

Modelos de Estado-Espacio para la Memoria a Largo Plazo en Modelos del Mundo en Video: Por Qué Sólo la Atención No Es Suficiente
Los modelos del mundo en video buscan predecir cuadros futuros condicionados a acciones, permitiendo que los agentes planifiquen y razonen en entornos dinámicos. El progreso reciente en modelos de difusión de video ha aportado realismo cinematográfico a las secuencias predichas, pero la memoria a largo plazo sigue siendo un punto problemático. El culpable es bien conocido: la complejidad cuadrática de la atención con respecto a la longitud de la secuencia. A medida que los clips se extienden a cientos o miles de cuadros, las capas de atención enfrentan explosiones de memoria y picos de latencia, obligando a la mayoría de los sistemas a acortar las ventanas de contexto y, inadvertidamente, a “olvidar” eventos cruciales al inicio. Ese olvido socava tareas como la navegación, seguimiento de inventarios o manipulación de escenas en múltiples pasos.
El trabajo más reciente de Stanford, Princeton y Adobe Research, titulado Modelos del Mundo en Video de Estado-Espacio con Contexto Largo, aborda el problema reemplazando la atención monolítica por Modelos de Estado-Espacio (SSMs) para la columna vertebral temporal global. A diferencia de adaptar SSMs a pilas de visión no causales, este enfoque aprovecha las fortalezas de los SSMs: procesamiento secuencial causal con complejidad lineal y recurrencia aprendible que puede transportar memoria comprimida a lo largo de horizontes muy largos. Mientras la atención dispersa el enfoque sobre todos los tokens, los SSMs agregan y propagan un estado, extendiendo la memoria como una maleta de viaje cuidadosamente empacada en lugar de una maleta desbordada.
Considere un escenario similar a Minecraft: un agente mina mineral en t=120, fabrica herramientas en t=450 y regresa a un punto de referencia en t=900. La atención pura o trunca el contexto o consume demasiado cómputo; de cualquier forma, los cuadros más antiguos se desvanecen. Una columna vertebral SSM retiene lo que importa: cambios en el inventario, puntos de referencia, posiciones de objetos, manteniendo el hilo semántico intacto con un costo marginal adicional. Este enfoque coincide con la presión práctica sentida en laboratorios industriales como Google, Microsoft, Meta y DeepMind, donde los equipos han observado repetidamente que las pilas basadas sólo en atención tienen dificultades para escalar más allá de aplicaciones de nicho o clips cortos.
Los SSMs no son una solución mágica por sí solos. La fidelidad espacial y la coherencia fina aún se benefician de la atención local. La clave es un híbrido: usar SSMs para la memoria temporal de largo alcance y atención local densa para precisión cercana a los cuadros. El resultado es un modelo que recuerda causas lejanas mientras preserva texturas nítidas y correspondencias de objetos cuadro por cuadro. Esta división de labores refleja cómo los humanos navegan historias: manteniendo la trama mientras rastrean los detalles de cada escena.
El muro computacional de la atención
El costo de la atención escala con el cuadrado de la longitud de la secuencia. Esto es parcialmente manejable en texto, pero el video multiplica los tokens a través del tiempo y el espacio. En implementaciones de 2025, incluso los aceleradores NVIDIA de alta gama llegan a límites de ancho de banda y memoria cuando los clips duran minutos. Esta realidad ha empujado a los desarrolladores a compromisos incómodos: submuestreo de cuadros, poda de tokens o reinicio periódico de memoria; cada táctica introduce deriva o brechas.
Los SSMs invierten esta historia de escalado. Con propagación de estado aprendida, extienden el campo receptivo sin expandir el gráfico de interacción token a token. Para agentes que deben recordar metas anteriores, obstáculos obsoletos o movimientos de cámara previos, este es un camino pragmático hacia adelante.
- 🧠 Razonamiento a largo horizonte: transportar intención y estado de escena a lo largo de cientos de cuadros sin explosiones cuadráticas.
- ⚡ Menor latencia: actualizaciones en tiempo lineal que soportan uso interactivo, desde herramientas creativas hasta simulación.
- 🧩 Precisión híbrida: combinar memoria global SSM con atención local para fidelidad en detalles.
- 🏗️ Diseño componible: intercambiar bloques sin re-arquitecturar pipelines enteros.
| Enfoque 🔍 | Horizonte de Memoria ⏳ | Complejidad 📈 | Fidelidad Local 🎯 | Notas 📝 |
|---|---|---|---|---|
| Sólo atención | Medio | Cuadrática 😵 | Alta | Problemas con clips largos |
| Sólo SSM | Largo | Lineal 🚀 | Media | Excelente para causalidad; necesita ayuda en detalles |
| Híbrido (SSM + atención local) | Largo | Casi lineal ⚖️ | Alta | Lo mejor de ambos, práctico para producción |
La conclusión es clara: una columna vertebral de estado-espacio cambia la economía de la memoria, permitiendo que los modelos del mundo en video piensen más lejos sin colapsar bajo su propio cómputo.
Dentro de los Modelos del Mundo en Video de Estado-Espacio con Contexto Largo de Adobe Research (LSSVWM)
El propuesto LSSVWM reimagina el núcleo temporal con un esquema de escaneo SSM por bloques, para luego reincorporar precisión usando atención local densa. El diseño reconoce un compromiso: la consistencia espacial dentro de cada bloque puede aflojarse ligeramente, pero la recompensa es una tremenda extensión de la memoria temporal. Al dividir el video en bloques manejables y pasar un estado compacto entre ellos, el modelo retiene el conocimiento pasado sin enumerar cada interacción token a token.
¿Por qué por bloques? En grabaciones largas —piense en deportes, conducción o ediciones creativas— las dependencias temporales a menudo se extienden mucho más allá de las ventanas de contexto estándar. Un solo paso monolítico de SSM podría ser inviable para secuencias masivas. En cambio, los bloques permiten presupuestos de cómputo equilibrados, explotando el paralelismo en GPUs y preservando un estado entrenable que pasa de un bloque al siguiente.
Escaneo por bloques, desmitificado
Imagine un documental dividido en capítulos. Dentro de cada capítulo, la narrativa es consistente y ajustada; entre capítulos, la trama debe mantenerse coherente. El SSM por bloques funciona de manera similar. Cada bloque procesa cuadros con un SSM para comprimir y actualizar el estado oculto, y luego pasa ese estado al siguiente bloque. El estado actúa como un testigo pasado en una carrera de relevos, transportando memoria de escena e intención de acción a lo largo de la secuencia. Esto genera recuerdo a largo plazo sin explotar la huella de memoria.
Atención local densa para fidelidad espacial
Dado que los SSMs resumen en lugar de atender cruzadamente cada token a nivel de píxel, los detalles finos podrían volverse borrosos sin un acompañante. La atención local densa cumple este rol, haciendo cumplir la consistencia a corto alcance entre cuadros adyacentes y dentro de los bloques. Bordes, texturas e interacciones de pequeños objetos permanecen nítidos, asegurando una calidad de video no sólo consistente durante minutos sino también agradable cuadro a cuadro.
Los equipos de producción en Adobe y pares como Apple y Amazon priorizan la fiabilidad en contenidos diversos: metraje en mano, animación, capturas de interfaz de usuario. El modelado híbrido les brinda una columna vertebral única que maneja con fluidez los tres sin ajustes personalizados.
- 🧭 SSM por bloques: memoria escalable vía transferencia de estado entre bloques.
- 🔬 Atención local: detalles nítidos y suavidad temporal donde más importa.
- 🛠️ Despliegue modular: intercambiar tamaños de bloques o rangos de atención según carga de trabajo.
- 💽 Armonía con hardware: compatible con ejecución en tensor-cores de GPUs modernas.
| Componente 🧩 | Rol en LSSVWM 🎛️ | Beneficio ✅ | Riesgo ⚠️ | Mitigación 💡 |
|---|---|---|---|---|
| SSM por bloques | Memoria temporal global | Horizontes extendidos 🕰️ | Deriva intra-bloque | Atención local + calibración |
| Atención local densa | Coherencia espacial y de corto alcance | Detalles nítidos 🎨 | Sobrecarga de cómputo | Ajuste de ventana + esparcidad |
| Planificador híbrido | Balancear cómputo vs. calidad | Latencia predecible ⏱️ | Exceso de configuraciones | Perfiles y preajustes |
Para empresas desde Microsoft hasta IBM, el plano LSSVWM ofrece una ruta sostenible a modelos del mundo que crecen con la longitud del contenido en lugar de colapsar bajo ella. El siguiente paso es entrenarlo para que realmente mantenga memorias bajo condiciones ruidosas del mundo real.
Entrenamiento para Horizontes Largos: Diffusion Forcing y Atención Local a Cuadros
El régimen de entrenamiento en Modelos del Mundo en Video de Estado-Espacio con Contexto Largo es tan importante como la arquitectura. Destacan dos técnicas: Diffusion Forcing y Atención Local a Cuadros. Juntas alinean el modelo con las realidades de la generación de contexto largo, donde insumos imperfectos, indicios parciales o señales dispersas son la norma y no la excepción.
Diffusion Forcing anima a la red a generar cuadros condicionados a un prefijo de la entrada mientras acomoda ruido en los tokens restantes. En el caso especial donde la longitud del prefijo es cero —es decir, ningún cuadro está sin ruido— el esquema se convierte en forcing puro por difusión. Esto enseña al sistema a mantener coherencia desde un inicio frío, un escenario común en herramientas interactivas donde los usuarios avanzan hasta la mitad de un clip y esperan una continuación estable. Para modelos del mundo, significa que el agente puede rederivar un estado de escena consistente cuando el contexto es escaso.
Atención Local a Cuadros aborda la eficiencia. Utilizando FlexAttention, los cuadros se agrupan en fragmentos (por ejemplo, fragmentos de 5 con una ventana de cuadro de 10). Dentro de un fragmento, la atención es bidireccional, preservando una estructura local rica; cada cuadro también atiende al fragmento previo, extendiendo el campo receptivo efectivo sin pagar el costo completo de una máscara causal global. El resultado es un entrenamiento y muestreo más rápidos con alta calidad perceptual —crucial para flujos de trabajo iterativos y bucles de aprendizaje por refuerzo.
- 🧩 Diffusion Forcing: robustez ante prefijos limitados o ruidosos.
- 🔗 Atención Local a Cuadros: ventanas fragmentadas para velocidad y estabilidad.
- 🏎️ FlexAttention: patrones de atención amigables con hardware en GPUs NVIDIA.
- 🧪 Programas curriculares: alargar gradual y controladamente contextos para estabilizar el entrenamiento temprano.
| Técnica 🧪 | Qué Hace ⚙️ | Por Qué Importa 🌟 | Ejemplo de Resultado 📽️ | Relevancia Industrial 🏢 |
|---|---|---|---|---|
| Diffusion Forcing | Condiciona en prefijos parciales; entrena para casos de prefijo cero | Estabilidad con contexto mínimo 💪 | Continuación consistente a mitad de clip | Herramientas de edición Adobe, dispositivos Apple 🧯 |
| Atención Local a Cuadros | Ventanas bidireccionales fragmentadas vía FlexAttention | Ganancias de rendimiento ⚡ | Rollouts y muestreos RL más rápidos | Robótica Amazon, agentes OpenAI 🤖 |
Este kit de herramientas de entrenamiento soporta un espectro de contextos —desde inicios fríos con prefijo cero hasta secuencias largas y ruidosas. Se complementa naturalmente con la pila híbrida SSM-atención, asegurando que la capacidad de memoria larga no sea solo teórica sino resistente durante el uso en el mundo real.

Para equipos que evalúan alternativas como pilas de visión basadas en Mamba, estos métodos son complementarios, no contradictorios, y pueden integrarse en arquitecturas más amplias con mínima fricción.
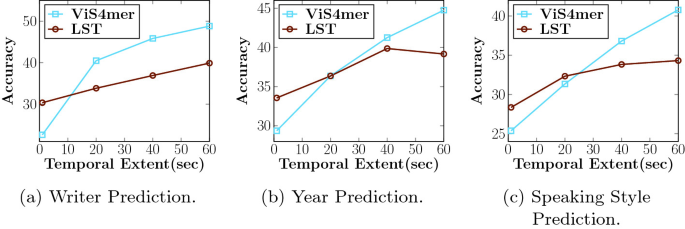
Benchmarks que Estresan la Memoria: Memory Maze, Minecraft y Más Allá
LSSVWM fue evaluado en Memory Maze y Minecraft, benchmarks específicamente diseñados para probar la recuperación espacial y el razonamiento a largo horizonte. Memory Maze mide si un agente puede recordar puntos de referencia, puertas y llaves vistos previamente después de largos desvíos. Minecraft exige conciencia persistente del inventario, pasos de elaboración y coordenadas, combinando control de bajo nivel con planes de alto nivel. Ambos exponen el talón de Aquiles de modelos de contexto corto: la fragmentación de estado.
En Memory Maze, los resultados cualitativos resaltan que LSSVWM mantiene representaciones consistentes de habitaciones visitadas anteriormente, conserva la identidad de objetos tras largas pausas y se reorienta correctamente al regresar a puntos de vista previos. Las líneas base pesadas en atención muestran “deriva de identidad”: los patrones del piso cambian, los objetos saltan o las paredes cambian sutilmente. En las evaluaciones al estilo Minecraft, el modelo preserva la memoria de recursos minados y recetas a lo largo de cientos de cuadros, generando futuros consistentes con las acciones donde las herramientas se usan en el orden correcto y los puntos de referencia permanecen en su lugar.
Las comparaciones incluyen líneas base fuertes, incluyendo modelos de atención causal y variantes SSM como Mamba2 sin ventanas locales a cuadros. El híbrido con Atención Local a Cuadros entrega consistentemente mayor coherencia a largo alcance y mejor calidad de muestras a latencias comparables o menores. Para aplicaciones interactivas —previsualizaciones creativas, planificación robótica o agentes de juego— el equilibrio entre velocidad y recuerdo es decisivo.
- 🗺️ Recuperación espacial: reidentificar puntos de referencia antiguos para navegar eficientemente.
- 🧰 Recuerdo procedimental: recordar secuencias multi-paso de elaboración o uso de herramientas.
- 🎯 Consistencia bajo ruido: manejar saltos de cámara y oclusiones con gracia.
- ⏱️ Latencia práctica: soportar bucles de decisión en tiempo real o casi real.
| Benchmark 🧭 | Habilidad Evaluada 🧠 | Comportamiento Base 🐢 | Comportamiento LSSVWM 🚀 | Impacto 📊 |
|---|---|---|---|---|
| Memory Maze | Recuperación espacial a largo alcance | Deriva de identidad 😕 | Puntos de referencia estables 😊 | Menos errores, finalización más rápida |
| Minecraft | Memoria procedimental e inventario | Pasos olvidados 🔁 | Orden correcto de acciones 🧩 | Rollouts futuros más coherentes |
| Video libre | Coherencia global + detalles locales | Contexto truncado ✂️ | Horizontes extendidos 🕰️ | Mejores previsualizaciones de planificación |
Para investigadores en DeepMind, Meta y Google, estos resultados reflejan hallazgos internos: la memoria larga importa no sólo para exactitud sino para la confianza del usuario. Cuando un modelo recuerda la historia hasta ahora, todo se siente más creíble y accionable.

La evidencia apunta a una conclusión simple: los modelos prácticos del mundo deben combinar memoria eficiente a largo plazo con mecanismos que protejan la fidelidad local. LSSVWM establece ese modelo.
Implicaciones para la Industria: Desde Herramientas Creativas hasta Robótica
La arquitectura y las elecciones de entrenamiento en LSSVWM repercuten mucho más allá de los benchmarks académicos. En software creativo, los editores esperan predicciones instantáneas y conscientes del contexto: ¿hacia dónde panea la cámara? ¿cómo evolucionará la iluminación? ¿qué permanece consistente entre cortes? Los sistemas construidos alrededor de SSMs + atención local pueden ofrecer previsualizaciones inteligentes y rellenos generativos estables en contexto, útiles para creación de guiones gráficos, diseño de movimiento y postproducción. Para un estudio de streaming hipotético, eso significa ciclos de iteración más rápidos y menos pases de corrección de cuadros.
En robótica y sistemas autónomos, la memoria a largo plazo es aún más vital. Un robot en almacén guiado por un modelo del mundo en video debe recordar obstáculos vistos minutos antes, no solo segundos. Con diseños tipo LSSVWM, las pilas de planificación pueden simular con confianza, aprovechando la aceleración de hardware NVIDIA para mantener la latencia en rangos seguros. Equipos en Amazon podrían integrar estos modelos en simuladores logísticos, mientras que empresas que usan pilas en la nube de IBM y Microsoft podrían incorporarlos a pipelines de inspección o monitoreo en ciudades inteligentes.
En el frente consumidor, dispositivos móviles y dispositivos headset de Apple pueden beneficiarse de columnas vertebrales compactas SSM que extienden la memoria sin superar presupuestos de energía. Combínelo con núcleos de atención eficientes y el resultado es convincente: comprensión de escena AR de contexto largo que sigue siendo responsiva. Mientras tanto, organizaciones de investigación como OpenAI y DeepMind pueden conectar memoria híbrida en agentes multimodales, alineando predicción de video con planificación de texto y políticas de acción.
- 🎬 Suites creativas: repintado estable, previsualizaciones largas, efectos consistentes.
- 🤖 Robótica: memoria de escena persistente para navegación y manipulación segura.
- 📱 Dispositivos edge: modelado de contexto largo consciente de energía para AR/VR.
- 🧭 Simulación + planificación: previsión confiable en entornos complejos.
| Sector 🏭 | Uso 🎯 | Necesidad Central 🧰 | Ventaja LSSVWM 🌟 | Interesados 👥 |
|---|---|---|---|---|
| Creación de medios | Generación de video estable en contexto | Memoria larga + fidelidad | Híbrido SSM/atención 🎞️ | Adobe, Apple 🍏 |
| Logística/robótica | Planificación mediante modelos del mundo en video | Latencia + recuerdo | Memoria en tiempo lineal ⚙️ | Amazon, Microsoft 🪟 |
| Agentes IA | Razonamiento multimodal | Coherencia cross-modal | Columnas vertebrales de contexto largo 🧠 | OpenAI, DeepMind 🧪 |
| Investigación/infraestructura | Entrenamiento e inferencia eficiente | Rendimiento + escala | Ventanas fragmentadas, FlexAttention 💡 | Google, Meta, IBM 🏛️ |
En todos los sectores, un patrón se mantiene: cuando los modelos recuerdan lo correcto por más tiempo, los productos se sienten más inteligentes, seguros y creativos. El plano LSSVWM muestra cómo construir para ese resultado sin romper el banco de cómputo.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”¿Qué hace que los Modelos de Estado-Espacio sean mejores para memoria a largo plazo que solo la atención?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Los SSMs propagan un estado oculto compacto a través del tiempo con complejidad lineal, permitiendo horizontes mucho mayores sin costo cuadrático. En pilas híbridas, la atención local densa mantiene detalles finos mientras los SSMs llevan la historia a largo plazo.”}},{“@type”:”Question”,”name”:”¿Cómo extiende la memoria el escaneo SSM por bloques?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Al procesar cuadros en bloques y pasar un estado aprendido entre bloques, el modelo preserva información pasada sobre largas secuencias mientras mantiene el cómputo acotado. Cambia un poco de rigidez intra-bloque por recuerdo dramáticamente más largo.”}},{“@type”:”Question”,”name”:”¿Por qué usar Diffusion Forcing en el entrenamiento?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Diffusion Forcing condiciona la generación en prefijos parciales o incluso de longitud cero, enseñando al modelo a mantenerse coherente con contexto mínimo. Esto es útil para ediciones a mitad de clip, previsualizaciones interactivas y reinicios de agentes.”}},{“@type”:”Question”,”name”:”¿Qué es Frame Local Attention y por qué es importante FlexAttention?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Frame Local Attention agrupa cuadros en fragmentos con bidireccionalidad dentro de cada fragmento y retroceso al fragmento previo. FlexAttention implementa estos patrones eficientemente, generando aceleraciones sobre máscaras causales completas.”}},{“@type”:”Question”,”name”:”¿Dónde podría la industria adoptar primero LSSVWM?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Herramientas creativas (Adobe), robótica y logística (Amazon, Microsoft), AR/VR en dispositivos edge (Apple) y investigación de agentes multimodales (OpenAI, DeepMind) son candidatos inmediatos debido a su necesidad de consistencia a largo horizonte y baja latencia.”}}]}¿Qué hace que los Modelos de Estado-Espacio sean mejores para memoria a largo plazo que solo la atención?
Los SSMs propagan un estado oculto compacto a través del tiempo con complejidad lineal, permitiendo horizontes mucho mayores sin costo cuadrático. En pilas híbridas, la atención local densa mantiene detalles finos mientras los SSMs llevan la historia a largo plazo.
¿Cómo extiende la memoria el escaneo SSM por bloques?
Al procesar cuadros en bloques y pasar un estado aprendido entre bloques, el modelo preserva información pasada sobre largas secuencias mientras mantiene el cómputo acotado. Cambia un poco de rigidez intra-bloque por recuerdo dramáticamente más largo.
¿Por qué usar Diffusion Forcing en el entrenamiento?
Diffusion Forcing condiciona la generación en prefijos parciales o incluso de longitud cero, enseñando al modelo a mantenerse coherente con contexto mínimo. Esto es útil para ediciones a mitad de clip, previsualizaciones interactivas y reinicios de agentes.
¿Qué es Frame Local Attention y por qué es importante FlexAttention?
Frame Local Attention agrupa cuadros en fragmentos con bidireccionalidad dentro de cada fragmento y retroceso al fragmento previo. FlexAttention implementa estos patrones eficientemente, generando aceleraciones sobre máscaras causales completas.
¿Dónde podría la industria adoptar primero LSSVWM?
Herramientas creativas (Adobe), robótica y logística (Amazon, Microsoft), AR/VR en dispositivos edge (Apple) y investigación de agentes multimodales (OpenAI, DeepMind) son candidatos inmediatos debido a su necesidad de consistencia a largo horizonte y baja latencia.



Comprendiendo la proyección cartográfica de Gall-Peters: beneficios y controversias en 2025
La realidad detrás del mapa: por qué la proyección Gall-Peters sigue siendo importante Cada vez que miras un mapa mundial...


cómo crear un proceso de inicio de sesión seguro para enlaces de edificios en 2025
Arquitectura de un Marco Robusto de Autenticación en la Era de la IA La autenticación de usuarios define el perímetro...


Principales herramientas de IA para pequeñas empresas: selecciones esenciales para 2025
Navegando el panorama de la IA: herramientas esenciales para el crecimiento de pequeñas empresas en 2025 El horizonte digital ha...


Elegir entre ChatGPT de OpenAI y Falcon: El Mejor Modelo de IA para 2025
El panorama de la inteligencia artificial ha cambiado drásticamente mientras navegamos por 2026. La elección ya no se trata solo...


descubre los nombres de conchas más fascinantes y sus significados
Decodificando los Datos Ocultos de las Arquitecturas Marinas El océano funciona como un vasto archivo descentralizado de la historia biológica....


Funko pop noticias: últimos lanzamientos y exclusivas en 2025
Principales Noticias de Funko Pop 2025 y el Impacto Continuo en 2026 El panorama del coleccionismo cambió drásticamente en los...


¿quién es hans walters? descubriendo la historia detrás del nombre en 2025
El Enigma de Hans Walters: Analizando la Huella Digital en 2026 En la vasta extensión de información disponible hoy en...


Explorando microsoft building 30: un centro de innovación y tecnología en 2025
Redefiniendo el Espacio de Trabajo: Dentro del Corazón de la Evolución Tecnológica de Redmond Ubicado en medio de la vegetación...


Principales herramientas de IA para asistencia con las tareas en 2025
La evolución de la IA de apoyo estudiantil en el aula moderna El pánico de un plazo del domingo por...


OpenAI vs Mistral: ¿Qué modelo de IA se adaptará mejor a tus necesidades de procesamiento de lenguaje natural en 2025?
El panorama de la Inteligencia Artificial ha cambiado drásticamente mientras navegamos a través de 2026. La rivalidad que definió el...


cómo decir adiós: maneras suaves de manejar despedidas y finales
Navegando el arte de una despedida amable en 2026 Decir adiós rara vez es una tarea sencilla. Ya sea que...


generador de nombres de barcos pirata: crea el nombre de tu legendaria embarcación hoy
Diseñando la Identidad Perfecta para Tu Aventura Marítima Nombrar una embarcación es mucho más que un simple ejercicio de etiquetado;...


Desbloqueando la creatividad con prompts de cuerpo diamond AI en 2025
Dominar el Marco del Cuerpo Diamante para la Precisión en IA En el paisaje en rápida evolución de 2025, la...


¿Qué es canvas? Todo lo que necesitas saber en 2025
Definiendo Canvas en la Empresa Digital Moderna En el panorama de 2026, el término “Canvas” ha evolucionado más allá de...


cómo encender la luz del teclado de tu portátil: una guía paso a paso
Dominar la Iluminación del Teclado: La Guía Esencial Paso a Paso Escribir en una habitación con poca luz, en un...


mejores prompts de maquetas de libros para midjourney en 2025
Optimizando la Visualización de Libros Digitales con Midjourney en la Era Post-2025 El panorama de la visualización de libros digitales...


Generadores de Videos para Adultos Impulsados por IA: Las Principales Innovaciones a Seguir en 2025
El Amanecer de la Intimidad Sintética: Redefiniendo el Contenido para Adultos en 2026 El panorama de la expresión digital ha...


ChatGPT vs LLaMA: ¿Cuál modelo de lenguaje dominará en 2025?
La Batalla Colosal por la Supremacía de la IA: Ecosistemas Abiertos vs. Jardines Amurallados En el panorama de rápida evolución...


Dominar las palabras iniciales con ch: consejos y actividades para lectores tempranos
Decodificando el Mecanismo de las Palabras Iniciales con CH en la Alfabetización Temprana La adquisición del lenguaje en lectores tempranos...


Howmanyofme reseña: descubre cuán único es realmente tu nombre
Descubriendo los secretos de la identidad de tu nombre con datos Tu nombre es más que una etiqueta en una...
-

 Open Ai1 week ago
Open Ai1 week agoDesbloqueando el Poder de los Plugins de ChatGPT: Mejora Tu Experiencia en 2025
-

 Open Ai7 days ago
Open Ai7 days agoDominando la Fine-Tuning de GPT: Una guía para personalizar eficazmente tus modelos en 2025
-
 Open Ai1 week ago
Open Ai1 week agoComparando ChatGPT de OpenAI, Claude de Anthropic y Bard de Google: ¿Qué herramienta de IA generativa reinará suprema en 2025?
-

 Open Ai7 days ago
Open Ai7 days agoPrecios de ChatGPT en 2025: Todo lo que necesitas saber sobre tarifas y suscripciones
-

 Open Ai1 week ago
Open Ai1 week agoLa eliminación progresiva de los modelos GPT: qué pueden esperar los usuarios en 2025
-

 Modelos de IA7 days ago
Modelos de IA7 days agoModelos GPT-4: Cómo la inteligencia artificial está transformando 2025