

Actualités
Harnessing State-Space Models to Enhance Long-Term Memory in Video World Models: Insights from Adobe Research
State-Space Models for Long-Term Memory in Video World Models: Why Attention Alone Falls Short
Video world models aim to predict future frames conditioned on actions, enabling agents to plan and reason in dynamic environments. Recent progress in video diffusion models has brought cinematic realism to predicted sequences, yet long-term memory remains a sticking point. The culprit is well known: the quadratic complexity of attention with respect to sequence length. As clips stretch into hundreds or thousands of frames, attention layers face memory blowups and latency spikes, forcing most systems to shorten context windows and inadvertently “forget” crucial early events. That forgetfulness undermines tasks like navigation, inventory tracking, or multi-step scene manipulation.
The latest work from Stanford, Princeton, and Adobe Research—titled Long-Context State-Space Video World Models—attacks the problem by replacing monolithic attention with State-Space Models (SSMs) for the global temporal backbone. Unlike retrofitting SSMs onto non-causal vision stacks, this approach leans into SSMs’ strengths: causal sequence processing with linear complexity and learnable recurrence that can carry compressed memory across very long horizons. Where attention scatters focus over all tokens, SSMs aggregate and propagate a state, spreading memory like a carefully packed travel bag rather than a sprawling suitcase.
Consider a Minecraft-like setting: an agent mines ore at t=120, crafts tools at t=450, and returns to a landmark at t=900. Pure attention either truncates the context or burns compute; either way, the earliest frames fade. An SSM backbone retains what matters—inventory changes, landmarks, object positions—keeping the semantic thread intact at marginal added cost. This approach matches the practical strain felt across industry labs at Google, Microsoft, Meta, and DeepMind, where teams have repeatedly observed that attention-only stacks struggle to scale beyond niche applications or short clips.
SSMs aren’t a silver bullet on their own. Spatial fidelity and fine-grained coherence still benefit from local attention. The key is a hybrid: use SSMs for long-range temporal memory and dense local attention for near-frame precision. The result is a model that remembers far-back causes while preserving crisp textures and object correspondences frame-to-frame. This division of labor reflects how humans navigate stories—keeping the plot while tracking the details of each scene.
The computational wall of attention
Attention’s cost scales with the square of sequence length. That’s partly manageable in text, but video multiplies tokens across time and space. In 2025 deployments, even high-end NVIDIA accelerators hit bandwidth and memory ceilings when clips span minutes. This reality has pushed developers to awkward compromises: subsampling frames, pruning tokens, or resetting memory periodically—each tactic introduces drift or gaps.
SSMs invert the scaling story. With learned state propagation, they extend the receptive field without expanding the token-to-token interaction graph. For agents that must remember earlier goals, stale obstacles, or prior camera motions, this is a pragmatic path forward.
- 🧠 Long-horizon reasoning: carry intent and scene state across hundreds of frames without quadratic blowups.
- ⚡ Lower latency: linear-time updates support interactive use, from creative tools to simulation.
- 🧩 Hybrid precision: combine global SSM memory with local attention for detail fidelity.
- 🏗️ Composable design: swap blocks without re-architecting entire pipelines.
| Approach 🔍 | Memory Horizon ⏳ | Complexity 📈 | Local Fidelity 🎯 | Notes 📝 |
|---|---|---|---|---|
| Attention-only | Medium | Quadratic 😵 | High | Struggles past long clips |
| SSM-only | Long | Linear 🚀 | Medium | Great for causality; needs help on details |
| Hybrid (SSM + local attention) | Long | Near-linear ⚖️ | High | Best of both, practical for production |
The takeaway is clear: a state-space backbone changes the economics of memory, enabling video world models to think farther without collapsing under their own compute.
Inside Adobe Research’s Long-Context State-Space Video World Models (LSSVWM)
The proposed LSSVWM reimagines the temporal core with a block-wise SSM scanning scheme, then stitches precision back in using dense local attention. The design acknowledges a trade-off: spatial consistency within each block can loosen slightly, but the reward is a tremendous extension of temporal memory. By rolling the video into manageable blocks and passing a compact state between them, the model keeps hold of past knowledge without enumerating every pairwise token interaction.
Why block-wise? In long recordings—think sports, driving, or creative edits—temporal dependencies often stretch well beyond standard context windows. A single monolithic SSM pass could still be unwieldy for massive sequences. Instead, blocks allow balanced compute budgets, exploiting parallelism across GPUs and preserving a trainable state that hops from one block to the next.
Block-wise scanning, demystified
Imagine a documentary cut into chapters. Within each chapter, the narrative is consistent and tight; across chapters, the plot must remain coherent. The block-wise SSM works similarly. Each block processes frames with an SSM to compress and update the hidden state, then hands that state to the next block. The state acts like a baton passed along a relay, carrying scene memory and action intent throughout the sequence. This yields long-horizon recall without exploding memory footprint.
Dense local attention for spatial fidelity
Because SSMs summarize rather than cross-attend every pixel-level token, fine details could blur without a companion. Dense local attention fills this role, enforcing short-range consistency across adjacent frames and within blocks. Edges, textures, and small object interactions remain sharp, ensuring video quality that’s not just consistent over minutes but also pleasing frame-by-frame.
Production teams at Adobe and peers like Apple and Amazon prioritize reliability across diverse content—handheld footage, animation, UI captures. Hybrid modeling gives them a single backbone that gracefully handles all three without bespoke tuning.
- 🧭 Block-wise SSM: scalable memory via state handoff across blocks.
- 🔬 Local attention: crisp details and temporal smoothness where the eye cares most.
- 🛠️ Modular deployment: swap block sizes or attention spans per workload.
- 💽 Hardware harmony: amenable to tensor-core execution on modern GPUs.
| Component 🧩 | Role in LSSVWM 🎛️ | Benefit ✅ | Risk ⚠️ | Mitigation 💡 |
|---|---|---|---|---|
| Block-wise SSM | Global temporal memory | Extended horizons 🕰️ | Intra-block drift | Local attention + calibration |
| Dense local attention | Spatial and short-range coherence | Sharp details 🎨 | Compute overhead | Window tuning + sparsity |
| Hybrid scheduler | Balance compute vs. quality | Predictable latency ⏱️ | Configuration sprawl | Profiles and presets |
For enterprises from Microsoft to IBM, the LSSVWM blueprint offers a sustainable route to world modeling that grows with content length rather than buckling under it. The next step is training it to actually hold onto memories under noisy, real-world conditions.
Training for Long Horizons: Diffusion Forcing and Frame Local Attention
The training regime in Long-Context State-Space Video World Models is as important as the architecture. Two techniques stand out: Diffusion Forcing and Frame Local Attention. Together they align the model with the realities of long-context generation, where imperfect inputs, partial prompts, or sparse cues are the norm rather than the exception.
Diffusion Forcing encourages the network to generate frames conditioned on a prefix of the input while accommodating noise across the remaining tokens. In the special case where the prefix length is zero—i.e., no frames are unnoised—the setup becomes pure diffusion forcing. This teaches the system to maintain coherence from a cold start, a scenario common in interactive tools where users scrub to the middle of a clip and expect stable continuation. For world models, it means the agent can re-derive a consistent scene state when context is thin.
Frame Local Attention tackles efficiency. Using FlexAttention, frames are grouped into chunks (e.g., chunks of 5 with a frame window of 10). Within a chunk, attention is bidirectional, preserving rich local structure; each frame also attends to the previous chunk, extending the effective receptive field without paying the full cost of a global causal mask. The result is faster training and sampling with high perceptual quality—crucial for iterative workflows and reinforcement learning loops.
- 🧩 Diffusion Forcing: robustness to limited or noisy prefixes.
- 🔗 Frame Local Attention: chunked windows for speed and stability.
- 🏎️ FlexAttention: hardware-friendly attention patterns on NVIDIA GPUs.
- 🧪 Curriculum schedules: gradually lengthen contexts to stabilize early training.
| Technique 🧪 | What It Does ⚙️ | Why It Matters 🌟 | Example Outcome 📽️ | Industry Relevance 🏢 |
|---|---|---|---|---|
| Diffusion Forcing | Conditions on partial prefixes; trains for zero-prefix cases | Stability from minimal context 💪 | Consistent continuation mid-clip | Adobe editing tools, Apple devices 🧯 |
| Frame Local Attention | Chunked bidirectional windows via FlexAttention | Throughput gains ⚡ | Faster RL rollouts and sampling | Amazon robotics, OpenAI agents 🤖 |
This training toolkit supports a spectrum of contexts—from zero-prefix cold starts to long, noisy sequences. It pairs naturally with the hybrid SSM-attention stack, ensuring that long-memory capability is not just theoretical but resilient during real-world use.

For teams evaluating alternatives like Mamba-based vision stacks, these methods are complementary, not contradictory, and can be slotted into broader architectures with minimal friction.
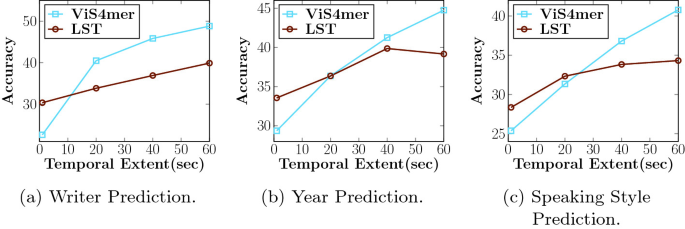
Benchmarks that Stress Memory: Memory Maze, Minecraft, and Beyond
LSSVWM was evaluated on Memory Maze and Minecraft, benchmarks specifically crafted to test spatial retrieval and long-horizon reasoning. Memory Maze measures whether an agent can recall previously sighted landmarks, doors, and keys after long detours. Minecraft demands persistent awareness of inventory, crafting steps, and coordinates, mixing low-level control with high-level plans. Both expose the Achilles’ heel of short-context models: state fragmentation.
On Memory Maze, qualitative results highlight that LSSVWM maintains consistent renderings of previously visited rooms, preserves object identity over long gaps, and correctly reorients when returning to earlier viewpoints. Competing attention-heavy baselines show “identity drift”—floor patterns morph, objects jump, or walls subtly change. In Minecraft-style evaluations, the model preserves the memory of mined resources and recipes across hundreds of frames, generating action-consistent futures where tools are used in the right order and landmarks stay put.
Comparisons extend to strong baselines, including causal-attention models and SSM variants like Mamba2 without frame-local windows. The hybrid with Frame Local Attention consistently delivers higher long-range consistency and better sample quality at comparable or lower latency. For interactive applications—creative previews, robotics planning, or game agents—the balance of speed and recall is decisive.
- 🗺️ Spatial retrieval: re-identify far-back landmarks to navigate efficiently.
- 🧰 Procedural recall: remember multi-step crafting or tool sequences.
- 🎯 Consistency under noise: handle camera jumps and occlusions gracefully.
- ⏱️ Practical latency: support real-time or near-real-time decision loops.
| Benchmark 🧭 | Skill Tested 🧠 | Baseline Behavior 🐢 | LSSVWM Behavior 🚀 | Impact 📊 |
|---|---|---|---|---|
| Memory Maze | Long-range spatial retrieval | Identity drift 😕 | Stable landmarks 😊 | Fewer wrong turns, faster completion |
| Minecraft | Procedural and inventory memory | Forgotten steps 🔁 | Correct action order 🧩 | More coherent future rollouts |
| Freeform video | Global coherence + local details | Context truncation ✂️ | Extended horizons 🕰️ | Better planning previews |
For researchers at DeepMind, Meta, and Google, these results echo internal findings: long-memory matters not just for accuracy but for user trust. When a model remembers the story so far, everything feels more believable and actionable.

The evidence points to a simple conclusion: practical world models must pair efficient long-horizon memory with mechanisms that guard local fidelity. LSSVWM sets that template.
Implications for Industry: From Creative Tools to Robotics
The architecture and training choices in LSSVWM ripple far beyond academic benchmarks. In creative software, editors expect instantaneous, context-aware predictions: where will the camera pan next, how will lighting evolve, what remains consistent across cuts? Systems built around SSMs + local attention can offer intelligent previews and context-stable generative fills, useful for storyboarding, motion design, and post-production. For a hypothetical streaming studio, that means faster iteration cycles and fewer frame correction passes.
In robotics and autonomous systems, long-term memory is even more vital. A warehouse robot guided by a video world model must remember obstacles seen minutes earlier, not just seconds. With LSSVWM-like designs, planning stacks can simulate ahead with confidence, leveraging NVIDIA hardware acceleration to keep latency in the safe range. Teams at Amazon could integrate such models into logistics simulators, while enterprises using IBM and Microsoft cloud stacks could embed them in inspection pipelines or smart-city monitoring.
On the consumer front, mobile and headset devices from Apple can benefit from compact SSM backbones that stretch memory without exceeding power budgets. Pair this with efficient attention kernels and the outcome is compelling: long-context AR scene understanding that remains responsive. Meanwhile, research orgs like OpenAI and DeepMind can plug hybrid memory into multimodal agents, aligning video prediction with text planning and action policies.
- 🎬 Creative suites: stable inpainting, longer previews, consistent effects.
- 🤖 Robotics: persistent scene memory for safe navigation and manipulation.
- 📱 Edge devices: energy-aware long-context modeling for AR/VR.
- 🧭 Simulation + planning: reliable foresight in complex environments.
| Sector 🏭 | Use Case 🎯 | Core Need 🧰 | LSSVWM Advantage 🌟 | Stakeholders 👥 |
|---|---|---|---|---|
| Media creation | Context-stable video generation | Long memory + fidelity | Hybrid SSM/attention 🎞️ | Adobe, Apple 🍏 |
| Logistics/robotics | Planning from video world models | Latency + recall | Linear-time memory ⚙️ | Amazon, Microsoft 🪟 |
| AI agents | Multimodal reasoning | Cross-modal coherence | Long-context backbones 🧠 | OpenAI, DeepMind 🧪 |
| Research/infra | Efficient training & inference | Throughput + scale | Chunked windows, FlexAttention 💡 | Google, Meta, IBM 🏛️ |
Across sectors, one pattern holds: when models remember the right things for longer, products feel smarter, safer, and more creative. The LSSVWM blueprint shows how to build for that outcome without breaking the compute bank.
What makes State-Space Models better for long-term memory than attention alone?
SSMs propagate a compact hidden state through time with linear complexity, enabling far longer horizons without quadratic cost. In hybrid stacks, dense local attention maintains fine details while SSMs carry the long-range story.
How does block-wise SSM scanning extend memory?
By processing frames in blocks and passing a learned state across blocks, the model preserves past information over long sequences while keeping compute bounded. It trades a bit of intra-block rigidity for dramatically longer recall.
Why use Diffusion Forcing in training?
Diffusion Forcing conditions generation on partial or even zero-length prefixes, teaching the model to stay coherent from minimal context. This is useful for mid-clip edits, interactive previews, and agent resets.
What is Frame Local Attention and why is FlexAttention important?
Frame Local Attention groups frames into chunks with bidirectionality inside each chunk and lookback to the previous chunk. FlexAttention implements these patterns efficiently, yielding speedups over fully causal masks.
Where could industry adopt LSSVWM first?
Creative tools (Adobe), robotics and logistics (Amazon, Microsoft), edge AR/VR (Apple), and multimodal agent research (OpenAI, DeepMind) are immediate candidates due to their need for long-horizon consistency and low latency.
Jordan has a knack for turning dense whitepapers into compelling stories. Whether he’s testing a new OpenAI release or interviewing industry insiders, his energy jumps off the page—and makes complex tech feel fresh and relevant.



international entrepreneur rule update: what changes in 2025 mean for global startups
Navigating the 2025 International Entrepreneur Rule Update The landscape for global startups looking to breach the American market has shifted...


Shortcut to size pdf: how to access and use the guide for muscle growth
Decoding the Architecture of Muscle Growth In the world of physical optimization, efficiency is the primary metric. The concept of...


Unlocking the power of iconography pdfs: essential guide for 2025
Unlocking the Strategic Value of Visual Communication in 2025 In today’s statistical-first world, effective communication often happens in milliseconds. Users...


San Francisco Startups: Key Trends to Watch in 2025
AI-Native Momentum in San Francisco Startups: Foundation Models, Agents, and Safety Across San Francisco, the most visible shift in 2025...


how to apply a promo code on study.com: step-by-step guide for august 2025
Navigating Education Savings with Study.com in August 2025 As the academic landscape continues to evolve, finding cost-effective solutions for online...


The best bond movies ranked: a definitive guide for 2025
The Future of Espionage and the Legacy of 007 in 2025 As we navigate through 2025, the cinematic landscape is...


Best male hairstyles for round faces: top trendy looks for 2025
Optimizing Facial Symmetry: The Logic Behind Haircuts for Round Faces Finding the optimal aesthetic for a round face shape is...


Explore the Top 5 Free NSFW AI Chatbots to Try in 2025
The Rise of Unfiltered Digital Companions in the 2025 Landscape The digital horizon has expanded significantly, and the way humans...


OpenAI vs Quora: Choosing Between ChatGPT and Poe for AI Tools in 2025
Navigating the AI Ecosystem: The 2025 Showdown In the rapidly evolving landscape of Artificial Intelligence, the year 2025 has brought...


Mini blocks: creative building ideas and tips for beginners in 2025
Mastering Mini Blocks: A Tactile Renaissance in 2025 In an era dominated by augmented reality and digital interfaces, the tactile...


Super claude code: how to maximize your coding efficiency in 2025
It’s no longer about simply having access to the most powerful AI; it’s about how you wield it. As we...


Essential ap world term flashcards pdf for effective 2025 exam prep
Streamlining Your 2025 AP World History Strategy with Digital Tools Success in the AP World History exam isn’t just about...


Tp test paper explained: key points, uses, and expert tips in 2025
Navigating the Teleperformance Assessment Ecosystem in 2025 The recruitment landscape has evolved significantly, with data-driven evaluations becoming the standard for...


Must-Watch AI Movies to Look Forward to in 2025
The Evolution of Cinema: Why AI Films Are Dominating 2025 The landscape of visual storytelling has shifted dramatically over the...

Notion AI vs. ChatGPT: A 2025 Feature Showdown to Supercharge Your Productivity
The digital landscape of 2025 has become crowded with intelligent assistants, each promising to revolutionize how work gets done. While...


Ftfy meaning explained: what does ftfy stand for in 2025 internet slang?
Decoding the FTFY meaning in modern digital language Navigating the complex landscape of internet slang requires more than just a...


Top words that start with tu: expand your English vocabulary
Unlocking the Potential of “TU” Vocabulary in Professional Communication Mastering a precise vocabulary is akin to optimizing code; the right...


How to use an ap spanish score calculator for accurate results in 2025
Optimizing Your Strategy with an AP Spanish Score Calculator Achieving a top tier result on the AP Spanish Language and...


A look at interesting things that start with ai
Unveiling the Hidden Layers of Modern Intelligence The landscape of technology has shifted dramatically by 2025. Artificial Intelligence is no...


sim failure explained: common causes and quick fixes in 2025
Your iPhone is your lifeline to the digital world, handling everything from urgent emails to streaming the latest podcast. So,...
-

 Open Ai2 months ago
Open Ai2 months agoA Comprehensive Guide to Sharing Your ChatGPT Conversations: 2025 Edition
-

 Open Ai2 months ago
Open Ai2 months agoHow to Effortlessly Access Your Archived Conversations on ChatGPT in 2025
-
 Tools1 month ago
Tools1 month agoHow to download and use open subtitles for movies and TV in 2025
-

 Actualités1 month ago
Actualités1 month agoOntario Man Claims ChatGPT Prompted Psychosis During ‘World-Saving’ Quest
-

 Ai models2 months ago
Ai models2 months agoMIT Researchers Introduce ‘SEAL’: A Game-Changer in the Evolution of Self-Enhancing AI
-

 Actualités2 months ago
Actualités2 months agoOpenAI Reports That Hundreds of Thousands of ChatGPT Users May Experience Symptoms of Manic or Psychotic Episodes Weekly

