

Modelli a Spazio di Stato per la Memoria a Lungo Termine nei Modelli Mondiali Video: Perché l’Attenzione da Sola Non Basta
I modelli mondiali video mirano a prevedere i fotogrammi futuri condizionati sulle azioni, permettendo agli agenti di pianificare e ragionare in ambienti dinamici. I recenti progressi nei modelli di diffusione video hanno portato il realismo cinematografico nelle sequenze previste, ma la memoria a lungo termine rimane un punto critico. Il colpevole è ben noto: la complessità quadratica dell’attenzione rispetto alla lunghezza della sequenza. Man mano che i clip si estendono a centinaia o migliaia di fotogrammi, gli strati di attenzione affrontano esplosioni di memoria e picchi di latenza, costringendo la maggior parte dei sistemi a ridurre le finestre di contesto e involontariamente a “dimenticare” eventi cruciali iniziali. Questa dimenticanza compromette compiti come la navigazione, il tracciamento dell’inventario o la manipolazione di scene multi-step.
Il lavoro più recente di Stanford, Princeton e Adobe Research—intitolato Long-Context State-Space Video World Models—affronta il problema sostituendo l’attenzione monolitica con i Modelli a Spazio di Stato (SSM) come spina dorsale temporale globale. A differenza di adattare gli SSM a stack visivi non causali, questo approccio si incentra sui punti di forza degli SSM: elaborazione sequenziale causale con complessità lineare e ricorrenza apprendibile che può trasportare memoria compressa su orizzonti molto lunghi. Dove l’attenzione disperde il focus su tutti i token, gli SSM aggregano e propagano uno stato, diffondendo la memoria come una valigia da viaggio accuratamente organizzata piuttosto che una valigia ingombrante.
Considera un ambiente simile a Minecraft: un agente estrae minerale a t=120, crea strumenti a t=450 e torna a un punto di riferimento a t=900. L’attenzione pura o tronca il contesto o consuma risorse; in entrambi i casi, i fotogrammi più antichi svaniscono. Una spina dorsale SSM conserva ciò che conta—cambiamenti nell’inventario, punti di riferimento, posizioni degli oggetti—mantenendo il filo semantico intatto con un costo marginale aggiuntivo. Questo approccio rispecchia la pressione pratica sentita nei laboratori industriali di Google, Microsoft, Meta e DeepMind, dove i team hanno osservato ripetutamente che gli stack solo-attentivi fanno fatica a scalare oltre applicazioni di nicchia o clip brevi.
Gli SSM non sono una soluzione magica da soli. La fedeltà spaziale e la coerenza dettagliata beneficiano ancora dell’attenzione locale. La chiave è un ibrido: usare SSM per la memoria temporale a lungo raggio e attenzione locale densa per la precisione vicino-fotogramma. Il risultato è un modello che ricorda cause lontane mantenendo texture nitide e corrispondenze oggettuali fotogramma per fotogramma. Questa divisione del lavoro riflette come gli umani navigano nelle storie—mantenendo la trama mentre tengono traccia dei dettagli di ogni scena.
Il muro computazionale dell’attenzione
Il costo dell’attenzione scala con il quadrato della lunghezza della sequenza. Questo è parzialmente gestibile nel testo, ma il video moltiplica i token nel tempo e nello spazio. Nelle implementazioni del 2025, anche acceleratori di fascia alta come NVIDIA raggiungono i limiti di banda e memoria quando i clip durano minuti. Questa realtà ha spinto gli sviluppatori verso compromessi scomodi: sottocampionamento dei fotogrammi, potatura di token o reset periodici della memoria—ogni tattica introduce deriva o lacune.
Gli SSM ribaltano questa storia di scala. Con la propagazione dello stato appresa, estendono il campo recettivo senza ampliare il grafo di interazione token-token. Per agenti che devono ricordare obiettivi precedenti, ostacoli obsoleti o movimenti di camera passati, questa è una via pragmatica da seguire.
- 🧠 Ragionamento a lungo orizzonte: trasporta intenzioni e stato della scena attraverso centinaia di fotogrammi senza esplosioni quadratiche.
- ⚡ Bassa latenza: aggiornamenti in tempo lineare supportano l’uso interattivo, da strumenti creativi a simulazioni.
- 🧩 Precisione ibrida: combina la memoria globale SSM con l’attenzione locale per fedeltà nei dettagli.
- 🏗️ Design componibile: scambia blocchi senza ristrutturare intere pipeline.
| Approccio 🔍 | Orizzonte di Memoria ⏳ | Complessità 📈 | Fedeltà Locale 🎯 | Note 📝 |
|---|---|---|---|---|
| Solo attenzione | Media | Quadratica 😵 | Alta | Difficoltà oltre clip lunghi |
| Solo SSM | Lungo | Lineare 🚀 | Media | Ottimo per causalità; necessita aiuto sui dettagli |
| Ibrido (SSM + attenzione locale) | Lungo | Quasi-lineare ⚖️ | Alta | Il meglio di entrambi, pratico per la produzione |
La conclusione è chiara: una spina dorsale a spazio di stato cambia l’economia della memoria, permettendo ai modelli mondiali video di pensare più lontano senza collassare sotto il proprio carico computazionale.
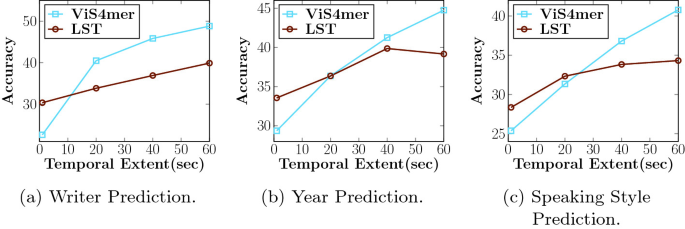
All’interno di Adobe Research Long-Context State-Space Video World Models (LSSVWM)
L’SSMVWM proposto reimmagina il nucleo temporale con uno schema di scansione SSM a blocchi, quindi ricuce la precisione usando attenzione locale densa. Il design riconosce un compromesso: la coerenza spaziale all’interno di ogni blocco può allentarsi leggermente, ma il premio è un’enorme estensione della memoria temporale. Suddividendo il video in blocchi gestibili e passando uno stato compatto tra essi, il modello conserva la conoscenza passata senza enumerare ogni interazione token-token.
Perché a blocchi? Nelle registrazioni lunghe—pensiamo a sport, guida o montaggi creativi—le dipendenze temporali spesso si estendono ben oltre le finestre di contesto standard. Una singola scansione SSM monolitica potrebbe essere comunque ingombrante per sequenze massicce. Invece, i blocchi consentono budget computazionali bilanciati, sfruttando il parallelismo tra GPU e preservando uno stato addestrabile che salta da un blocco all’altro.
Scansione a blocchi, demistificata
Immagina un documentario diviso in capitoli. All’interno di ogni capitolo, la narrazione è coerente e compatta; tra i capitoli, la trama deve rimanere coerente. Lo SSM a blocchi funziona in modo simile. Ogni blocco elabora i fotogrammi con un SSM per comprimere e aggiornare lo stato nascosto, poi passa quello stato al blocco successivo. Lo stato agisce come un testimone passato in una staffetta, trasportando la memoria della scena e l’intento d’azione per tutta la sequenza. Questo garantisce ricordo a lungo orizzonte senza esplosione del carico di memoria.
Attenzione locale densa per la fedeltà spaziale
Poiché gli SSM sintetizzano invece di eseguire attenzione incrociata su ogni token a livello pixel, i dettagli fini potrebbero sfocarsi senza un supporto aggiuntivo. L’attenzione locale densa svolge questo ruolo, imponendo coerenza a breve termine tra fotogrammi adiacenti e all’interno dei blocchi. Bordi, texture e piccole interazioni tra oggetti rimangono nitidi, garantendo una qualità video coerente non solo su minuti ma anche fotogramma per fotogramma.
I team di produzione di Adobe e colleghi come Apple e Amazon danno priorità all’affidabilità su contenuti diversi—riprese a mano, animazioni, catture UI. Il modello ibrido offre loro una singola spina dorsale che gestisce con grazia tutti e tre senza tarature su misura.
- 🧭 SSM a blocchi: memoria scalabile tramite passaggio di stato tra blocchi.
- 🔬 Attenzione locale: dettagli nitidi e scorrevolezza temporale dove l’occhio conta di più.
- 🛠️ Deploy modulare: cambia dimensioni blocchi o ambiti di attenzione per carico di lavoro.
- 💽 Armonia hardware: compatibile con esecuzione su tensor-core delle GPU moderne.
| Componente 🧩 | Ruolo in LSSVWM 🎛️ | Beneficio ✅ | Rischio ⚠️ | Mitigazione 💡 |
|---|---|---|---|---|
| SSM a blocchi | Memoria temporale globale | Orizzonti estesi 🕰️ | Deriva intra-blocco | Attenzione locale + calibrazione |
| Attenzione locale densa | Coerenza spaziale e a breve raggio | Dettagli nitidi 🎨 | Overhead computazionale | Regolazione finestre + sparsità |
| Scheduler ibrido | Bilancia compute e qualità | Latenza prevedibile ⏱️ | Configurazioni eccessive | Profili e preset |
Per aziende da Microsoft a IBM, lo schema LSSVWM offre una via sostenibile al world modeling che cresce con la lunghezza del contenuto invece di crollare sotto di essa. Il passo successivo è addestrarlo a trattenere davvero i ricordi in condizioni reali e rumorose.
Addestramento per Orizzonti Lunghi: Diffusion Forcing e Attenzione Locale ai Fotogrammi
Il regime di addestramento in Long-Context State-Space Video World Models è importante quanto l’architettura. Due tecniche spiccano: Diffusion Forcing e Attenzione Locale ai Fotogrammi. Insieme allineano il modello con le realtà della generazione a lungo contesto, dove input imperfetti, prompt parziali o indizi sparsi sono la norma e non l’eccezione.
Diffusion Forcing incoraggia la rete a generare fotogrammi condizionati su un prefisso dell’input pur accogliendo rumore nei token rimanenti. Nel caso speciale in cui la lunghezza del prefisso è zero—cioè nessun fotogramma senza rumore—l’impostazione diventa diffusione pura forzata. Questo insegna al sistema a mantenere coerenza da un inizio freddo, uno scenario comune in strumenti interattivi dove gli utenti scorrono a metà clip e si aspettano una continuazione stabile. Per i modelli mondiali, significa che l’agente può ricalcolare uno stato coerente della scena quando il contesto è scarso.
Attenzione Locale ai Fotogrammi affronta l’efficienza. Usando FlexAttention, i fotogrammi sono raggruppati in chunk (ad esempio, chunk da 5 con una finestra di 10 fotogrammi). All’interno del chunk, l’attenzione è bidirezionale, preservando una ricca struttura locale; ogni fotogramma guarda anche al chunk precedente, estendendo il campo recettivo efficace senza pagare il costo pieno di una maschera causale globale. Il risultato è un addestramento e un campionamento più rapidi con alta qualità percettiva—cruciale per flussi di lavoro iterativi e loop di reinforcement learning.
- 🧩 Diffusion Forcing: robustezza a prefissi limitati o rumorosi.
- 🔗 Attenzione Locale ai Fotogrammi: finestre a chunk per velocità e stabilità.
- 🏎️ FlexAttention: pattern di attenzione compatibili con hardware su GPU NVIDIA.
- 🧪 Programmi a curriculum: allungano gradualmente i contesti per stabilizzare i primi training.
| Tecnica 🧪 | Cosa Fa ⚙️ | Perché Importa 🌟 | Esempio di Risultato 📽️ | Rilevanza Industriale 🏢 |
|---|---|---|---|---|
| Diffusion Forcing | Condiziona su prefissi parziali; addestra per casi zero-prefisso | Stabilità da contesto minimo 💪 | Continuazione coerente a metà clip | Strumenti di editing Adobe, dispositivi Apple 🧯 |
| Attenzione Locale ai Fotogrammi | Finestre bidirezionali a chunk tramite FlexAttention | Incrementi di throughput ⚡ | Rollout RL e campionamenti più rapidi | Robotica Amazon, agenti OpenAI 🤖 |
Questo toolkit di addestramento supporta uno spettro di contesti—from inizio a freddo zero-prefisso fino a sequenze lunghe e rumorose. Si abbina naturalmente allo stack ibrido SSM-attenzione, assicurando che la capacità di memoria lunga non sia solo teorica ma resiliente nell’uso reale.

Per i team che valutano alternative come stack visivi basati su Mamba, questi metodi sono complementari, non contraddittori, e possono essere inseriti in architetture più ampie con attriti minimi.
Benchmark che Mettono alla Prova la Memoria: Memory Maze, Minecraft e Oltre
LSSVWM è stato valutato su Memory Maze e Minecraft, benchmark specificamente creati per testare il recupero spaziale e il ragionamento a lungo orizzonte. Memory Maze misura se un agente può ricordare punti di riferimento, porte e chiavi viste precedentemente dopo lunghi deviazioni. Minecraft richiede consapevolezza persistente dell’inventario, passaggi di crafting e coordinate, mescolando controllo a basso livello con piani ad alto livello. Entrambi espongono il tallone d’Achille dei modelli a contesto corto: frammentazione dello stato.
Su Memory Maze, i risultati qualitativi evidenziano che LSSVWM mantiene rendering coerenti di stanze visitate in precedenza, conserva l’identità degli oggetti su lunghi intervalli e si riorienta correttamente tornando a prospettive precedenti. I concorrenti basati soprattutto su attenzione mostrano “deriva d’identità”—pattern del pavimento si trasformano, gli oggetti saltano o i muri cambiano sottilmente. Nelle valutazioni in stile Minecraft, il modello conserva la memoria delle risorse minerarie e delle ricette per centinaia di fotogrammi, generando futuri coerenti con le azioni in cui gli strumenti sono usati nell’ordine giusto e i punti di riferimento rimangono fissi.
I confronti si estendono a baseline forti, inclusi modelli a attenzione causale e varianti SSM come Mamba2 senza finestre locali ai fotogrammi. L’ibrido con Attenzione Locale ai Fotogrammi fornisce costantemente maggiore coerenza a lungo raggio e migliore qualità dei campioni a latenza comparabile o inferiore. Per applicazioni interattive—anteprime creative, pianificazione robotica o agenti di gioco—l’equilibrio tra velocità e richiamo è decisivo.
- 🗺️ Recupero spaziale: ri-identificare punti di riferimento remoti per navigare efficientemente.
- 🧰 Richiamo procedurale: ricordare sequenze multi-step di crafting o strumenti.
- 🎯 Coerenza sotto rumore: gestire salti di camera e occlusioni con grazia.
- ⏱️ Latenza pratica: supportare loop decisionali in tempo reale o quasi.
| Benchmark 🧭 | Abilità Testata 🧠 | Comportamento Baseline 🐢 | Comportamento LSSVWM 🚀 | Impatto 📊 |
|---|---|---|---|---|
| Memory Maze | Recupero spaziale a lungo raggio | Deriva dell’identità 😕 | Punti di riferimento stabili 😊 | Meno errori di percorso, completamento più veloce |
| Minecraft | Memoria procedurale e inventario | Passaggi dimenticati 🔁 | Ordine d’azione corretto 🧩 | Rollout futuro più coerenti |
| Video liberi | Coerenza globale + dettagli locali | Troncamento contesto ✂️ | Orizzonti estesi 🕰️ | Anteprime di pianificazione migliori |
Per i ricercatori di DeepMind, Meta e Google, questi risultati rispecchiano scoperte interne: la memoria a lungo termine conta non solo per l’accuratezza ma anche per la fiducia dell’utente. Quando un modello ricorda la storia finora, tutto sembra più credibile e azionabile.

Le evidenze portano a una conclusione semplice: i modelli mondiali pratici devono abbinare memoria efficiente a lungo raggio con meccanismi che salvaguardino la fedeltà locale. LSSVWM stabilisce questo modello.
Implicazioni per l’Industria: Dagli Strumenti Creativi alla Robotica
L’architettura e le scelte di addestramento in LSSVWM si riverberano ben oltre i benchmark accademici. Nel software creativo, gli editor si aspettano predizioni istantanee e consapevoli del contesto: dove sposterà la camera, come evolverà l’illuminazione, cosa rimane coerente tra i tagli? I sistemi costruiti attorno a SSM + attenzione locale possono offrire anteprime intelligenti e riempimenti generativi stabili, utili per storyboard, motion design e post-produzione. Per uno studio di streaming ipotetico, ciò significa cicli di iterazione più veloci e meno passaggi di correzione fotogrammi.
Nella robotica e nei sistemi autonomi, la memoria a lungo termine è ancora più vitale. Un robot in magazzino guidato da un modello mondiale video deve ricordare ostacoli visti minuti prima, non solo secondi. Con design simili a LSSVWM, gli stack di pianificazione possono simulare con fiducia, sfruttando l’accelerazione hardware NVIDIA per mantenere la latenza in un intervallo sicuro. I team di Amazon potrebbero integrare tali modelli in simulatori logistici, mentre le aziende che usano infrastrutture cloud di IBM e Microsoft potrebbero incorporarli in pipeline di ispezione o monitoraggio smart-city.
Sul fronte consumer, dispositivi mobili e headset di Apple possono beneficiare di spina dorsale SSM compatte che estendono la memoria senza superare i limiti di consumo energetico. Abbinando questo a kernel di attenzione efficienti, il risultato è convincente: comprensione della scena AR a lungo contesto che rimane reattiva. Nel frattempo, organizzazioni di ricerca come OpenAI e DeepMind possono agganciare la memoria ibrida ad agenti multimodali, allineando la previsione video con la pianificazione testuale e le policy d’azione.
- 🎬 Suite creative: inpainting stabile, anteprime più lunghe, effetti coerenti.
- 🤖 Robotica: memoria persistente della scena per navigazione e manipolazione sicura.
- 📱 Dispositivi edge: modellazione a lungo contesto ed energia-consapevole per AR/VR.
- 🧭 Simulazione + pianificazione: proroga affidabile in ambienti complessi.
| Settore 🏭 | Caso d’uso 🎯 | Bisogno principale 🧰 | Vantaggio LSSVWM 🌟 | Stakeholder 👥 |
|---|---|---|---|---|
| Creazione media | Generazione video stabile nel contesto | Memoria lunga + fedeltà | Ibrido SSM/attenzione 🎞️ | Adobe, Apple 🍏 |
| Logistica/robotica | Pianificazione da modelli mondiali video | Latenza + richiamo | Memoria in tempo lineare ⚙️ | Amazon, Microsoft 🪟 |
| Agenti AI | Ragionamento multimodale | Coerenza cross-modale | Spine dorsali a lungo contesto 🧠 | OpenAI, DeepMind 🧪 |
| Ricerca/infra | Addestramento e inferenza efficienti | Throughput + scala | Finestre chunked, FlexAttention 💡 | Google, Meta, IBM 🏛️ |
In tutti i settori, emerge uno schema: quando i modelli ricordano le cose giuste più a lungo, i prodotti sembrano più intelligenti, sicuri e creativi. Lo schema LSSVWM mostra come costruire per questo risultato senza sforare il budget computazionale.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”What makes State-Space Models better for long-term memory than attention alone?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”SSMs propagate a compact hidden state through time with linear complexity, enabling far longer horizons without quadratic cost. In hybrid stacks, dense local attention maintains fine details while SSMs carry the long-range story.”}},{“@type”:”Question”,”name”:”How does block-wise SSM scanning extend memory?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”By processing frames in blocks and passing a learned state across blocks, the model preserves past information over long sequences while keeping compute bounded. It trades a bit of intra-block rigidity for dramatically longer recall.”}},{“@type”:”Question”,”name”:”Why use Diffusion Forcing in training?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Diffusion Forcing conditions generation on partial or even zero-length prefixes, teaching the model to stay coherent from minimal context. This is useful for mid-clip edits, interactive previews, and agent resets.”}},{“@type”:”Question”,”name”:”What is Frame Local Attention and why is FlexAttention important?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Frame Local Attention groups frames into chunks with bidirectionality inside each chunk and lookback to the previous chunk. FlexAttention implements these patterns efficiently, yielding speedups over fully causal masks.”}},{“@type”:”Question”,”name”:”Where could industry adopt LSSVWM first?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Creative tools (Adobe), robotics and logistics (Amazon, Microsoft), edge AR/VR (Apple), and multimodal agent research (OpenAI, DeepMind) are immediate candidates due to their need for long-horizon consistency and low latency.”}}]}Cosa rende i Modelli a Spazio di Stato migliori per la memoria a lungo termine rispetto alla sola attenzione?
Gli SSM propagano uno stato nascosto compatto nel tempo con complessità lineare, permettendo orizzonti molto più lunghi senza il costo quadratico. Negli stack ibridi, l’attenzione locale densa mantiene i dettagli fini mentre gli SSM trasportano la storia a lungo raggio.
Come estende la memoria la scansione SSM a blocchi?
Processando i fotogrammi in blocchi e passando uno stato appreso attraverso i blocchi, il modello preserva informazioni passate su lunghe sequenze mantenendo il calcolo contenuto. Scambia un po’ di rigidità intra-blocco per un richiamo drasticamente più lungo.
Perché usare Diffusion Forcing nell’addestramento?
Diffusion Forcing condiziona la generazione su prefissi parziali o persino di lunghezza zero, insegnando al modello a rimanere coerente con un contesto minimo. Questo è utile per modifiche a metà clip, anteprime interattive e reset degli agenti.
Cos’è l’Attenzione Locale ai Fotogrammi e perché FlexAttention è importante?
L’Attenzione Locale ai Fotogrammi raggruppa i fotogrammi in blocchi con bidirezionalità all’interno di ogni blocco e richiamo al blocco precedente. FlexAttention implementa questi pattern efficientemente, fornendo accelerazioni rispetto a maschere causali complete.
Dove potrebbe l’industria adottare per prima LSSVWM?
Strumenti creativi (Adobe), robotica e logistica (Amazon, Microsoft), AR/VR edge (Apple) e ricerca su agenti multimodali (OpenAI, DeepMind) sono candidati immediati per la loro necessità di coerenza a lungo orizzonte e bassa latenza.



Comprendere la proiezione cartografica di Gall-Peters: vantaggi e controversie nel 2025
La realtà dietro la mappa: perché la proiezione Gall-Peters conta ancora Ogni volta che guardi una mappa del mondo standard,...


come creare un processo di accesso sicuro a building link nel 2025
Progettare un Framework di Autenticazione Robusto nell’Era dell’IA L’autenticazione degli utenti definisce il perimetro dell’infrastruttura digitale moderna. Nel panorama del...


Strumenti di Intelligenza Artificiale Principali per Piccole Imprese: Scelte Essenziali per il 2025
Navigare nel panorama dell’IA: Strumenti essenziali per la crescita delle piccole imprese nel 2025 L’orizzonte digitale è cambiato drasticamente. Mentre...


Scegliere tra ChatGPT di OpenAI e Falcon: il miglior modello AI per il 2025
Il panorama dell’intelligenza artificiale è cambiato drasticamente mentre attraversiamo il 2026. La scelta non riguarda più solo la selezione di...


scopri i nomi di conchiglie più affascinanti e i loro significati
Decodificare i Dati Nascosti delle Architetture Marine L’oceano funziona come un vasto archivio decentralizzato di storia biologica. In questa vastità,...


Funko pop news: ultime uscite e drop esclusivi nel 2025
Le principali novità Funko Pop del 2025 e l’impatto continuo nel 2026 Il panorama del collezionismo è cambiato drasticamente negli...


chi è hans walters? scoprendo la storia dietro il nome nel 2025
L’enigma di Hans Walters: analisi dell’impronta digitale nel 2026 Nell’immensa quantità di informazioni disponibili oggi, pochi identificatori presentano una tale...


Esplorando microsoft building 30: un centro di innovazione e tecnologia nel 2025
Ridefinire lo Spazio di Lavoro: Nel Cuore dell’Evoluzione Tecnologica di Redmond Nascosto tra il verde del vasto campus di Redmond,...


I migliori strumenti di intelligenza artificiale per l’assistenza ai compiti nel 2025
L’evoluzione dell’AI per il supporto agli studenti nella classe moderna Il panico per la scadenza della domenica sera sta lentamente...


OpenAI vs Mistral: Quale modello di AI sarà il più adatto per le tue esigenze di elaborazione del linguaggio naturale nel 2025?
Il panorama dell’Intelligenza Artificiale è cambiato drasticamente mentre navighiamo attraverso il 2026. La rivalità che ha definito l’anno precedente—specificamente lo...


come dire addio: modi gentili per gestire i saluti e le conclusioni
Navigare nell’arte di un addio gentile nel 2026 Dire addio è raramente un compito semplice. Che tu stia cambiando carriera...


generatore di nomi per navi pirata: crea oggi il nome della tua leggendaria imbarcazione
Progettare l’Identità Perfetta per la Tua Avventura Marittima Chiamare un’imbarcazione è molto più di un semplice esercizio di etichettatura; è...


Sbloccare la creatività con i prompt diamond body AI nel 2025
Dominare il Framework Diamond Body per la Precisione dell’IA Nell’ambiente in rapida evoluzione del 2025, la differenza tra un output...


Che cos’è canvas? Tutto quello che devi sapere nel 2025
Definizione di Canvas nell’Impresa Digitale Moderna Nell’ambito del 2026, il termine “Canvas” è evoluto oltre una definizione singola, rappresentando una...


come accendere la luce della tastiera del tuo laptop: una guida passo passo
Dominare l’Illuminazione della Tastiera: La Guida Essenziale Passo Dopo Passo Digitare in una stanza poco illuminata, durante un volo notturno...


migliori prompt per mockup di libri per midjourney nel 2025
Ottimizzazione della Visualizzazione dei Libri Digitali con Midjourney nell’Era Post-2025 Il panorama della visualizzazione dei libri digitali è cambiato radicalmente...


Generatori di video per adulti guidati dall’IA: le principali innovazioni da tenere d’occhio nel 2025
L’alba dell’intimità sintetica: ridefinire i contenuti per adulti nel 2026 Il panorama dell’espressione digitale ha subito una trasformazione epocale, in...


ChatGPT vs LLaMA: Quale modello linguistico dominerà nel 2025?
La Battaglia Colossale per la Supremazia dell’IA: Ecosistemi Aperti vs. Giardini Recintati Nel panorama in rapida evoluzione dell’intelligenza artificiale, la...


Padroneggiare le parole iniziali con ch: consigli e attività per lettori alle prime armi
Decifrare il Meccanismo delle Parole Iniziali con CH nella Prima Alfabetizzazione L’acquisizione del linguaggio nei lettori emergenti funziona in modo...


Howmanyofme recensione: scopri quanto è davvero unico il tuo nome
Sbloccare i segreti della tua identità del nome con i dati Il tuo nome è più di una semplice etichetta...
-

 Open Ai1 week ago
Open Ai1 week agoSbloccare il Potere dei Plugin di ChatGPT: Migliora la Tua Esperienza nel 2025
-

 Open Ai7 days ago
Open Ai7 days agoPadroneggiare il Fine-Tuning di GPT: Una guida per personalizzare efficacemente i tuoi modelli nel 2025
-
 Open Ai1 week ago
Open Ai1 week agoConfronto tra ChatGPT di OpenAI, Claude di Anthropic e Bard di Google: quale strumento di IA generativa dominerà nel 2025?
-

 Open Ai7 days ago
Open Ai7 days agoTariffe di ChatGPT nel 2025: Tutto quello che devi sapere su prezzi e abbonamenti
-

 Open Ai1 week ago
Open Ai1 week agoLa Fase di Eliminazione dei Modelli GPT: Cosa Possono Aspettarsi gli Utenti nel 2025
-

 Modelli di IA7 days ago
Modelli di IA7 days agoModelli GPT-4: Come l’Intelligenza Artificiale sta Trasformando il 2025