pointant vers une URL OpenAI que les moteurs de recherche fractionnaient en termes tels que « openai + index + chatgpt ». Tout site positionné sur ces mots-clés pouvait voir les invites « fuitées » apparaître dans GSC. Le résultat était surréaliste : un outil SEO utilisé pour surveiller la performance organique est devenu par inadvertance une lucarne sur des artefacts privés semblant être une fuite de données. La partie la plus inquiétante ? Plusieurs invites étaient manifestement sensibles. Il y avait des confessions, des noms, des détails commerciaux — du contenu jamais destiné à sortir de la fenêtre du chat.
Des enquêteurs indépendants — un consultant en analytics et un expert en optimisation web — ont testé le schéma et ont émis l’hypothèse qu’une interface de chat boguée ajoutait l’URL de la page à l’invite et déclenchait plus agressivement les recherches web via un paramètre hints. Si ChatGPT décidait qu’il devait naviguer, cette invite pouvait être redirigée vers la recherche publique, et des traces pouvaient ensuite réapparaître dans GSC où des domaines étaient positionnés pour le préfixe tokenisé. OpenAI a ensuite reconnu un problème de routage affectant un petit nombre de requêtes et a indiqué qu’il avait été résolu. Pourtant, la pièce manquante reste : combien d’invites ont été affectées, et pendant combien de temps ?
Les équipes intégrant les données GSC avec Google Analytics ont ressenti l’impact de la manière la plus désordonnée — à travers des tableaux de bord et des outils BI reflétant soudainement des chaînes hors sujet, profondément personnelles. Alors que des incidents passés impliquaient des utilisateurs choisissant explicitement de partager ou d’indexer des chats, ce schéma a pris de court les propriétaires de sites qui n’ont jamais cliqué sur un bouton de partage. Pour les équipes centrées sur la confidentialité, cet épisode souligne une vérité fragile : des invites apparemment privées peuvent emprunter des chemins très publics si la logique de navigation d’un produit se dérègle.
Ce qui a alerté les analystes en premier
Les premiers signaux d’alerte incluaient des pics d’impressions sur des mots-clés non liés, des écarts impression-clic (« motif bouche de crocodile »), et des préfixes étranges qui ne correspondaient pas à la taxonomie du site. En somme, les invites de chat — conçues pour être éphémères — laissaient des miettes durables dans la télémétrie SEO, puis s’immisçaient dans les conversations de criminalistique numérique au sein des équipes de sécurité et de marketing.
- 🔎 Requêtes longues, étranges, ressemblant à des messages complets adressés à ChatGPT
- 📈 Pics d’impressions avec un CTR dérisoire sur des termes non pertinents
- 🧩 Un préfixe constant suggérant des éléments tokenisés de page OpenAI
- 🛡️ Alertes de gouvernance des données émises par les équipes de cybersécurité ou de conformité
- 🧭 Attribution conflictuelle dans les exports entre Google Analytics et GSC
| Chronologie ⏱️ | Symptôme 🧪 | Où vu 🔭 | Niveau de risque ⚠️ |
|---|---|---|---|
| Phase de découverte | Invites apparaissant comme requêtes | GSC lié à Google Analytics | Élevé 😬 |
| Enquête | Motif de préfixe tokenisé | Rapport des requêtes principales | Moyen 😕 |
| Réponse du fournisseur | Bogue de routage reconnu | Déclarations officielles | Variable 🤔 |
| Remédiation | Filtrage et alertes | Chaînes analytiques | Plus bas 🙂 |
Pour les lecteurs comparant les bonnes pratiques, des guides pratiques comme conseils pour le playground et un examen sincère des regrets après avoir partagé des plans de voyage avec un bot offrent des étapes solides pour un usage plus sûr. Un guide plus large sur les chatbots IA non filtrés ajoute du contexte sur les limites lors d’expérimentations avec des liens de partage publics.
La leçon clé de cet incident est simple : si un modèle navigue, le texte des invites peut voyager ; sans garde-fous, une partie peut revenir en boomerang dans la télémétrie publique.

Pas la même chose que “Partager sur le Web” : pourquoi cette exposition est plus étrange — et pourquoi cela compte
Les controverses antérieures tournaient autour d’un paramètre explicite « partager » ou « découvrable » permettant aux fils ChatGPT de devenir des pages publiques indexées par les moteurs de recherche. C’était un comportement opt-in — même si l’interface pouvait semer la confusion chez certains utilisateurs. Cette fois, le problème semble structurellement différent. De longues chaînes de requêtes ressemblant à de vraies invites ont émergé dans Google Search Console via la tokenisation des mots-clés et le comportement de navigation, sans passer par des pages de chat publiées publiquement. Pas de bouton « Publier ». Pas de partage social. Juste du texte brut d’invite apparaissant dans un outil SEO conçu pour suivre comment les chercheurs trouvent du contenu.
Les experts en confidentialité appellent cela le chevauchement cauchemardesque : un produit qui navigue sur le web rencontre un pipeline de recherche qui interprète tout comme un signal potentiel. Si le routage est mal configuré, le texte des invites ne touche pas seulement des services tiers, il peut laisser des traces que l’analyse en aval ne peut ignorer. Même après que OpenAI ait déclaré avoir corrigé le bogue de routage, les analystes se sont posés les questions évidentes : tous les points de terminaison ont-ils été couverts ? Les invites venant à la fois de chatgpt.com et des clients mobiles ont-elles été routées de manière similaire ? Des scrappers tiers auraient-ils pu copier les mêmes flux ?
La couverture médiatique en 2025 reflète cette division : certains médias mettent l’accent sur la remédiation rapide et passent à autre chose ; d’autres soulignent le risque systémique plus large. Que l’on penche vers la responsabilisation produit à la TechCrunch ou le regard culturel à la Wired, la question clé reste la même : comment les assistants avec navigation doivent-ils gérer le texte des invites à la frontière réseau pour qu’aucune console analytique ne devienne jamais un miroir des pensées privées ?
Différences clés que les utilisateurs doivent comprendre
Concrètement, les entreprises doivent distinguer la publication volontaire et l’exposition fortuite via la télémétrie. Les équipes de sécurité doivent aussi savoir où les invites peuvent apparaître — caches des navigateurs, journaux DNS, connecteurs de recherche des fournisseurs — et comment les contrôles comme la prévention de perte de données (DLP) s’appliquent aux workflows avec navigation par modèle.
- 🧭 Le partage opt-in crée des pages indexées ; cet incident a routé des invites dans les chemins de recherche
- 🔐 Les attentes en matière de confidentialité en ligne diffèrent profondément entre « publication sur le web » et « navigation par modèle »
- 🧰 Les corrections doivent viser le routage réseau, pas seulement la visibilité des liens partagés
- 🔍 La criminalistique numérique doit auditer où le texte d’invite peut persister dans les journaux
- 📚 La formation du personnel doit inclure les risques du mode navigation, pas seulement l’hygiène autour des liens de partage
| Scénario 🧩 | Action utilisateur 🖱️ | Vecteur d’exposition 🌐 | Remède ✅ |
|---|---|---|---|
| Page de chat partagée | Partage explicite | URL publique indexée | Désactivation + désindexation 😌 |
| Écho d’invite induit par la navigation | Pas de partage | Routage recherche + journaux | Correction réseau + hygiène des journaux 🧽 |
| Scrapper tiers | Aucun | Copie des traces exposées | Demandes de suppression + listes de blocage 🛑 |
Les organisations évaluant des workflows basés sur des modèles peuvent croiser des feuilles de route opérationnelles telles que insights d’entreprise avec ChatGPT, des techniques de fine-tuning pour 2025, et le guide pratique sur les navigateurs IA et la cybersécurité. Chaque ressource renforce un mantra simple : la confidentialité est une décision d’architecture, pas un interrupteur caché dans les réglages.
Au fur et à mesure que l’incident se stabilise, l’enseignement le plus utile est un langage précis : ce n’était pas une erreur de publication utilisateur — c’était une exposition due à la navigation et au routage qui se comportait comme une fuite de données du point de vue de la télémétrie analytique.

Conséquences business : bruit SEO, pression sur la conformité et le problème de la “bouche de crocodile”
Les entreprises synchronisant GSC avec Google Analytics ont immédiatement ressenti du bruit dans leurs KPI. Les comptes d’impressions ont gonflé sur des chaînes longues et non pertinentes — mais les clics n’ont pas suivi. Cet écart croissant, connu des SEO comme la « bouche de crocodile », a embrouillé les rapports pour les revues hebdomadaires et les OKR. Les équipes marketing ont dû expliquer ces anomalies à des cadres qui voulaient des récits nets, pas des mises en garde à propos d’artefacts d’invite.
Au-delà du cosmétique, les responsables compliance ont vu des impacts potentiels sur la confidentialité en ligne. Si le texte des invites contient des identifiants personnels et que ce texte est traité dans des systèmes tiers, les équipes privacy doivent évaluer si ce traitement respecte les exigences de consentement et de minimisation. La matrice de risque s’élargit : accords de confidentialité, données clients, et détails de produits pré-lancement sont tous des éléments que les collaborateurs rédigent parfois avec ChatGPT. La présence d’un contenu similaire dans les outils SEO — même sous forme de traces non cliquables — soulève de sérieuses questions.
Considérez un détaillant fictif d’habillement, Northbridge Outfitters. Leur équipe de contenu utilise un modèle pour affiner les textes saisonniers. Un après-midi, l’analyste SEO voit dans GSC des requêtes qui ressemblent étrangement à des invites de brainstorming sur une collaboration à venir non lancée. La marque n’a fuité aucune page de destination. Mais ces invites existent désormais dans un système partagé avec des agences et des fournisseurs BI. L’équipe juridique intervient, et les plans de lancement sont retardés tandis que les journaux sont examinés et les politiques d’exportation resserrées.
Actions immédiates entreprises par les équipes
Pour retrouver la clarté des signaux, les équipes ont été pragmatiques : filtres, règles regex, et alertes. Elles ont documenté le motif du préfixe tokenisé et l’ont exclu des tableaux de bord, puis ouvert des tickets internes pour examiner quelles données GSC circulent vers Google Analytics et où.
- 🧹 Appliquer des filtres au niveau des vues pour supprimer les chaînes ressemblant à des invites
- 🧪 Effectuer une comparaison avant/après incident des impressions sur les termes sensibles
- 🔐 Suspendre les exports des données GSC vers les BI partagées jusqu’à assainissement
- 📝 Mettre à jour les runbooks analytiques pour inclure les scénarios de débordement des conversations IA
- 🚨 Créer une étiquette incident pour les rapports rétroactifs dans les présentations exécutives
| Partie prenante 👥 | Risque principal 🧨 | Plan d’action 🗂️ | Résultat 🎯 |
|---|---|---|---|
| SEO/Analytics | KPI faussés | Filtres + annotations | Tableaux de bord plus propres 😊 |
| Juridique/Privacy | Traitement des données personnelles | Revue DPIA + QA fournisseur | Exposition réduite 🛡️ |
| Sécurité | Flux de données involontaires | Vérifications des politiques réseau | Itinéraires renforcés 🔒 |
| Communication | Risque réputationnel | Communiqué contrôlé | Confiance des parties prenantes 🤝 |
Pour le contexte stratégique sur les choix de modèles et les engagements des fournisseurs, les lecteurs consultent souvent une revue ChatGPT 2025, comparent ChatGPT et Perplexity AI en 2025, et examinent des playbooks d’entreprise comme l’efficacité projet Azure ChatGPT. Comprendre les niveaux tarifaires et le langage des SLA est aussi important ; un aperçu sur les tarifs ChatGPT en 2025 aide les équipes d’achat à faire correspondre budget et contrôles de risque.
La leçon opérationnelle est claire : traiter les assistants avec navigation comme tout autre processeur de données tiers — avec contrôles, contrats et mesure constante du risque résiduel.
Un playbook de criminalistique numérique : vérifier, délimiter et contenir la télémétrie des invites
Quand les équipes analytiques rencontrent des invites semblant humaines dans les journaux de requêtes, la criminalistique numérique entre en jeu. La première étape est la vérification : confirmer que les chaînes ne sont pas des recherches générées par les utilisateurs du site ou des données de test internes. Ensuite, les analystes suivent les miettes — préfixes tokenisés, grappes temporelles, chemins d’impression à travers les régions. L’objectif est d’établir la portée sans contaminer les preuves ni violer davantage la confidentialité des utilisateurs.
Une procédure simple fonctionne bien. Maintenir un export propre des requêtes GSC pour la période, hacher le jeu de données et le stocker dans un bac à preuves sécurisé. Construire une signature regex pour le préfixe suspecté, puis taguer toutes les correspondances. Croiser avec les journaux de modifications pour toute mise à jour fournisseur, nouvelle fonctionnalité de navigation ou flags A/B. Enfin, interroger les parties prenantes pour savoir qui a remarqué les anomalies en premier et si des captures d’écran ou des e-mails d’alerte existent. En externe, suivre la couverture médiatique de sources comme Wired et TechCrunch pour des mises à jour autorisées et des conseils de mitigation.
Étapes d’enquête reproductibles
Les équipes adaptent souvent ce plan pour passer de la confusion à la clarté sans collecter excessivement de données sensibles. Garder le focus sur les métadonnées, pas le contenu, et minimiser la réplication en aval.
- 🧭 Tri : bloquer les exports de GSC vers les vues partagées Google Analytics
- 🧪 Signature : créer une regex pour isoler les variantes du préfixe tokenisé
- 🗂️ Preuves : hacher et archiver un jeu de données minimal selon la politique de rétention
- 🔍 Corréler : vérifier les pics d’impression avec les fenêtres d’incident fournisseur
- 📣 Notifier : préparer les avis privacy si des données personnelles apparaissent dans la télémétrie
| Artefact 🔎 | Où il vit 📂 | Pourquoi c’est important 🎯 | Règle de gestion 🧱 |
|---|---|---|---|
| Requêtes ressemblant à des invites | Exports GSC | Indicateur principal | Rédiger + minimiser ✂️ |
| Tokens de préfixe | Chaînes de requête | Lien vers le routage | Regex + isolation 🧪 |
| Deltas d’impression | Rapports chronologiques | Délimiter l’exposition | Annoter dans les tableaux de bord 📝 |
| Déclarations fournisseurs | Centres de confiance | Statut de confinement | Archiver + citer 📌 |
Pour préparer les équipes, partager des primers pratiques comme partager des conversations ChatGPT et un check-up réaliste sur les limites et stratégies pour 2025. Pour les responsables ingénierie, comparer la transformation GPT-4 en 2025 et la feuille de route vers la phase d’entraînement GPT-5 clarifie l’évolution de la navigation, de la contextualisation et des politiques de récupération.
Le confinement ne consiste pas à cacher l’anomalie ; il s’agit d’empêcher que l’anomalie ne devienne la nouvelle norme de votre système.
Gouvernance après le bogue : questions aux fournisseurs, garde-fous et mise en sécurité des invites
La gestion des risques évolue le plus rapidement juste après une alerte. Les entreprises examinent désormais de près leurs intégrations OpenAI et les comportements des assistants à navigation en général. La checklist indispensable démarre par des garanties contractuelles, puis s’attache aux contrôles techniques et aux garde-fous UX. Si un modèle décide de naviguer, que transmet-il exactement ? À quelle granularité ? Sous quelle base légale ? Un responsable privacy peut-il faire appliquer une politique « pas de navigation externe » pour certains projets ?
Les équipes risques ajustent aussi les consignes de travail. Les invites peuvent inclure NDA, informations personnellement identifiables, déclarations de santé et plans financiers. Quand ces invites alimentent la navigation, elles peuvent transiter par plusieurs juridictions et services. Les entreprises limitent cette exposition de deux manières : des politiques de contenu plus strictes (pas de données personnelles, pas de noms de clients) et de meilleurs indices UX (icônes claires, bannières, journaux indiquant quand le modèle est en ligne).
Mouvements essentiels en gouvernance
Du sourcing à l’exploitation quotidienne, les étapes suivantes empêchent les invites de se promener dans la télémétrie analytique et aident à restaurer la confiance des parties prenantes.
- 🧾 Mettre à jour les accords de traitement (DPA) pour couvrir la navigation, la mise en cache, et le routage de recherche tiers
- 🧱 Faire appliquer des listes autoriser/refuser pour la navigation des modèles au bord du réseau
- 🧑🏫 Former le personnel à l’hygiène des invites avec des exemples concrets des conséquences de fuites de données
- 🧰 Instrumenter des tableaux de bord avec des étiquettes quand ChatGPT est en ligne
- 🧭 Adopter des paramètres de confidentialité par défaut pour les rôles et projets sensibles
| Contrôle 🔐 | Propriétaire 👤 | Ce que ça empêche 🛑 | Signal de succès ✅ |
|---|---|---|---|
| Politique de navigation | Sécurité | Transit des invites vers la recherche | Pas de requêtes GSC ressemblant à des invites 😊 |
| Divulgation UX | Produit | Actions en ligne méconnues | Meilleure conscience du personnel 📈 |
| Règles DLP | IT | PII dans les invites | Termes sensibles bloqués 🛡️ |
| Minimisation des journaux | Privacy | Rétention excessive | Durées plus courtes ⏳ |
Les équipes pratiques peuvent explorer des ressources comme la puissance des plugins ChatGPT en 2025 pour l’hygiène d’intégration, une FAQ IA pour 2025 pour aligner le vocabulaire avec la politique, et des guides sur les bénéfices santé mentale de ChatGPT — contexte important lorsque les invites contiennent des révélations sensibles. Pour les décisions build-versus-buy, notez que la gouvernance n’est pas qu’une question de modèle ; c’est une question de pipeline, du navigateur au tableau de bord.
Un programme de gouvernance qui considère la navigation comme une capacité privilégiée, et non par défaut, vieillira bien à mesure que les produits assistants évolueront.
Ce que cela signale à propos de la navigation IA, des écosystèmes de recherche, et de la route à venir
En prenant du recul, l’épisode préfigure une tension plus large entre la navigation par modèle et la recherche web. Les assistants prospèrent quand ils peuvent chercher des informations, mais les systèmes de télémétrie web n’étaient pas conçus pour que des invites privées se mêlent à la découverte publique. Si une anomalie de routage unique peut transformer les messages les plus sincères des personnes en artefacts SEO, alors l’architecture produit doit évoluer — à la fois dans les piles OpenAI et dans les écosystèmes de recherche qui interprètent chaque chaîne comme un signal de classement.
Attendez-vous à des indicateurs de navigateur plus clairs quand un modèle est en ligne, et à de meilleures frontières entre le texte des invites et les constructions de requête utilisées pour récupérer les pages. Du côté de la recherche, les moteurs et outils pourraient nécessiter des règles de désinfection plus strictes pour les chaînes longues et conversationnelles suspectes qui ne correspondent pas à des intentions réelles. Si de nouveaux garde-fous émergent, la prochaine fois qu’un problème de routage surgira, cela devrait se terminer par moins de fuite de télémétrie et moins de surprises maladroites dans les workflows de rapports Google Analytics.
Voies pratiques pour les équipes en 2025
En attendant, les entreprises peuvent renforcer leur approche des assistants à navigation. Les traiter comme des services cloud intégrés, pas juste comme des fenêtres de chat. Valider ce qui quitte votre réseau, comment c’est journalisé, et à quelle vitesse cela peut être supprimé. Et — crucialement — enseigner aux employés ce qu’ils ne doivent pas coller dans une invite.
- 🧭 Maintenir un registre d’usage des modèles listant où la navigation est autorisée
- 🧯 Ajouter des boutons d’arrêt d’urgence pour désactiver la navigation lors d’incidents
- 🧪 Mener des exercices de red teaming simulant des expositions télémétriques d’invites
- 🧠 Fournir des conseils en temps réel dans l’interface de chat sur le contenu sensible
- 🔁 Réviser chaque trimestre les feuilles de route fournisseurs pour détecter des changements de comportement en routage
| Priorité 🚀 | Action 🔧 | Outils 🧰 | Bénéfice 🌟 |
|---|---|---|---|
| Élevée | Contrôles de sortie réseau | Proxy + CASB | Confinement des données de navigation 🔒 |
| Moyenne | Formation à l’hygiène des invites | Modules LMS | Réduction du risque de fuite 📉 |
| Moyenne | Détection d’anomalies télémétriques | Règles SIEM | Découverte accélérée d’incident ⏱️ |
| Exploratoire | Navigation sandboxée | VPC isolé | Réduction de la zone d’impact 🛡️ |
Pour les équipes affinant leur pile, envisagez de faire le pont entre produit et politique avec des ressources techniques et des lectures comparatives — comme les navigateurs IA et la cybersécurité et des guides d’aperçu qui gardent la stratégie ancrée même quand les modèles évoluent. Les systèmes les plus sûrs supposent que parfois, les chaînes les plus étranges trouveront leur chemin dans les endroits les plus publics — et ils planifient en conséquence.
Enfin, pour les développeurs expérimentant de nouveaux workflows, un mix pragmatique de revues de plateforme, de garde-fous architecturaux et de discipline en télémétrie produit peut préserver l’utilité de la navigation sans répéter les erreurs qui ont fait surgir ces journaux maladroits en ligne.
{« @context »: »https://schema.org », »@type »: »FAQPage », »mainEntity »:[{« @type »: »Question », »name »: »Pourquoi des invites similaires à ChatGPT sont-elles apparues dans Search Console et les workflows analytiques ? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Un bogue de routage associé au comportement de navigation a fait traiter des chaînes inhabituelle longues et conversationnelles — ressemblant à des invites utilisateur — via des chemins de recherche. Comme beaucoup d’organisations relient les données de Google Search Console aux piles de reporting avec Google Analytics, ces chaînes ont émergé dans les tableaux de bord et les exports. »}},{« @type »: »Question », »name »: »En quoi cela diffère-t-il des liens de chat partagés publiquement ? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Les liens partagés créent par conception des pages indexables. Cette exposition ne reposait pas sur des utilisateurs cliquant sur un bouton de partage. Au lieu de cela, du texte ressemblant à une invite a été routé de manière à laisser des traces dans la télémétrie de recherche, constituant un problème fondamentalement différent en matière de confidentialité et gouvernance. »}},{« @type »: »Question », »name »: »Quelle doit être la réaction immédiate d’une entreprise après avoir repéré des artefacts d’invite ? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Geler les exports GSC vers BI, filtrer les préfixes connus, hacher et archiver les preuves minimales, et avertir les équipes privacy et sécurité. Annoter les tableaux de bord pour la fenêtre affectée et revoir les politiques de navigation pour tous les outils assistants utilisés. »}},{« @type »: »Question », »name »: »Les utilisateurs peuvent-ils encore se fier à ChatGPT pour des travaux sensibles ? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Oui — si les organisations appliquent la gouvernance. Désactiver la navigation lorsque non nécessaire, implémenter DLP pour les invites, et former le personnel à l’hygiène des invites. Revoir la documentation fournisseur et considérer des environnements sandboxés pour les workflows plus sensibles. »}},{« @type »: »Question », »name »: »Où les praticiens peuvent-ils apprendre des tactiques plus sûres pour l’invite et le déploiement ? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Des guides pratiques comme les meilleures pratiques du playground, les FAQs axées sur la politique, et les articles de comparaison fournisseur aident les équipes à construire des schémas plus sûrs. Cherchez les ressources couvrant le comportement de navigation, la rétention des données, et les contrôles de confidentialité dès la conception. »}}]}Pourquoi des invites similaires à ChatGPT sont-elles apparues dans Search Console et les workflows analytiques ?
Un bogue de routage associé au comportement de navigation a fait traiter des chaînes inhabituelle longues et conversationnelles — ressemblant à des invites utilisateur — via des chemins de recherche. Comme beaucoup d’organisations relient les données de Google Search Console aux piles de reporting avec Google Analytics, ces chaînes ont émergé dans les tableaux de bord et les exports.
En quoi cela diffère-t-il des liens de chat partagés publiquement ?
Les liens partagés créent par conception des pages indexables. Cette exposition ne reposait pas sur des utilisateurs cliquant sur un bouton de partage. Au lieu de cela, du texte ressemblant à une invite a été routé de manière à laisser des traces dans la télémétrie de recherche, constituant un problème fondamentalement différent en matière de confidentialité et gouvernance.
Quelle doit être la réaction immédiate d’une entreprise après avoir repéré des artefacts d’invite ?
Geler les exports GSC vers BI, filtrer les préfixes connus, hacher et archiver les preuves minimales, et avertir les équipes privacy et sécurité. Annoter les tableaux de bord pour la fenêtre affectée et revoir les politiques de navigation pour tous les outils assistants utilisés.
Les utilisateurs peuvent-ils encore se fier à ChatGPT pour des travaux sensibles ?
Oui — si les organisations appliquent la gouvernance. Désactiver la navigation lorsque non nécessaire, implémenter DLP pour les invites, et former le personnel à l’hygiène des invites. Revoir la documentation fournisseur et considérer des environnements sandboxés pour les workflows plus sensibles.
Où les praticiens peuvent-ils apprendre des tactiques plus sûres pour l’invite et le déploiement ?
Des guides pratiques comme les meilleures pratiques du playground, les FAQs axées sur la politique, et les articles de comparaison fournisseur aident les équipes à construire des schémas plus sûrs. Cherchez les ressources couvrant le comportement de navigation, la rétention des données, et les contrôles de confidentialité dès la conception.



découvrez les noms de coquillages les plus fascinants et leurs significations
Déchiffrer les données cachées des architectures marines L’océan fonctionne comme une vaste archive décentralisée de l’histoire biologique. Dans cette étendue,...


Funko pop actualités : dernières sorties et exclusivités en 2025
Principales nouveautés Funko Pop de 2025 et l’impact continu en 2026 Le paysage de la collection a changé radicalement au...


qui est hans walters ? dévoiler l’histoire derrière le nom en 2025
L’Énigme de Hans Walters : Analyser l’empreinte numérique en 2026 Dans l’immense étendue d’informations disponible aujourd’hui, peu d’identificateurs présentent une...


Explorer le microsoft building 30 : un centre d’innovation et de technologie en 2025
Redéfinir l’espace de travail : au cœur de l’évolution technologique de Redmond Niché au milieu de la verdure du vaste...


Meilleurs outils d’IA pour l’aide aux devoirs en 2025
L’évolution de l’IA d’assistance aux étudiants dans la classe moderne La panique liée à un délai le dimanche soir devient...


OpenAI vs Mistral : Quel modèle d’IA conviendra le mieux à vos besoins en traitement du langage naturel en 2025 ?
Le paysage de l’Intelligence Artificielle a profondément changé alors que nous avançons en 2026. La rivalité qui a marqué l’année...


comment dire au revoir : des façons douces de gérer les adieux et les fins
Naviguer dans l’art d’un adieu en douceur en 2026 Dire adieu est rarement une tâche simple. Que vous pivotiez vers...


générateur de noms de navires pirates : créez le nom de votre navire légendaire dès aujourd’hui
Concevoir l’Identité Parfaite pour Votre Aventure Maritime Nommer un navire n’est pas simplement un exercice d’étiquetage ; c’est un acte de...


Libérer la créativité avec les prompts AI diamond body en 2025
Maîtriser le Cadre Diamond Body pour une Précision IA Dans le paysage en évolution rapide de 2025, la différence entre...


Qu’est-ce que canvas ? Tout ce que vous devez savoir en 2025
Définir Canvas dans l’Entreprise Numérique Moderne Dans le paysage de 2026, le terme « Canvas » a évolué au-delà d’une...


comment allumer la lumière du clavier de votre ordinateur portable : un guide étape par étape
Maîtriser l’illumination du clavier : Le guide essentiel étape par étape Taper dans une pièce faiblement éclairée, lors d’un vol...


meilleures suggestions de maquettes de livre pour midjourney en 2025
Optimiser la Visualisation des Livres Numériques avec Midjourney à l’Ère Post-2025 Le paysage de la visualisation des livres numériques a...


Générateurs de vidéos pour adultes pilotés par l’IA : les principales innovations à surveiller en 2025
L’aube de l’intimité synthétique : redéfinir le contenu pour adultes en 2026 Le paysage de l’expression digitale a connu un bouleversement...


ChatGPT vs LLaMA : Quel modèle de langue dominera en 2025 ?
La bataille colossale pour la suprématie de l’IA : écosystèmes ouverts vs jardins clos Dans le paysage en rapide évolution...


Maîtriser les mots commençant par ch : conseils et activités pour les jeunes lecteurs
Décoder le Mécanisme des Mots Initials en CH dans l’Alphabétisation Précoce L’acquisition du langage chez les jeunes lecteurs fonctionne remarquablement...


Howmanyofme avis : découvrez à quel point votre nom est vraiment unique
Déverrouiller les secrets de l’identité de votre nom avec des données Votre nom est bien plus qu’une simple étiquette sur...


Comprendre le détecteur de sortie gpt-2 : comment il fonctionne et pourquoi c’est important en 2025
Les Mécanismes Derrière le Détecteur de Sortie GPT-2 à l’Ère de l’IA Générative Dans le paysage en évolution rapide de...


Comment intégrer pirate weather avec home assistant : un guide complet étape par étape
L’évolution des données météorologiques hyper-locales dans les écosystèmes de maisons intelligentes La fiabilité est la pierre angulaire de toute installation...


Guide complet 2025 des meilleurs créateurs d’art IA NSFW : tendances et outils essentiels
L’évolution de l’érotisme numérique et le changement technologique de 2025 Le paysage de l’art numérique a connu un bouleversement sismique,...


OpenAI vs Meta : Explorer les différences clés entre ChatGPT et Llama 3 en 2025
Le paysage de l’IA à la fin de 2025 : un affrontement de titans Le secteur de l’intelligence artificielle a...
-

 Open Ai7 jours ago
Open Ai7 jours agoLibérer la puissance des Plugins ChatGPT : améliorez votre expérience en 2025
-

 Open Ai6 jours ago
Open Ai6 jours agoMaîtriser l’ajustement fin de GPT : un guide pour personnaliser efficacement vos modèles en 2025
-
 Open Ai6 jours ago
Open Ai6 jours agoComparer ChatGPT d’OpenAI, Claude d’Anthropic et Bard de Google : quel outil d’IA générative dominera en 2025 ?
-

 Open Ai6 jours ago
Open Ai6 jours agoTarification de ChatGPT en 2025 : Tout ce que vous devez savoir sur les tarifs et abonnements
-

 Open Ai6 jours ago
Open Ai6 jours agoLa suppression progressive des modèles GPT : à quoi les utilisateurs peuvent s’attendre en 2025
-

 Modèles d’IA6 jours ago
Modèles d’IA6 jours agoModèles GPT-4 : Comment l’intelligence artificielle transforme 2025