

Uncategorized
Aproveitando Modelos de Espaço de Estados para Melhorar a Memória de Longo Prazo em Modelos de Mundo de Vídeo: Insights da Adobe Research
Modelos de Espaço de Estado para Memória de Longo Prazo em Modelos de Mundo de Vídeo: Por Que Apenas a Atenção Não é Suficiente
Modelos de mundo de vídeo visam prever quadros futuros condicionados por ações, permitindo que agentes planejem e raciocinem em ambientes dinâmicos. O progresso recente em modelos de difusão de vídeo trouxe realismo cinematográfico para sequências previstas, mas a memória de longo prazo continua sendo um ponto problemático. O culpado é conhecido: a complexidade quadrática da atenção em relação ao comprimento da sequência. À medida que os clipes se estendem por centenas ou milhares de quadros, as camadas de atenção enfrentam estouros de memória e picos de latência, forçando a maioria dos sistemas a reduzir as janelas de contexto e inadvertidamente “esquecer” eventos iniciais cruciais. Esse esquecimento compromete tarefas como navegação, rastreamento de inventário ou manipulação de cena em múltiplas etapas.
O trabalho mais recente da Stanford, Princeton e Adobe Research — intitulado Long-Context State-Space Video World Models — ataca o problema substituindo a atenção monolítica por Modelos de Espaço de Estado (SSMs) para a espinha dorsal temporal global. Diferentemente da adaptação retroativa de SSMs em pilhas de visão não causais, essa abordagem explora os pontos fortes dos SSMs: processamento causal de sequência com complexidade linear e recorrência aprendível que pode carregar memória comprimida ao longo de horizontes muito longos. Onde a atenção dispersa o foco sobre todos os tokens, os SSMs agregam e propagam um estado, espalhando a memória como uma mala cuidadosamente organizada em vez de uma mala aberta e grande.
Considere um cenário semelhante ao Minecraft: um agente minera minério no t=120, fabrica ferramentas no t=450, e retorna a um marco no t=900. A atenção pura ou trunca o contexto ou consome muito processamento; de qualquer forma, os quadros mais antigos desaparecem. Uma espinha dorsal SSM retém o que importa — mudanças no inventário, marcos, posições de objetos — mantendo o fio semântico intacto com custo marginal adicional. Essa abordagem corresponde ao esforço prático sentido em laboratórios da indústria como Google, Microsoft, Meta e DeepMind, onde equipes já observaram repetidamente que pilhas somente com atenção enfrentam dificuldades para escalar além de aplicações de nicho ou clipes curtos.
SSMs não são uma solução milagrosa por si só. A fidelidade espacial e a coerência de detalhes finos ainda se beneficiam da atenção local. A chave é um híbrido: usar SSMs para memória temporal de longo alcance e atenção local densa para precisão próxima ao quadro. O resultado é um modelo que lembra causas distantes enquanto preserva texturas nítidas e correspondências de objetos quadro a quadro. Essa divisão de trabalho reflete como humanos navegam histórias — mantendo a trama enquanto acompanham os detalhes de cada cena.
A barreira computacional da atenção
O custo da atenção escala com o quadrado do comprimento da sequência. Isso é parcialmente gerenciável em texto, mas vídeo multiplica tokens ao longo do tempo e espaço. Nas implantações de 2025, até aceleradores NVIDIA de ponta atingem limites de largura de banda e memória quando clipes duram minutos. Essa realidade levou desenvolvedores a compromissos desconfortáveis: subamostragem de quadros, poda de tokens ou reinicialização periódica da memória — cada tática introduz deriva ou lacunas.
Os SSMs invertem essa história de escalabilidade. Com a propagação aprendida do estado, eles estendem o campo receptivo sem expandir o grafo de interação token-a-token. Para agentes que precisam lembrar metas anteriores, obstáculos antigos ou movimentos prévios de câmera, esse é um caminho pragmático para o futuro.
- 🧠 Raciocínio de longo horizonte: carregar intenção e estado de cena por centenas de quadros sem estouros quadráticos.
- ⚡ Menor latência: atualizações em tempo linear suportam uso interativo, de ferramentas criativas a simulações.
- 🧩 Precisão híbrida: combinar memória global SSM com atenção local para fidelidade de detalhes.
- 🏗️ Design composível: trocar blocos sem reestruturar pipelines inteiros.
| Abordagem 🔍 | Horizonte de Memória ⏳ | Complexidade 📈 | Fidelidade Local 🎯 | Notas 📝 |
|---|---|---|---|---|
| Atenção apenas | Médio | Quadrática 😵 | Alta | Dificuldade além de clipes longos |
| SSM apenas | Longo | Linear 🚀 | Média | Ótimo para causalidade; precisa de ajuda nos detalhes |
| Híbrido (SSM + atenção local) | Longo | Quase linear ⚖️ | Alta | Melhor dos dois, prático para produção |
A conclusão é clara: uma espinha dorsal de espaço de estado muda a economia da memória, permitindo que modelos de mundo de vídeo pensem mais longe sem desabar sob seu próprio processamento.
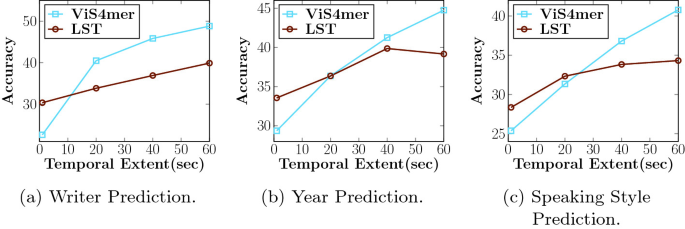
Dentro dos Modelos de Mundo de Vídeo de Espaço de Estado de Longo Contexto da Adobe Research (LSSVWM)
O proposto LSSVWM reinventa o núcleo temporal com um esquema de escaneamento SSM em blocos, depois costura a precisão de volta usando atenção local densa. O design reconhece um compromisso: a consistência espacial dentro de cada bloco pode relaxar um pouco, mas a recompensa é uma tremenda extensão da memória temporal. Ao dividir o vídeo em blocos gerenciáveis e passar um estado compacto entre eles, o modelo mantém o conhecimento passado sem enumerar cada interação token-a-token.
Por que em blocos? Em gravações longas — pense em esportes, direção ou edições criativas — dependências temporais muitas vezes se estendem muito além das janelas de contexto padrão. Uma passagem monolítica única de SSM ainda poderia ser impraticável para sequências massivas. Em vez disso, blocos permitem orçamentos de processamento balanceados, explorando paralelismo em GPUs e preservando um estado treinável que salta de um bloco para o próximo.
Escaneamento em blocos, desmistificado
Imagine um documentário dividido em capítulos. Dentro de cada capítulo, a narrativa é consistente e coesa; entre capítulos, a trama deve permanecer coerente. O SSM em blocos funciona de forma semelhante. Cada bloco processa quadros com um SSM para comprimir e atualizar o estado oculto, depois passa esse estado para o próximo bloco. O estado atua como um bastão passado numa corrida, carregando a memória da cena e a intenção da ação por toda a sequência. Isso proporciona recordação em longo horizonte sem explodir o uso de memória.
Atenção local densa para fidelidade espacial
Como os SSMs resumem em vez de fazer cross-attention em cada token em nível de pixel, detalhes finos poderiam se borrar sem um companheiro. A atenção local densa cumpre esse papel, aplicando consistência de curto alcance entre quadros adjacentes e dentro dos blocos. Bordas, texturas e pequenas interações de objetos permanecem nítidas, garantindo qualidade de vídeo que não é apenas consistente por minutos, mas também agradável quadro a quadro.
As equipes de produção da Adobe e pares como Apple e Amazon priorizam confiabilidade em conteúdos diversos — filmagens manuais, animação, capturas de interface. A modelagem híbrida lhes oferece uma espinha dorsal única que lida com todos os três sem ajustes personalizados.
- 🧭 SSM em blocos: memória escalável via transferência de estado entre blocos.
- 🔬 Atenção local: detalhes nítidos e suavidade temporal onde o olho mais percebe.
- 🛠️ Implantação modular: trocar tamanhos de blocos ou alcances de atenção conforme a carga de trabalho.
- 💽 Harmonia com hardware: compatível com execução em tensor-core em GPUs modernas.
| Componente 🧩 | Função no LSSVWM 🎛️ | Benefício ✅ | Risco ⚠️ | Mitigação 💡 |
|---|---|---|---|---|
| SSM em blocos | Memória temporal global | Horizontes estendidos 🕰️ | Deriva intra-bloco | Atenção local + calibração |
| Atenção local densa | Coerência espacial e de curto alcance | Detalhes nítidos 🎨 | Carga computacional | Ajuste de janela + esparsidade |
| Agendador híbrido | Equilibrar computação x qualidade | Latência previsível ⏱️ | Proliferação de configurações | Perfis e predefinições |
Para empresas de Microsoft a IBM, o modelo LSSVWM oferece uma rota sustentável para modelagem de mundo que cresce com o comprimento do conteúdo em vez de fraquejar. O próximo passo é treiná-lo para realmente manter memórias sob condições reais e ruidosas.
Treinamento para Longos Horizontes: Diffusion Forcing e Atenção Local de Quadros
O regime de treinamento em Long-Context State-Space Video World Models é tão importante quanto a arquitetura. Duas técnicas se destacam: Diffusion Forcing e Atenção Local de Quadros. Juntas alinham o modelo com as realidades da geração de longo contexto, onde entradas imperfeitas, prompts parciais ou pistas esparsas são a norma, não a exceção.
Diffusion Forcing encoraja a rede a gerar quadros condicionados a um prefixo da entrada enquanto acomoda ruído nos tokens restantes. No caso especial em que o comprimento do prefixo é zero—ou seja, nenhum quadro está sem ruído—, a configuração se torna pura diffusion forcing. Isso ensina o sistema a manter coerência desde uma partida fria, um cenário comum em ferramentas interativas onde usuários avançam para o meio de um clipe e esperam uma continuação estável. Para modelos de mundo, isso significa que o agente pode rederivar um estado de cena consistente quando o contexto é escasso.
Atenção Local de Quadros trata da eficiência. Usando FlexAttention, quadros são agrupados em blocos (p.ex., blocos de 5 com janela de quadro de 10). Dentro de um bloco, a atenção é bidirecional, preservando estrutura local rica; cada quadro também atenta para o bloco anterior, estendendo o campo receptivo efetivo sem pagar o custo total de uma máscara causal global. O resultado é treinamento e amostragem mais rápidos com alta qualidade perceptual — crucial para fluxos de trabalho iterativos e laços de aprendizado por reforço.
- 🧩 Diffusion Forcing: robustez a prefixos limitados ou ruidosos.
- 🔗 Atenção Local de Quadros: janelas em blocos para velocidade e estabilidade.
- 🏎️ FlexAttention: padrões de atenção amigáveis ao hardware em GPUs NVIDIA.
- 🧪 Agendas de currículos: aumentar gradualmente contextos para estabilizar o treinamento inicial.
| Técnica 🧪 | O Que Faz ⚙️ | Por Que Importa 🌟 | Exemplo de Resultado 📽️ | Relevância Industrial 🏢 |
|---|---|---|---|---|
| Diffusion Forcing | Condiciona em prefixos parciais; treina para casos de prefixo zero | Estabilidade a partir de contexto mínimo 💪 | Continuação consistente no meio do clipe | Ferramentas de edição Adobe, dispositivos Apple 🧯 |
| Atenção Local de Quadros | Janelas bidirecionais em blocos via FlexAttention | Ganhos de rendimento ⚡ | Rollouts e amostragens RL mais rápidos | Robótica Amazon, agentes OpenAI 🤖 |
Este kit de ferramentas de treinamento suporta um espectro de contextos — desde partidas frias com prefixo zero até sequências longas e ruidosas. Combina-se naturalmente com a pilha híbrida SSM-atenção, garantindo que a capacidade de memória longa não seja somente teórica, mas resiliente no uso real.

Para equipes avaliando alternativas como pilhas de visão baseadas em Mamba, esses métodos são complementares, não contraditórios, e podem ser encaixados em arquiteturas mais amplas com fricção mínima.
Benchmarks que Testam a Memória: Memory Maze, Minecraft e Além
LSSVWM foi avaliado em Memory Maze e Minecraft, benchmarks criados especificamente para testar recuperação espacial e raciocínio de longo horizonte. Memory Maze mede se um agente pode relembrar marcos, portas e chaves depois de longos desvios. Minecraft exige consciência persistente de inventário, passos de fabricação e coordenadas, misturando controle de baixo nível com planos de alto nível. Ambos expõem o calcanhar de Aquiles de modelos de contexto curto: fragmentação do estado.
No Memory Maze, resultados qualitativos destacam que LSSVWM mantém renderizações consistentes de salas previamente visitadas, preserva a identidade dos objetos ao longo de longos intervalos e se reorienta corretamente ao retornar a pontos anteriores. Modelos concorrentes fortemente baseados em atenção mostram “deriva de identidade” — padrões do chão mudam, objetos pulam, ou paredes mudam sutilmente. Em avaliações estilo Minecraft, o modelo preserva a memória dos recursos minerados e receitas ao longo de centenas de quadros, gerando futuros consistentes com a ação onde ferramentas são usadas na ordem correta e marcos permanecem no lugar.
Comparações incluem fortes linhas base, incluindo modelos de atenção causal e variantes SSM como Mamba2 sem janelas locais de quadros. O híbrido com Atenção Local de Quadros consistentemente entrega maior consistência de longo alcance e melhor qualidade de amostra com latência comparável ou menor. Para aplicações interativas — prévias criativas, planejamento robótico ou agentes de jogos — o equilíbrio entre velocidade e recordação é decisivo.
- 🗺️ Recuperação espacial: reidentificar marcos distantes para navegar eficientemente.
- 🧰 Recordação procedural: lembrar sequências de fabricação ou uso de ferramentas em múltiplas etapas.
- 🎯 Consistência sob ruído: lidar graciosamente com saltos de câmera e oclusões.
- ⏱️ Latência prática: suportar ciclos de decisão em tempo real ou quase real.
| Benchmark 🧭 | Habilidade Testada 🧠 | Comportamento Baseline 🐢 | Comportamento LSSVWM 🚀 | Impacto 📊 |
|---|---|---|---|---|
| Memory Maze | Recuperação espacial de longo alcance | Deriva de identidade 😕 | Marcos estáveis 😊 | Menos erros, conclusão mais rápida |
| Minecraft | Memória procedural e de inventário | Passos esquecidos 🔁 | Ordem correta da ação 🧩 | Roteiros futuros mais coerentes |
| Vídeo livre | Coerência global + detalhes locais | Truncamento de contexto ✂️ | Horizontes estendidos 🕰️ | Pré-visualizações de planejamento melhores |
Para pesquisadores da DeepMind, Meta e Google, esses resultados ecoam descobertas internas: memória longa importa não só para precisão, mas para confiança do usuário. Quando um modelo lembra a história até o momento, tudo parece mais crível e acionável.

A evidência aponta para uma conclusão simples: modelos práticos de mundo devem combinar memória eficiente de longo horizonte com mecanismos que garantam fidelidade local. LSSVWM define esse modelo.
Implicações para a Indústria: De Ferramentas Criativas a Robótica
A arquitetura e escolhas de treinamento do LSSVWM reverberam muito além dos benchmarks acadêmicos. Em softwares criativos, editores esperam previsões instantâneas e conscientes do contexto: para onde a câmera irá panear a seguir, como a iluminação evoluirá, o que permanece consistente entre cortes? Sistemas construídos ao redor de SSMs + atenção local podem oferecer prévias inteligentes e preenchimentos generativos estáveis no contexto, úteis para storyboarding, design de movimento e pós-produção. Para um estúdio hipotético de streaming, isso significa ciclos de iteração mais rápidos e menos passes de correção de quadro.
Em robótica e sistemas autônomos, a memória de longo prazo é ainda mais vital. Um robô de armazém guiado por um modelo de mundo de vídeo deve lembrar obstáculos vistos minutos atrás, não apenas segundos. Com designs como o LSSVWM, pilhas de planejamento podem simular com confiança, aproveitando aceleração de hardware NVIDIA para manter a latência em níveis seguros. Equipes da Amazon poderiam integrar tais modelos em simuladores logísticos, enquanto empresas utilizando pilhas de nuvem da IBM e Microsoft poderiam incorporá-los em pipelines de inspeção ou monitoramento de cidades inteligentes.
No front do consumidor, dispositivos móveis e headsets da Apple podem se beneficiar de espinhas dorsais compactas SSM que estendem a memória sem ultrapassar orçamentos de energia. Combine isso com kernels de atenção eficientes e o resultado é atraente: compreensão de cenas AR de contexto longo que permanece responsiva. Enquanto isso, organizações de pesquisa como OpenAI e DeepMind podem conectar a memória híbrida em agentes multimodais, alinhando previsão de vídeo com planejamento textual e políticas de ação.
- 🎬 Suítes criativas: inpainting estável, prévias longas, efeitos consistentes.
- 🤖 Robótica: memória persistente da cena para navegação e manipulação seguras.
- 📱 Dispositivos de borda: modelagem de contexto longo com consciência energética para AR/VR.
- 🧭 Simulação + planejamento: previsão confiável em ambientes complexos.
| Setor 🏭 | Caso de Uso 🎯 | Necessidade Central 🧰 | Vantagem LSSVWM 🌟 | Partes Interessadas 👥 |
|---|---|---|---|---|
| Criação de mídia | Geração de vídeo estável no contexto | Memória longa + fidelidade | Híbrido SSM/atenção 🎞️ | Adobe, Apple 🍏 |
| Logística/robótica | Planejamento a partir de modelos de mundo em vídeo | Latência + recordação | Memória em tempo linear ⚙️ | Amazon, Microsoft 🪟 |
| Agentes de IA | Raciocínio multimodal | Coerência cross-modal | Espinhas dorsais de longo contexto 🧠 | OpenAI, DeepMind 🧪 |
| Pesquisa/infraestrutura | Treinamento & inferência eficiente | Taxa de transferência + escala | Janelas em blocos, FlexAttention 💡 | Google, Meta, IBM 🏛️ |
Em todos os setores, um padrão permanece: quando modelos lembram as coisas certas por mais tempo, os produtos parecem mais inteligentes, seguros e criativos. O modelo LSSVWM mostra como construir para esse resultado sem estourar os custos de computação.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”O que torna os Modelos de Espaço de Estado melhores para memória de longo prazo do que apenas atenção?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”SSMs propagam um estado oculto compacto ao longo do tempo com complexidade linear, permitindo horizontes muito mais longos sem custo quadrático. Em pilhas híbridas, a atenção local densa mantém detalhes finos enquanto os SSMs carregam a história de longo alcance.”}},{“@type”:”Question”,”name”:”Como o escaneamento SSM em blocos estende a memória?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Processando quadros em blocos e passando um estado aprendido entre eles, o modelo preserva informações passadas em sequências longas mantendo o processamento controlado. Troca um pouco da rigidez intra-bloco por uma recordação dramaticamente maior.”}},{“@type”:”Question”,”name”:”Por que usar Diffusion Forcing no treinamento?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Diffusion Forcing condiciona a geração em prefixos parciais ou mesmo de comprimento zero, ensinando o modelo a manter coerência com contexto mínimo. Isso é útil para edições no meio do clipe, prévias interativas e reinicializações de agentes.”}},{“@type”:”Question”,”name”:”O que é Atenção Local de Quadros e por que FlexAttention é importante?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Atenção Local de Quadros agrupa quadros em blocos com bidirecionalidade dentro de cada bloco e lookback para o bloco anterior. FlexAttention implementa esses padrões de forma eficiente, trazendo acelerações sobre máscaras causais completas.”}},{“@type”:”Question”,”name”:”Onde a indústria poderia adotar o LSSVWM primeiro?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Ferramentas criativas (Adobe), robótica e logística (Amazon, Microsoft), AR/VR de borda (Apple) e pesquisa de agentes multimodais (OpenAI, DeepMind) são candidatos imediatos devido à necessidade de consistência de longo horizonte e baixa latência.”}}]}O que torna os Modelos de Espaço de Estado melhores para memória de longo prazo do que apenas atenção?
SSMs propagam um estado oculto compacto ao longo do tempo com complexidade linear, permitindo horizontes muito mais longos sem custo quadrático. Em pilhas híbridas, a atenção local densa mantém detalhes finos enquanto os SSMs carregam a história de longo alcance.
Como o escaneamento SSM em blocos estende a memória?
Processando quadros em blocos e passando um estado aprendido entre eles, o modelo preserva informações passadas em sequências longas mantendo o processamento controlado. Troca um pouco da rigidez intra-bloco por uma recordação dramaticamente maior.
Por que usar Diffusion Forcing no treinamento?
Diffusion Forcing condiciona a geração em prefixos parciais ou mesmo de comprimento zero, ensinando o modelo a manter coerência com contexto mínimo. Isso é útil para edições no meio do clipe, prévias interativas e reinicializações de agentes.
O que é Atenção Local de Quadros e por que FlexAttention é importante?
Atenção Local de Quadros agrupa quadros em blocos com bidirecionalidade dentro de cada bloco e lookback para o bloco anterior. FlexAttention implementa esses padrões de forma eficiente, trazendo acelerações sobre máscaras causais completas.
Onde a indústria poderia adotar o LSSVWM primeiro?
Ferramentas criativas (Adobe), robótica e logística (Amazon, Microsoft), AR/VR de borda (Apple) e pesquisa de agentes multimodais (OpenAI, DeepMind) são candidatos imediatos devido à necessidade de consistência de longo horizonte e baixa latência.



Entendendo a projeção cartográfica de Gall-Peters: benefícios e controvérsias em 2025
A Realidade por Trás do Mapa: Por Que a Projeção Gall-Peters Ainda Importa Cada vez que você olha para um...


como criar um processo seguro de login de link de edifício em 2025
Arquitetando uma Estrutura Robusta de Autenticação na Era da IA A autenticação do usuário define o perímetro da infraestrutura digital...


Principais Ferramentas de IA para Pequenas Empresas: Seleções Essenciais para 2025
Navegando pelo Panorama da IA: Ferramentas Essenciais para o Crescimento de Pequenas Empresas em 2025 O horizonte digital mudou drasticamente....


Escolhendo Entre o ChatGPT da OpenAI e o Falcon: O Melhor Modelo de IA para 2025
O cenário da inteligência artificial mudou drasticamente à medida que navegamos por 2026. A escolha não é mais apenas sobre...


descubra os nomes de conchas mais fascinantes e seus significados
Decodificando os Dados Ocultos das Arquiteturas Marinhas O oceano funciona como um vasto arquivo descentralizado da história biológica. Dentro dessa...


Funko pop notícias: lançamentos recentes e drops exclusivos em 2025
Principais Notícias do Funko Pop em 2025 e o Impacto Contínuo em 2026 O cenário de colecionismo mudou drasticamente nos...


quem é hans walters? revelando a história por trás do nome em 2025
O Enigma de Hans Walters: Analisando a Pegada Digital em 2026 Na vasta extensão de informações disponíveis hoje, poucos identificadores...


Explorando o microsoft building 30: um centro de inovação e tecnologia em 2025
Redefinindo o Espaço de Trabalho: Dentro do Coração da Evolução Tecnológica de Redmond Aninhado entre o verde do extenso campus...


Principais Ferramentas de IA para Assistência em Tarefas Escolares em 2025
A Evolução da IA de Suporte ao Estudante na Sala de Aula Moderna O pânico de um prazo no domingo...


OpenAI vs Mistral: Qual Modelo de IA Vai Melhor Atender às Suas Necessidades de Processamento de Linguagem Natural em 2025?
O panorama da Inteligência Artificial mudou dramaticamente enquanto navegamos por 2026. A rivalidade que definiu o ano anterior—especificamente o choque...


como dizer adeus: maneiras suaves de lidar com despedidas e finais
Navegando na Arte de um Despedida Suave em 2026 Dizer adeus raramente é uma tarefa simples. Quer você esteja pivotando...


gerador de nomes de navios piratas: crie o nome da sua embarcação lendária hoje
Desenhando a Identidade Perfeita para Sua Aventura Marítima Nomear uma embarcação é muito mais do que um simples exercício de...


Desbloqueando a criatividade com prompts de IA Diamond Body em 2025
Dominando o Framework Diamond Body para Precisão em IA No cenário que evolui rapidamente em 2025, a diferença entre uma...


O que é canvas? Tudo o que você precisa saber em 2025
Definindo Canvas na Empresa Digital Moderna No cenário de 2026, o termo “Canvas” evoluiu além de uma definição singular, representando...


como ligar a luz do teclado do seu laptop: um guia passo a passo
Dominando a Iluminação do Teclado: O Guia Essencial Passo a Passo Digitar em uma sala pouco iluminada, durante um voo...


melhores prompts de mockup de livro para midjourney em 2025
Otimização da Visualização de Livros Digitais com Midjourney na Era Pós-2025 O panorama da visualização de livros digitais mudou dramaticamente...


Geradores de Vídeos Adultos Movidos por IA: As Principais Inovações para Ficar de Olho em 2025
A Aurora da Intimidade Sintética: Redefinindo Conteúdo Adulto em 2026 O cenário da expressão digital passou por uma mudança sísmica,...


ChatGPT vs LLaMA: Qual Modelo de Linguagem Dominará em 2025?
A Batalha Colossal pela Supremacia da IA: Ecossistemas Abertos vs. Jardins Murados No cenário em rápida evolução da inteligência artificial,...


Dominando palavras iniciais com ch: dicas e atividades para leitores iniciantes
Decodificando o Mecanismo das Palavras Iniciais com CH na Alfabetização Inicial A aquisição de linguagem em leitores iniciais funciona de...


Howmanyofme review: descubra quão único seu nome realmente é
Desvendando os segredos da identidade do seu nome com dados Seu nome é mais do que apenas uma etiqueta na...
-

 Open Ai1 week ago
Open Ai1 week agoDesbloqueando o Poder dos Plugins do ChatGPT: Melhore Sua Experiência em 2025
-

 Open Ai7 days ago
Open Ai7 days agoDominando o Fine-Tuning do GPT: Um Guia para Customizar Eficazmente Seus Modelos em 2025
-
 Open Ai1 week ago
Open Ai1 week agoComparando o ChatGPT da OpenAI, o Claude da Anthropic e o Bard do Google: Qual Ferramenta de IA Generativa Reinará Suprema em 2025?
-

 Open Ai7 days ago
Open Ai7 days agoPreços do ChatGPT em 2025: Tudo o Que Você Precisa Saber Sobre Tarifas e Assinaturas
-

 Open Ai1 week ago
Open Ai1 week agoO Fim Gradual dos Modelos GPT: O que os Usuários Podem Esperar em 2025
-

 Modelos de IA7 days ago
Modelos de IA7 days agoModelos GPT-4: Como a Inteligência Artificial está Transformando 2025