

Uncategorized
Использование моделей с пространством состояний для улучшения долговременной памяти в видеомировых моделях: выводы из Adobe Research
Модели состояния-пространства для долговременной памяти в видео-моделях мира: почему один только механизм внимания недостаточен
Видео-модели мира направлены на прогнозирование будущих кадров с учётом действий, позволяя агентам планировать и рассуждать в динамичных средах. Недавний прогресс в области видео диффузионных моделей привнёс кинематографический реализм в предсказанные последовательности, однако долговременная память остаётся проблемной. Известная причина — квадратичная сложность внимания относительно длины последовательности. По мере увеличения длины клипов до сотен или тысяч кадров слои внимания сталкиваются с взрывами потребления памяти и скачками задержек, что заставляет большинство систем укорачивать окна контекста и невольно «забывать» важные ранние события. Такое забывание подрывает задачи, такие как навигация, отслеживание инвентаря или многозадачное манипулирование сценами.
Последняя работа исследователей из Stanford, Princeton и Adobe Research — под названием Long-Context State-Space Video World Models — решает проблему, заменяя монолитное внимание на модели состояния-пространства (SSMs) в качестве глобального временного каркаса. В отличие от внедрения SSM в несквозные визуальные стековые модели, этот подход опирается на сильные стороны SSM: причинную обработку последовательностей с линейной сложностью и обучаемую рекуррентность, которая способна переносить сжатую память на очень длинные горизонты. Там, где внимание рассредотачивает фокус по всем токенам, SSM аккумулирует и распространяет состояние, распространяя память как тщательно упакованную дорожную сумку, а не как раскидистый чемодан.
Рассмотрим пример в стиле Minecraft: агент добывает руду в момент t=120, создаёт инструменты в момент t=450 и возвращается к ориентирам в момент t=900. Чистое внимание либо сокращает контекст, либо требует больших вычислительных ресурсов; в любом случае, самые ранние кадры затухают. Каркас SSM сохраняет важное — изменения инвентаря, ориентиры, позиции объектов — сохраняя смысловую нить целостной при незначительных дополнительных вычислительных затратах. Этот подход совпадает с практическими трудностями, испытываемыми исследовательскими группами в Google, Microsoft, Meta и DeepMind, где неоднократно отмечали, что системы только на внимании испытывают трудности с масштабированием за пределы нишевых приложений или коротких клипов.
SSM не являются панацеей сами по себе. Пространственная точность и тонкая согласованность по-прежнему выигрывают от локального внимания. Ключ к успеху — гибрид: использовать SSM для долговременной временной памяти и плотное локальное внимание для точности вблизи кадра. В итоге получается модель, которая запоминает причины из далёкого прошлого, сохраняя чёткие текстуры и соответствия объектов кадр за кадром. Такое разделение обязанностей отражает, как люди воспринимают истории — удерживая сюжет, одновременно следя за деталями каждой сцены.
Вычислительный барьер внимания
Стоимость внимания растёт пропорционально квадрату длины последовательности. Это частично управляемо в тексте, но видео масштабирует токены по времени и пространству. В развертываниях 2025 года даже высококлассные ускорители NVIDIA достигают потолков пропускной способности и памяти, когда клипы длятся минуты. Эта реальность заставляет разработчиков идти на неудобные компромиссы: уменьшать выборку кадров, сокращать токены или периодически сбрасывать память — каждая из тактик вводит дрейф или разрывы.
SSM меняет эту историю масштабирования. За счёт обучаемого распространения состояния они расширяют рецептивное поле без увеличения графа взаимодействия между токенами. Для агентов, которые должны помнить предыдущие цели, устаревшие препятствия или движения камеры, это практичный путь вперёд.
- 🧠 Долгосрочные рассуждения: переносить намерения и состояние сцены на сотни кадров без квадратичного взрыва.
- ⚡ Низкая задержка: обновления за линейное время поддерживают интерактивное использование — от творческих инструментов до симуляций.
- 🧩 Гибридная точность: объединять глобальную память SSM с локальным вниманием для сохранения деталей.
- 🏗️ Компонентный дизайн: менять блоки без полного перепроектирования конвейера.
| Подход 🔍 | Горизонт памяти ⏳ | Сложность 📈 | Локальная точность 🎯 | Примечания 📝 |
|---|---|---|---|---|
| Только внимание | Средний | Квадратичная 😵 | Высокая | Проблемы с длинными клипами |
| Только SSM | Длинный | Линейная 🚀 | Средняя | Отлично для причинности; нуждается в помощи с деталями |
| Гибрид (SSM + локальное внимание) | Длинный | Близко к линейной ⚖️ | Высокая | Лучшее из обоих, практично для производства |
Вывод ясен: каркас состояния-пространства меняет экономику памяти, позволяя видео-моделям мира мыслить дальше, не разрушаясь под собственной вычислительной нагрузкой.
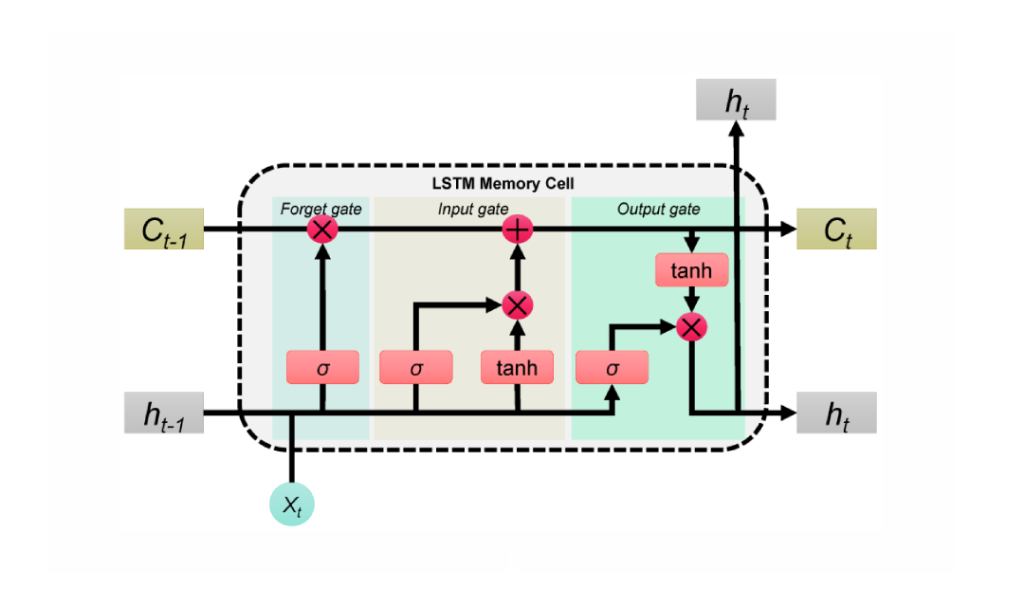
Внутри Long-Context State-Space Video World Models (LSSVWM) от Adobe Research
Предложенная LSSVWM переосмысливает временное ядро с использованием почленно-блочного схемы сканирования SSM, а затем восстанавливает точность с помощью плотного локального внимания. Дизайн признаёт компромисс: пространственная согласованность внутри каждого блока может слегка ослабевать, но вознаграждением становится огромное расширение временной памяти. Разбивая видео на управляемые блоки и передавая компактное состояние между ними, модель удерживает прошлые знания, не перебирая каждое попарное взаимодействие токенов.
Зачем почленное сканирование? В длительных записях — например, спортивных матчах, вождения или творческих монтаже — временные зависимости часто выходят далеко за рамки стандартных контекстных окон. Один монолитный проход SSM всё равно может быть неудобен для огромных последовательностей. Вместо этого блоки позволяют сбалансировать бюджет вычислений, используя параллелизм на GPU и сохраняя обучаемое состояние, которое передаётся от блока к блоку.
Почленное сканирование, объяснённое
Представьте документальный фильм, разбитый на главы. В каждой главе повествование последовательное и сжатое; между главами сюжет должен оставаться связным. Почленный SSM работает похожим образом. Каждый блок обрабатывает кадры с помощью SSM для сжатия и обновления скрытого состояния, затем передаёт это состояние следующему блоку. Состояние действует как передаваемая эстафета, неся память сцены и намерения действия на протяжении всей последовательности. Это даёт долгосрочный перенос воспоминаний без взрыва памяти.
Плотное локальное внимание для пространственной точности
Поскольку SSM резюмируют, а не выполняют кросс-внимание каждому пиксельному токену, мелкие детали могут размываться без соучастника. Плотное локальное внимание выполняет эту роль, обеспечивая краткосрочную согласованность между соседними кадрами и внутри блоков. Края, текстуры и взаимодействия маленьких объектов остаются чёткими, гарантируя качество видео, которое стабильно не только на протяжении минут, но и приятно для восприятия кадр за кадром.
Производственные команды в Adobe и компаниях, вроде Apple и Amazon, ориентируются на надёжность в работа с разнообразным контентом — от съёмки с рук и анимации до захвата пользовательского интерфейса. Гибридное моделирование даёт им единый каркас, который элегантно справляется со всеми тремя сценариями без особых настроек.
- 🧭 Почленный SSM: масштабируемая память через передачу состояния между блоками.
- 🔬 Локальное внимание: чёткие детали и плавность по времени там, где особенно важно глазу.
- 🛠️ Модульный деплоймент: возможность менять размеры блоков или зоны внимания под задачи.
- 💽 Гармония с железом: оптимизировано для тензорных ядер на современных GPU.
| Компонент 🧩 | Роль в LSSVWM 🎛️ | Преимущество ✅ | Риск ⚠️ | Смягчение 💡 |
|---|---|---|---|---|
| Почленный SSM | Глобальная временная память | Расширенные горизонты 🕰️ | Дрейф внутри блока | Локальное внимание + калибровка |
| Плотное локальное внимание | Пространственная и краткосрочная согласованность | Чёткие детали 🎨 | Вы́числительные накладные расходы | Настройка окна + разреженность |
| Гибридный планировщик | Баланс между вычислениями и качеством | Предсказуемая задержка ⏱️ | Много конфигураций | Профили и пресеты |
Для предприятий от Microsoft до IBM план LSSVWM предлагает устойчивый путь к моделированию мира, который масштабируется с длиной контента, а не ломается под ней. Следующий шаг — обучить модель действительно удерживать память в шумных, реальных условиях.
Обучение для долгих горизонтов: Diffusion Forcing и Frame Local Attention
Режим обучения в Long-Context State-Space Video World Models так же важен, как и архитектура. Два выделяющихся метода: Diffusion Forcing и Frame Local Attention. Они согласуют модель с реалиями генерации на длинном контексте, где несовершенные входы, частичные подсказки или редкие сигналы — скорее норма, чем исключение.
Diffusion Forcing стимулирует сеть генерировать кадры, условно на префикс входных данных, при этом учитывая шум на оставшихся токенах. В особом случае, когда длина префикса равна нулю — то есть нет ни одного чистого кадра — настройка становится чистым diffusion forcing. Это учит систему сохранять согласованность с «холодного старта», что часто встречается в интерактивных инструментах, где пользователь перематывает середину клипа и ожидает устойчивое продолжение. Для моделей мира это значит, что агент может заново вывести согласованное состояние сцены при ограниченном контексте.
Frame Local Attention решает проблему эффективности. С помощью FlexAttention кадры группируются в чанки (например, по 5 со скользящим окном на 10 кадров). Внутри чанка внимание двунаправленное, сохраняя богатую локальную структуру; каждый кадр также обращает внимание на предыдущий чанк, расширяя эффективное рецептивное поле без полной стоимости глобальной причинной маски. Результат — более быстрое обучение и выборка с высоким восприятием качества — что критично для итеративных рабочих процессов и циклов обучения с подкреплением.
- 🧩 Diffusion Forcing: устойчивость к ограниченным или зашумлённым префиксам.
- 🔗 Frame Local Attention: чанковые окна для скорости и стабильности.
- 🏎️ FlexAttention: аппаратно-дружелюбные паттерны внимания на NVIDIA GPU.
- 🧪 Обучающие расписания: постепенное удлинение контекстов для стабилизации начального обучения.
| Метод 🧪 | Что делает ⚙️ | Почему важно 🌟 | Пример результата 📽️ | Актуальность для отрасли 🏢 |
|---|---|---|---|---|
| Diffusion Forcing | Условно на частичные префиксы; обучает случаи с нулевым префиксом | Стабильность при минимальном контексте 💪 | Согласованное продолжение в середине клипа | Редакторы Adobe, устройства Apple 🧯 |
| Frame Local Attention | Чанковые двунаправленные окна через FlexAttention | Улучшение производительности ⚡ | Быстрые RL-запуски и выборки | Amazon робототехника, агенты OpenAI 🤖 |
Этот набор обучающих инструментов поддерживает спектр контекстов — от холодного старта с нулевым префиксом до длинных зашумленных последовательностей. Он естественно сочетается с гибридным стэком SSM-внимание, гарантируя, что способность к долговременной памяти не остаётся теоретической, а проявляется в реальном использовании.

Для команд, рассматривающих альтернативы вроде визуальных стеков на базе Mamba, эти методы дополняют друг друга, а не противоречат, и могут быть интегрированы в более широкие архитектуры с минимальными усилиями.
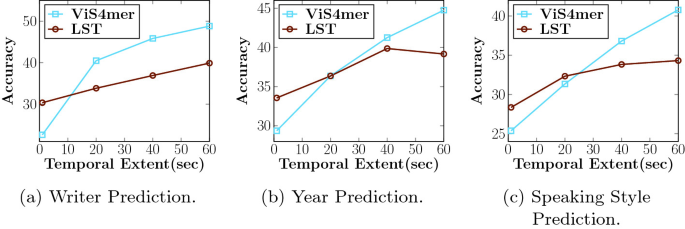
Бенчмарки, испытывающие память: Memory Maze, Minecraft и больше
LSSVWM был протестирован на Memory Maze и Minecraft — специализированных бенчмарках для проверки пространственного поиска и долговременного рассуждения. Memory Maze оценивает, может ли агент вспомнить ранее увиденные ориентиры, двери и ключи после длинных обходов. Minecraft требует постоянного осознания инвентаря, шагов крафта и координат, сочетая низкоуровневое управление с высокоуровневыми планами. Оба теста выявляют ахиллесову пяту моделей с коротким контекстом — фрагментацию состояния.
В Memory Maze качественные результаты подчёркивают, что LSSVWM сохраняет устойчивые визуализации ранее посещённых комнат, удерживает идентичность объектов при длинных разрывах и корректно ориентируется, возвращаясь к ранее изученным точкам обзора. Конкурирующие модели, основанные преимущественно на внимании, демонстрируют «дрейф идентичности» — узоры на полу меняются, объекты прыгают, стены слегка изменяются. В Minecraft-подобных тестах модель сохраняет память о добытых ресурсах и рецептах на сотнях кадров, генерируя будущие действия в правильном порядке, а ориентиры остаются на своих местах.
Сравнения проводились с сильными базовыми линиями, включая каузальные модели внимания и варианты SSM, такие как Mamba2 без локальных окон по кадрам. Гибрид с Frame Local Attention стабильно обеспечивает лучшую дальнюю согласованность и более высокое качество выборок при сопоставимой или меньшей задержке. Для интерактивных приложений — творческих превью, робототехники или игровых агентов — баланс скорости и воспоминаний решающий.
- 🗺️ Пространственный поиск: повторное опознавание дальних ориентиров для эффективной навигации.
- 🧰 Процедурное запоминание: помнить многошаговые рецепты или последовательности инструментов.
- 🎯 Согласованность при шуме: корректно обрабатывать прыжки камеры и загрязнения.
- ⏱️ Практическая задержка: поддержка реального или почти реального времени в циклах принятия решений.
| Бенчмарк 🧭 | Навык 🧠 | Поведение базовой модели 🐢 | Поведение LSSVWM 🚀 | Влияние 📊 |
|---|---|---|---|---|
| Memory Maze | Дальнее пространственное воспроизведение | Дрейф идентичности 😕 | Устойчивые ориентиры 😊 | Меньше неправильных поворотов, быстрейшее завершение |
| Minecraft | Процедурная и инвентарная память | Забытые шаги 🔁 | Правильный порядок действий 🧩 | Более когерентные будущие сценарии |
| Свободное видео | Глобальная согласованность + локальные детали | Урезание контекста ✂️ | Расширенные горизонты 🕰️ | Лучшее предварительное планирование |
Для исследователей из DeepMind, Meta и Google эти результаты совпадают с внутренними открытиями: долговременная память важна не только для точности, но и для доверия пользователя. Когда модель запоминает сюжет до текущего момента, всё кажется более реалистичным и управляемым.

Доказательства указывают на простой вывод: практичные модели мира должны сочетать эффективную долговременную память с механизмами, обеспечивающими локальную точность. LSSVWM задаёт такой стандарт.
Последствия для индустрии: от творческих инструментов до робототехники
Архитектура и методы обучения в LSSVWM выходят далеко за рамки академических бенчмарков. В творческом ПО редакторы ожидают мгновенных прогнозов с учётом контекста: куда сдвинется камера, как изменится освещение, что останется неизменным при монтаже? Системы на основе SSM + локального внимания могут предложить интеллектуальные превью и генеративные заполнения с устойчивым контекстом, полезные для раскадровки, дизайн движения и пост-продакшна. Для гипотетической студии потокового вещания это означает более быстрые циклы итераций и меньшее количество коррекции кадров.
В робототехнике и автономных системах долговременная память ещё более критична. Робот на складе, управляемый видео-моделью мира, должен помнить преграды, увиденные минуты назад, а не секунды. С архитектурами, похожими на LSSVWM, стэки планирования могут уверенно симулировать будущее, используя аппаратное ускорение NVIDIA для поддержания безопасной задержки. Команды в Amazon могут интегрировать такие модели в логистические симуляторы, а предприятия, использующие облачные стэки IBM и Microsoft, — в инспекционные пайплайны или системы умных городов.
На потребительском уровне мобильные и гарнитурные устройства от Apple могут выиграть от компактных SSM-каркасов, которые расширяют память, не превышая бюджет по энергопотреблению. В сочетании с эффективными ядрами внимания результат впечатляет: долговременное AR-понимание сцены остаётся отзывчивым. Тем временем исследовательские организации вроде OpenAI и DeepMind могут внедрять гибридную память в мультимодальные агенты, согласовывая видео-прогнозы с текстовым планированием и политиками действий.
- 🎬 Творческие пакеты: стабильное дорисовывание, более длинные превью, постоянные эффекты.
- 🤖 Робототехника: устойчивое состояние сцены для безопасной навигации и манипуляций.
- 📱 Пограничные устройства: энергоэффективное долговременное моделирование для AR/VR.
- 🧭 Симуляция и планирование: надёжное предвидение в сложных средах.
| Сектор 🏭 | Сценарий использования 🎯 | Ключевая потребность 🧰 | Преимущество LSSVWM 🌟 | Заинтересованные стороны 👥 |
|---|---|---|---|---|
| Создание медиа | Генерация видео с устойчивым контекстом | Долгая память + точность | Гибрид SSM/внимания 🎞️ | Adobe, Apple 🍏 |
| Логистика/робототехника | Планирование на основе видео-моделей мира | Задержка + воспоминания | Линейная память ⚙️ | Amazon, Microsoft 🪟 |
| ИИ-агенты | Мультимодальное рассуждение | Кроссмодальная согласованность | Каркасы с длинным контекстом 🧠 | OpenAI, DeepMind 🧪 |
| Исследования/инфраструктура | Эффективное обучение и вывод | Пропускная способность + масштаб | Чанковые окна, FlexAttention 💡 | Google, Meta, IBM 🏛️ |
Во всех секторах наблюдается одна тенденция: когда модели запоминают правильное дольше, продукты становятся умнее, безопаснее и креативнее. Шаблон LSSVWM демонстрирует, как достичь этого результата, не разорившись на вычисления.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”What makes State-Space Models better for long-term memory than attention alone?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”SSMs propagate a compact hidden state through time with linear complexity, enabling far longer horizons without quadratic cost. In hybrid stacks, dense local attention maintains fine details while SSMs carry the long-range story.”}},{“@type”:”Question”,”name”:”How does block-wise SSM scanning extend memory?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”By processing frames in blocks and passing a learned state across blocks, the model preserves past information over long sequences while keeping compute bounded. It trades a bit of intra-block rigidity for dramatically longer recall.”}},{“@type”:”Question”,”name”:”Why use Diffusion Forcing in training?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Diffusion Forcing conditions generation on partial or even zero-length prefixes, teaching the model to stay coherent from minimal context. This is useful for mid-clip edits, interactive previews, and agent resets.”}},{“@type”:”Question”,”name”:”What is Frame Local Attention and why is FlexAttention important?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Frame Local Attention groups frames into chunks with bidirectionality inside each chunk and lookback to the previous chunk. FlexAttention implements these patterns efficiently, yielding speedups over fully causal masks.”}},{“@type”:”Question”,”name”:”Where could industry adopt LSSVWM first?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Creative tools (Adobe), robotics and logistics (Amazon, Microsoft), edge AR/VR (Apple), and multimodal agent research (OpenAI, DeepMind) are immediate candidates due to their need for long-horizon consistency and low latency.”}}]}Что делает модели состояния-пространства лучше для долговременной памяти, чем только механизм внимания?
SSM передают компактное скрытое состояние во времени с линейной сложностью, что позволяет достигать гораздо более длинных горизонтов без квадратичных затрат. В гибридных стэках плотное локальное внимание сохраняет тонкие детали, а SSM несут длинную историю.
Как почленное сканирование SSM расширяет память?
Обрабатывая кадры блоками и передавая обучаемое состояние между блоками, модель сохраняет прошлую информацию в длинных последовательностях, при этом удерживая вычислительную нагрузку в пределах. Обмен некоторой жёсткостью внутри блока компенсируется значительно более длинным воспоминанием.
Зачем использовать Diffusion Forcing при обучении?
Diffusion Forcing обусловливает генерацию частичными или даже нулевой длины префиксами, обучая модель оставаться согласованной при минимальном контексте. Это полезно для правок в середине клипа, интерактивных превью и сбросов агента.
Что такое Frame Local Attention и почему важен FlexAttention?
Frame Local Attention группирует кадры в чанки с двунаправленным вниманием внутри каждого чанка и просмотром предыдущего чанка. FlexAttention эффективно реализует эти паттерны, обеспечивая ускорение по сравнению с полностью причинными масками.
Где индустрия может впервые применить LSSVWM?
Творческие инструменты (Adobe), робототехника и логистика (Amazon, Microsoft), пограничный AR/VR (Apple) и исследование мультимодальных агентов (OpenAI, DeepMind) — первоочередные кандидаты из-за потребности в согласованности на длинных горизонтах и низкой задержке.



Понимание проекции карты Галла-Питерса: преимущества и споры в 2025 году
Реальность за картой: почему проекция Галла-Питерса до сих пор важна Каждый раз, когда вы смотрите на стандартную мировую карту, вам...


как создать безопасный процесс входа по ссылке в здание в 2025 году
Проектирование надёжной системы аутентификации в эпоху ИИ Аутентификация пользователя определяет периметр современной цифровой инфраструктуры. В ландшафте 2026 года создание безопасного...


Лучшие инструменты ИИ для малого бизнеса: основные рекомендации на 2025 год
Навигация по ландшафту ИИ: основные инструменты для роста малого бизнеса в 2025 году Цифровой горизонт кардинально изменился. По мере того...


Выбор между ChatGPT от OpenAI и Falcon: лучшая модель ИИ для 2025 года
Пейзаж искусственного интеллекта кардинально изменился, когда мы движемся по 2026 году. Выбор — это уже не просто подбор чатбота; это...


откройте для себя самые захватывающие названия ракушек и их значения
Расшифровка скрытых данных морских архитектур Океан функционирует как огромный децентрализованный архив биологической истории. В этой безбрежной среде морские раковины —...


Funko pop новости: последние релизы и эксклюзивные дропы в 2025 году
Основные новости Funko Pop 2025 года и продолжающееся влияние в 2026 году Ландшафт коллекционирования кардинально изменился за последние двенадцать месяцев....


кто такой hans walters? раскрывая историю за именем в 2025 году
Загадка Ханса Уолтерса: анализ цифрового следа в 2026 году В необъятном пространстве доступной сегодня информации немногие идентификаторы показывают такую дихотомию,...


Изучение microsoft building 30: центр инноваций и технологий в 2025 году
Переосмысление рабочего пространства: в сердце технологической эволюции Редмонда Расположенное среди зелени обширного кампуса в Редмонде, Microsoft Building 30 представляет собой...


Лучшие инструменты ИИ для помощи с домашними заданиями в 2025 году
Эволюция ИИ поддержки студентов в современном классе Паника из-за дедлайна в воскресенье вечером постепенно становится пережитком прошлого. По мере того...


OpenAI vs Mistral: Какая модель ИИ лучше всего подойдет для ваших задач обработки естественного языка в 2025 году?
Пейзаж Искусственного Интеллекта кардинально изменился по мере нашего продвижения в 2026 году. Соперничество, определявшее предыдущий год — особенно столкновение между...


как сказать прощай: нежные способы справиться с прощаниями и окончаниями
Искусство нежного прощания в 2026 году Сказать прощай редко бывает просто. Независимо от того, меняете ли вы карьеру и переходите...


генератор названий пиратских кораблей: создайте имя своего легендарного судна сегодня
Создание идеальной идентичности для вашего морского приключения Назвать судно — это гораздо больше, чем просто приклеить ярлык; это акт определения...


Открывая креативность с diamond body AI prompts в 2025 году
Освоение методологии Diamond Body для точности ИИ В стремительно меняющемся мире 2025 года разница между обычным результатом и шедевром часто...


Что такое canvas? Всё, что нужно знать в 2025 году
Определение Canvas в современном цифровом предприятии В ландшафте 2026 года термин «Canvas» вышел за рамки единственного определения, представляя собой слияние...


как включить подсветку клавиатуры ноутбука: поэтапное руководство
Освоение подсветки клавиатуры: важное пошаговое руководство Печатать в тускло освещенной комнате, в ночном рейсе или во время поздней игровой сессии...


лучшие промпты для мокапов книг для midjourney в 2025 году
Оптимизация визуализации цифровых книг с Midjourney в пост-2025 эпоху Ландшафт визуализации цифровых книг кардинально изменился после алгоритмических обновлений 2025 года....


AI-Driven генераторы взрослого видео: основные инновации, на которые стоит обратить внимание в 2025 году
Рассвет синтетической интимности: переосмысление взрослого контента в 2026 году Ландшафт цифрового выражения претерпел колоссальные изменения, особенно в области производства Adult...


ChatGPT vs LLaMA: Какая языковая модель будет доминировать в 2025 году?
Колоссальная битва за превосходство в сфере ИИ: открытые экосистемы против закрытых платформ В быстро развивающемся ландшафте искусственного интеллекта выбор между...


Освоение начальных слов с ch: советы и задания для юных читателей
Расшифровка механизма начальных слов с CH в ранней грамотности Освоение языка у начинающих читателей работает удивительно похоже на сложную операционную...


Howmanyofme обзор: узнайте, насколько уникально ваше имя на самом деле
Раскрывая секреты вашей идентичности имени с помощью данных Ваше имя — это не просто ярлык в водительских правах; это краеугольный...
-

 Open Ai7 days ago
Open Ai7 days agoGPT-4 Turbo 128k: Раскрывая инновации и преимущества 2025 года
-

 Инструменты2 weeks ago
Инструменты2 weeks agoОткройте лучшие инструменты для генерации имен гномов для уникальных фэнтезийных имен
-

 Open Ai1 week ago
Open Ai1 week agoОткрывая возможности плагинов ChatGPT: улучшите свой опыт в 2025 году
-

 Open Ai7 days ago
Open Ai7 days agoОсвоение тонкой настройки GPT: руководство по эффективной кастомизации ваших моделей в 2025 году
-

 Модели ИИ7 days ago
Модели ИИ7 days agoМодели GPT-4: Как искусственный интеллект преобразует 2025 год
-
 Open Ai1 week ago
Open Ai1 week agoСравнивая ChatGPT от OpenAI, Claude от Anthropic и Bard от Google: какой инструмент генеративного ИИ будет доминировать в 2025 году?