
Модели ИИ
Можно ли изменить контекстное окно в lmstudio?
Изменение окна контекста в LM Studio: что это и почему это важно
Термин окно контекста описывает, сколько текста языковая модель может учитывать одновременно. В LM Studio (часто сокращаемом до lmstudio практиками) это окно регулирует максимальную длину ввода и объем прошедших разговоров или документов, которые влияют на текущее генерирование текста. Если лимит токенов превышается, важные детали отбрасываются, что может испортить ответы или привести к поверхностному рассуждению. Поэтому настройка размера окна — одна из самых значимых настроек ИИ, доступных каждому, кто запускает модели локально.
Почему вообще менять этот параметр? Команды часто работают с большими PDF-файлами, длинной историей чатов или обширными исходниками. Исследователю, собирающему 30-страничные меморандумы, требуется больше пространства, чем чат-боту на быструю сессию. Разработчик, анализирующий многофайловую кодовую базу, также выигрывает от увеличенного буфера. LM Studio предоставляет параметры модели при загрузке (например, длина контекста) и при инференсе (например, поведение при переполнении), позволяя настраивать конфигурации под разные задачи. Правильный выбор размера — это баланс между скоростью, затратами (в VRAM и RAM) и качеством ответов.
Возьмём «Майю», аналитика данных, которая курирует отчёты по соблюдению нормативов. Если окно настроено слишком узко, Майя замечает, что ссылки исчезают, а упоминания становятся размазанными. После увеличения длины контекста в LM Studio модель сохраняет больше сносок, отвечает точными указаниями и поддерживает последовательную терминологию на сотнях строк. Разница не косметическая — это меняет то, что модель может знать в процессе разговора.
Ключевые причины, по которым пользователи повышают лимит, включают более длинные схемы вызова функций, сложные системные подсказки и многошаговые диалоги с вложенными документами. Конфигурация LM Studio позволяет настраивать поведение за пределами настроек по умолчанию, но важно знать максимумы, специфичные для моделей. Некоторые модели изначально поддерживают 4k–16k токенов; другие декларируют 128k и больше. Фактическая производительность зависит и от обучения модели, и от используемых стратегий во время работы (например, позиционное кодирование и механизмы внимания).
- 🔧 Расширяйте размер окна, чтобы сохранить длинные инструкции и уменьшить усечение.
- 🧠 Улучшайте дедукцию по нескольким документам, сохраняя больше контекста в памяти.
- ⚡ Балансируйте скорость и качество; большие окна могут замедлять генерацию.
- 🛡️ Используйте политики переполнения для управления безопасностью при достижении лимита токенов.
- 📈 Контролируйте компромиссы качества при использовании расширенных техник контекста.
Выбор подходящего размера также зависит от задачи. Для высокоточной помощи в кодировании стоит рассмотреть средний контекст с целенаправленным поиском. Для литературного анализа или правовой проверки полезно большое окно — если модель действительно справляется с этим хорошо. В экосистеме 2025 года сравнения, такие как ChatGPT против Perplexity и OpenAI против Anthropic, показывают, как разные семейства моделей по-разному приоритизируют рассуждения с длинным контекстом. Локальные запуски хотят такого же уровня, но должны правильно настраивать параметры.
| Понятие ✨ | Что контролирует 🧭 | Влияние на результаты 📊 |
|---|---|---|
| Окно контекста | Максимальное количество токенов, которые модель может «увидеть» | Сохранение инструкций и ссылок |
| Размер окна | Длина контекста при загрузке | Задержка, использование памяти, когерентность |
| Политика переполнения | Поведение при достижении лимита | Безопасность, детерминированность или схемы усечения |
| Параметры модели | Масштабирование RoPE, кэш kv и т. п. | Эффективная максимальная длина и стабильность |
| Настройки ИИ | Конфигурация интерфейса LM Studio | Подходящий рабочий процесс для разных задач |
Итог: изменение длины контекста в LM Studio — это не просто переключатель, а стратегический выбор, решающий, сколько модель может запомнить и как глубоко рассуждать за один проход.

Управление LM Studio: политика переполнения, слайдеры и «трюк с красным полем»
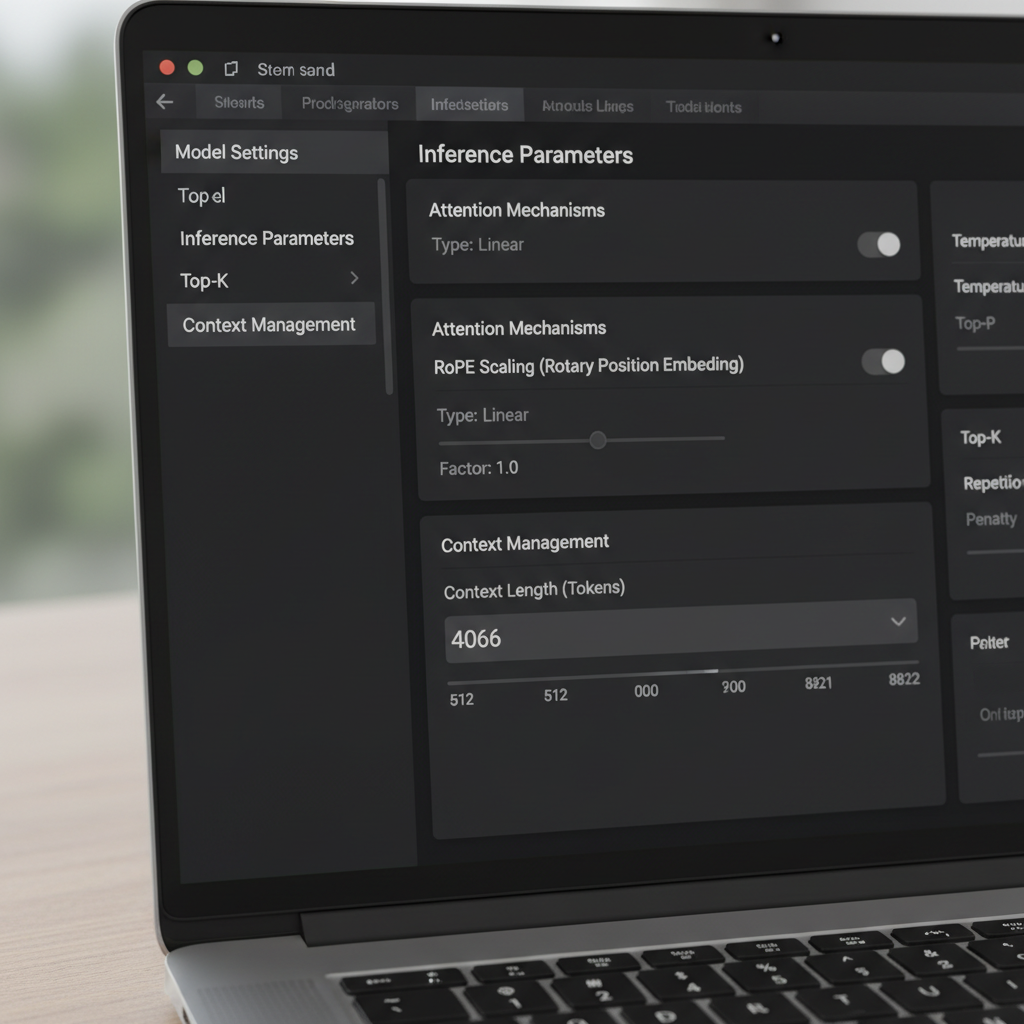
LM Studio предлагает несколько способов изменить окно контекста. В интерфейсе есть слайдер и числовое поле, управляющие настроенным размером окна. Сообщество пользователей сообщало о странности: слайдер ограничен 16k для некоторых квантований, хотя метаданные модели допускают больше (например, 128k). Когда слайдер не желает двигаться дальше вправо, многие просто кликают на числовое поле и вводят нужное количество токенов. Значение может подсветиться красным и показать, что сохранение невозможно — но при этом всё равно применяется во время работы. Это неожиданное поведение позволяет опытным пользователям обходить ограничения интерфейса без специальных инструментов.
Другой важный параметр — Политика переполнения контекста. По умолчанию стоит «сохранять системную подсказку, усекать середину», что может ломать некоторые менеджеры памяти и агенты. Переключение на «Остановиться на лимите» гарантирует, что модель приостановится, а не испортит середину структурированной подсказки. Пользователи, интегрирующие системы памяти или похожие инструменты вроде MemGPT, отметили значительно меньше странностей после перехода на «Остановиться на лимите». Это простое решение сохраняет структуру и предотвращает тихую порчу важных данных.
Важны нюансы версий. Некоторые заметили, что начиная с версии 0.3.24 интерфейс больше не сохраняет размеры контекста выше указанного максимума, что подтолкнуло их либо редактировать скрытые конфиги, либо временно использовать более старую сборку с разрешением ручных значений. Главное понимать, что изменение числового поля часто обновляет параметр времени выполнения, тогда как определённые JSON-записи — лишь метаданные для отображения и не влияют на конвертацию модели. Осознание этой разницы помогает избежать ненужной реквантования или манипуляций с файлами.
Для команд, осваивающих локальные LLM, есть небольшой чеклист избавления от ошибок. Сначала проверьте задокументированный максимум модели. Затем установите в числовом поле LM Studio этот максимум, даже если слайдер ограничен. Далее задайте политику переполнения на «Остановиться на лимите» для структурированных подсказок. И, наконец, протестируйте на синтетическом длинном документе, чтобы убедиться, что содержимое за прежним лимитом теперь распознаётся и корректно ссылается.
- 🧩 Если слайдер ограничен 16k, введите число вручную в поле.
- 🛑 Предпочитайте «Остановиться на лимите», если нужна строгая структура.
- 🧪 Проверьте эффективность с помощью длинной тестовой подсказки.
- 📂 Рассматривайте ограничения config.json как метаданные интерфейса, если нет других указаний.
- 💡 Ведите заметки о версии LM Studio и изменениях поведения с контекстом.
Эти шаги хорошо сочетаются с более широкими оценками. Например, изучение сравнений функций, таких как Gemini против ChatGPT и обзор ChatGPT 2025, помогает сформировать ожидания по производительности с длинным контекстом в различных экосистемах. Наблюдение за приоритетами крупнейших облачных провайдеров также направляет локальные настройки.
| Действие 🔁 | Где в LM Studio 🖥️ | Почему помогает ✅ |
|---|---|---|
| Вводите длину контекста вручную | Числовое поле рядом со слайдером | Обходит ограничение UI в 16k 🪄 |
| Установите переполнение в «Остановиться на лимите» | Настройки инференса | Предотвращает усечение в середине подсказки 🧱 |
| Проверьте метаданные модели | Панель информации о модели | Подтверждает заявленный максимальный размер 📜 |
| Проверка версии | Раздел «О программе» или заметки о релизе | Объясняет изменения поведения сохранения 🗂️ |
| Тест с длинной подсказкой | Чат или вид компоновки | Эмпирическая проверка нового размера окна 🧪 |
Для более глубокого погружения полезны видео-гайды по настройке локальных LLM.

Имея такие инструменты, команды могут с уверенностью выводить LM Studio за пределы дефолтов и защищать подсказки от незаметного усечения.
Выхождение за пределы тренировочных лимитов: масштабирование RoPE и эффективная длина контекста
Расширение контекста — это не только про слайдеры. Многие модели на трансформерах используют Rotary Positional Embeddings (RoPE), а LM Studio открывает параметр при загрузке, который масштабирует позициональную информацию. Увеличение этого коэффициента позволяет модели охватывать более длинные последовательности, делая позиционное кодирование более детальным. Это мощный трюк, но не бесплатный. С ростом коэффициента локальная когерентность может ухудшаться, а некоторые модели начинают сильнее «галлюцинировать» на экстремальных длинах. Знание, когда применять масштабирование RoPE, так же важно, как и как применять.
Документация LM Studio описывает, как коэффициент масштабирования корректирует эффективное окно. На практике это значит, что модель, обученная на 8k, иногда способна работать при 16k–32k с приемлемой потерей качества, в зависимости от архитектуры и квантования. Когда пользователи видят в UI максимальное значение 16k у сборки GGUF, но модель обещает 128k, это часто означает несоответствие метаданных. В таких случаях стоит увеличить значение вручную и проверить на длинном тесте, чтобы уточнить реальный предел. Сообщения сообщества также показывают, что изменение значения, даже если UI подсвечивает его красным, всё равно может применяться при загрузке.
Как далеко можно зайти? Это зависит от семьи моделей и механизма внимания. Подходы типа скользящего окна и гибридных рекуррентных/трансформерных архитектур по-разному переносят длинные контексты по сравнению с обычным вниманием. Интерес к альтернативам, включая модели пространства состояний, вырос по мере изучения длинных последовательностей без взрывного роста памяти. Обсуждения по моделям пространства состояний и использованию памяти объясняют, почему длинный контекст — это не просто число; это вопрос стабильности и архитектуры.
Команда Майи использовала масштабирование RoPE осмотрительно для ежеквартальных сводок. При 24k токенах ответы оставались чёткими. При 48k возросла задержка, а сводки иногда забывали начальные детали, что свидетельствует о затухающей отдаче. В итоге остановились на 32k с дополнением поиска, что сохранило качество и избежало сильного замедления. Вывод: большие окна должны дополнять поиск и разбивку на блоки, а не заменять их.
- 🧮 Начинайте с умеренного масштабирования (например, 1.5–2×) перед дальнейшим увеличением.
- 🧭 Сочетайте длинный контекст с поиском, чтобы модель видела только релевантные части.
- 📉 Следите за ухудшением когерентности при очень больших количествах токенов.
- 🧰 Учитывайте ограничения квантования и VRAM при растяжении окна.
- 🔍 Проверяйте на тестах, специфичных для области, а не на универсальных подсказках.
Сравнительные обзоры, такие как ChatGPT против Gemini в 2025 году и обзоры вех эволюции ChatGPT, дают более широкий контекст о том, как производители подают гонку за длинный контекст. Даже если локальная модель отличается, компромиссы одинаковы в отрасли.
| Выбор масштабирования RoPE 🧯 | Плюсы 🌟 | Минусы ⚠️ | Используйте когда 🎯 |
|---|---|---|---|
| 1.0× (по умолчанию) | Стабильное, предсказуемое поведение | Ограниченная максимальная длина | Для задач, критичных к качеству ✅ |
| 1.5–2.0× | Заметно более длинный контекст | Небольшое снижение когерентности | Отчёты, лёгкий анализ кода 📄 |
| 2.5–4.0× | Длинные сессии с множеством документов | Риски задержек и дрейфа | Исследования exploratory 🔬 |
| 4.0×+ | Экстремально длинные последовательности | Вероятно, нестабильные выходы | Бенчмарки и эксперименты 🧪 |
Практический вывод: масштабирование RoPE может расширить охват, но поиск и инженерия подсказок часто дают более стабильный прирост за токен.
Когда размер окна не меняется: решение проблем с длинным контекстом в LM Studio
Иногда LM Studio не реагирует на изменения. Пользователи сообщали о слайдере с максимумом 16k для некоторых квантований, несмотря на то, что базовая модель заявляет гораздо больше. Другие сталкивались с тем, что новая сборка не позволяет сохранять значения выше, побуждая использовать старую версию или вводить значения вручную несмотря на предупреждающие цвета. Эти проблемы раздражают, но решаемы поэтапным подходом.
Сначала подтвердите заявленный максимум модели. Некоторые карточки сообщества ошибочно указывают 16k из-за ошибки упаковки, в то время как реально модель поддерживает 128k. Затем попробуйте ввести число в текстовое поле; если оно подсвечивается красным, но загружается, вы обошли ограничение слайдера. Третье — задайте политику переполнения «Остановиться на лимите» для предотвращения искажения тщательно составленной системной подсказки. Четвёртое — проверьте с помощью длинного тестового текста, попросив модель суммировать ранние, средние и поздние разделы — чтобы доказать полное видение.
Если LM Studio всё равно отказывается, проверьте, не ограничивает ли жёстко квантованная версия модель. Некоторые конверсии GGUF включают дефолтный контекст, отличный от оригинальной модели. Поскольку лимит часто является метаданными для отображения, а не жёстким потолком, подход с текстовым полем обычно срабатывает; при этом стоит смотреть логи загрузки. Также убедитесь, что VRAM хватает. Очень большие окна растягивают кэш ключей и значений, вызывая замедления и ошибки нехватки памяти. В случае сбоев уменьшайте контекст, используйте менее точное квантование или разбивайте задачу на части.
За пределами LM Studio рекомендуется отслеживать, как ведущие модели работают с длинными подсказками на практике. Анализы вроде ChatGPT vs Claude и глубокие обзоры, например, как DeepSeek снижает стоимость обучения, формируют ожидания. Длинный контекст важен, только если модель действительно его использует; иначе поиск или лучшая структура подсказок превзойдут простое увеличение размера.
- 🧰 Если слайдер останавливается на 16k, попробуйте числовое поле.
- 🧯 Для структурированных задач переключитесь на «Остановиться на лимите».
- 🧠 Проверяйте понимание ранних/средних/поздних частей с длинной подсказкой.
- 🖥️ Следите за VRAM; большой контекст сильно увеличивает кэш KV.
- 📜 Просматривайте логи загрузки ради применённой длины контекста.
| Симптом 🐞 | Вероятная причина 🔎 | Решение 🛠️ |
|---|---|---|
| Слайдер ограничен 16k | Глюк интерфейса или метаданных | Вводите длину в числовом поле ➕ |
| Красное предупреждение при сохранении | Проверка валидности, а не жесткое ограничение | Загрузите модель и проверьте логи 🚦 |
| OOM или замедление | Взрыв кэша ключей и значений | Уменьшите контекст или используйте более лёгкое квантование 🧮 |
| Потеря структуры | Усечение в середине | Установите переполнение на «Остановиться на лимите» 🧱 |
| Несогласованность с документацией | Метаданные конверсии | Проверяйте логи и проводите тесты с длинной подсказкой 🔍 |
Для визуалов полезны видеообходы по тестированию и бенчмаркингу длинного контекста.

С дисциплинированным чеклистом упрямые лимиты контекста становятся временными неудобствами, а не блокерами.
Выбор правильного размера для локальной генерации текста: руководства, тестирование и стратегия
Нет универсального «лучшего» размера окна. Правильный выбор зависит от задачи, семейства модели и аппаратного обеспечения. Помощник по коду выигрывает от среднего окна с поиском по наиболее релевантным файлам. Юрист может выбрать большее окно, но все равно применять разбивку, чтобы не утопить модель в нерелевантных страницах. Подкастер, набирающий сводки эпизодов по длинным транскриптам, комбинирует щедрый контекст с умной сегментацией для сохранения когерентности.
Практический подход — «лестничный тест»: начать с задокументированного максимума, затем снижать или повышать, проверяя задержку и точность. Используйте длинные, специфичные для предметной области данные и проверяйте, что ранние и поздние разделы учитываются. Если модель забывает начало при больших размерах, уменьшите окно или применяйте масштабирование RoPE осторожно. Если очень длинные подсказки важны, дополняйте поиск, чтобы модель видела вырезанные участки, а не архив целиком.
Полезно сравнивать ожидания, читая обзоры, например, ChatGPT против GitHub Copilot и отраслевые итоги, такие как освещение судебного дела «bend time». Эти ссылки дают контекст о подходах экосистем к длинным вводам и разработческим рабочим процессам. Помимо этого, руководства по операционной теме — например, мастерство с API ключами ChatGPT — показывают, как детали настройки влияют на эффективность работы.
- 🪜 Используйте лестничные тесты, чтобы найти оптимум для вашего оборудования.
- 📚 Сочетайте длинные окна с поиском и разбивкой для точности.
- ⏱️ Отслеживайте изменение задержки с ростом окна и корректируйте.
- 🧭 Предпочитайте «Остановиться на лимите» для хрупких, структурированных подсказок.
- 🧪 Проверяйте качество на задачах, приближённых к реальным нагрузкам.
| Сценарий использования 🎬 | Рекомендуемый контекст 📏 | Политика переполнения 🧱 | Примечания 🗒️ |
|---|---|---|---|
| Помощник по коду | 8k–24k | Остановиться на лимите | В паре с поиском по файлам 💼 |
| Юридическая проверка | 32k–64k | Остановиться на лимите | Разбивка по разделам; сохранение видимых ссылок 📖 |
| Транскрипты подкастов | 16k–48k | Остановиться на лимите | Тезисное резюмирование по сегментам, затем объединение 🎙️ |
| Синтез исследований | 24k–64k | Остановиться на лимите | Масштабирование RoPE с тщательной проверкой 🔬 |
| Общий чат | 4k–16k | Остановиться на лимите | Архивирование старых ходов, выборочный поиск 💬 |
Эти руководства сочетаются с практическими рыночными обзорами — смотрите анализы, такие как инновации в системах рассуждений и обзор нишевых ИИ-чатов, чтобы понять, как разные инструменты выдвигают или ограничивают длинные контекстные процессы. Метод прост: настройте размер окна под задачу и подтвердите его тестами, отражающими реальность.
Реальные заметки сообщества: версии, метаданные и безопасные практики
Обратная связь сообщества выявила несколько важных истин об изменении окна контекста в LM Studio. Часто встречается история про «Q4KM показывает максимум 16k», которая оказалась вопросом метаданных, а не жёстким лимитом. Также отмечается, что числовое поле UI принимает значения выше слайдера, даже если подсвечено красным, и эти значения применяются при загрузке. Пользователи подтверждают, что длина контекста в некоторых конфигурациях больше влияет на отображение, чем на конвертацию, что объясняет, почему правки вроде бы ничего не меняют, но время выполнения использует другое значение.
Стоит уделить внимание поведению версий. В сборке 0.3.24 был ужесточён механизм сохранения значений выше максимума, что заставило некоторых откатиться до более старой, разрешающей ручной ввод. Независимо от версии, самая надёжная практика — вводить целевое значение, устанавливать переполнение на «Остановиться на лимите» и проверять с длинными данными. При сомнениях полагайтесь на логи, а не на слайдер. Ясность о разделении метаданных и жёстких лимитов экономит много времени.
Аппаратные особенности и планирование тоже важны. Очень большие окна увеличивают кэш KV и замедляют отклик. Для продолжительной работы лучше снизить размер контекста или сочетать умеренный размер с поиском. Стратегические статьи — например, роль NVIDIA в масштабировании инфраструктуры ИИ — напоминают, что оптимизация — это процесс от начала до конца. Практические списки, такие как частые коды ошибок ChatGPT, помогают при устранении неполадок.
Наконец, полезно сверять предположения с более широкими сравнительными обзорами. Чтение сравнения ChatGPT с Perplexity или анализ региональных трендов доступа помогает сформировать ожидания работы с длинным контекстом за пределами одного инструмента. Хотя LM Studio предоставляет локальный тонкий контроль, практики, импортируемые из облачной среды, иногда требуют адаптации под локальный хардвар и квантование.
- 📌 Рассматривайте «максимум 16k» в UI с подозрением; подтверждайте через логи и тесты.
- 🧭 Предпочитайте ввод чисел вручную, если слайдер не совпадает.
- 🧱 Используйте «Остановиться на лимите» для защиты структурированных подсказок и агентов.
- 🧮 Следите за VRAM и квантованием; длинные окна дорогие в ресурсах.
- 🧪 Проверяйте с задачами, имитирующими реальные длительные нагрузки.
| Мнение сообщества 🗣️ | Что это значит 💡 | Практический шаг 🚀 |
|---|---|---|
| Слайдер ограничен рано | Вероятный сбой UI/метаданных | Вводите значение вручную, затем тестируйте 📏 |
| Красное поле всё равно работает | Предупреждение валидности, а не ограничение | Загружайте модель и смотрите логи 🚦 |
| Конфиг и конверсия различаются | Некоторые записи — только метаданные | Не переконвертируйте; настройте параметр времени выполнения 🧰 |
| Переменчивость версии | Поведение менялось в разных сборках | Держите стабильный установщик под рукой 🗃️ |
| Длинный контекст дорог | Кэш KV растёт с числом токенов | Правильно подберите размер окна, используйте поиск 🧠 |
Для более широкой перспективы сравнения, такие как OpenAI против Anthropic и редакционные обзоры, например, стратегические решения по талантам в технологиях, показывают, почему владение настройками так же важно, как и выбор модели. Главный вывод: проверяйте, тестируйте и документируйте именно те настройки, которые реально влияют на ваши задачи.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Можно ли увеличить окно контекста выше ограничения слайдера в LM Studio?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Да. Нажмите числовое поле рядом со слайдером и введите нужное количество токенов. Даже если поле подсветится красным, LM Studio часто применяет значение при загрузке. Подтвердите это через логи и тест с длинной подсказкой.”}},{“@type”:”Question”,”name”:”Какая политика переполнения самая безопасная для структурированных подсказок?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”«Остановиться на лимите». Она предотвращает усечение в середине подсказки, защищая системные подсказки, схемы функций и форматы инструментов. Особенно полезна для рабочих процессов с агентами и больших сессий с памятью.”}},{“@type”:”Question”,”name”:”Обеспечивает ли масштабирование RoPE хорошую работу с длинным контекстом?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Нет. Масштабирование RoPE может расширить эффективный контекст, но при очень больших длинах может снизить когерентность. Используйте умеренное масштабирование, проверяйте на реальных задачах и дополняйте поиском для надёжных результатов.”}},{“@type”:”Question”,”name”:”Почему некоторые модели показывают максимум 16k, если карточка говорит о 128k?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Такое несоответствие часто связано с метаданными в пакете конверсии. Попробуйте ввести большее значение вручную и проверьте применённую длину при работе; рассматривайте слайдер как рекомендательный, а не регулирующий.”}},{“@type”:”Question”,”name”:”Как выбрать правильный размер окна для локальной генерации текста?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Используйте лестничные тесты: начинайте с задокументированного максимума, оценивайте задержку и качество, затем корректируйте. Сочетайте умеренный размер окна с поиском и устанавливайте переполнение на «Остановиться на лимите» для структурированных задач.”}}]}Можно ли увеличить окно контекста выше ограничения слайдера в LM Studio?
Да. Нажмите числовое поле рядом со слайдером и введите нужное количество токенов. Даже если поле подсветится красным, LM Studio часто применяет значение при загрузке. Подтвердите это через логи и тест с длинной подсказкой.
Какая политика переполнения самая безопасная для структурированных подсказок?
«Остановиться на лимите». Она предотвращает усечение в середине подсказки, защищая системные подсказки, схемы функций и форматы инструментов. Особенно полезна для рабочих процессов с агентами и больших сессий с памятью.
Обеспечивает ли масштабирование RoPE хорошую работу с длинным контекстом?
Нет. Масштабирование RoPE может расширить эффективный контекст, но при очень больших длинах может снизить когерентность. Используйте умеренное масштабирование, проверяйте на реальных задачах и дополняйте поиском для надёжных результатов.
Почему некоторые модели показывают максимум 16k, если карточка говорит о 128k?
Такое несоответствие часто связано с метаданными в пакете конверсии. Попробуйте ввести большее значение вручную и проверьте применённую длину при работе; рассматривайте слайдер как рекомендательный, а не регулирующий.
Как выбрать правильный размер окна для локальной генерации текста?
Используйте лестничные тесты: начинайте с задокументированного максимума, оценивайте задержку и качество, затем корректируйте. Сочетайте умеренный размер окна с поиском и устанавливайте переполнение на «Остановиться на лимите» для структурированных задач.



Какой будет топовый ИИ для создания впечатляющего резюме в 2025 году?
Каким будет лучший ИИ для создания впечатляющего резюме в 2025 году? Критерии, которые отличают победителей от остальных В конкурентных процессах...


Newsearch в 2025 году: чего ожидать от следующего поколения онлайн-поисковых систем
Newsearch в 2025 году: генеративный ИИ превращает онлайн-поисковики в ассистентов Поиск перестал быть простым списком синих ссылок. Он превратился в...


Chya объяснила: преимущества, применение и побочные эффекты в 2025 году
Чя объяснена в 2025 году: доказанные преимущества для здоровья, антиоксиданты и высокая питательность Чя — более широко известная как чая...


xr обновление: ключевые новости и инсайты vr на 2025 год
Обновление XR 2025: Новости корпоративной VR, сигналы по ROI и прорывы в секторах Обновление XR в корпоративной среде демонстрирует решительный...


Как освоить игру “Space Bar Clicker” в 2025 году
Основы игры в Space Bar Clicker: CPS, циклы обратной связи и мастерство в начале игры Игры в жанре space bar...


i bubble letter: креативные идеи и уроки для начинающих
Как нарисовать пузырчатую букву i: пошаговое руководство для абсолютных новичков Начинать с маленькой пузырчатой буквы i — умный способ изучить...


Представляем бесплатную версию ChatGPT, разработанную специально для преподавателей
Почему бесплатный ChatGPT для педагогов важен: безопасное рабочее пространство, административный контроль и специализированные инструменты для преподавания Бесплатный ChatGPT, адаптированный для...


Всеобъемлющий обзор технологического ландшафта Пало-Альто к 2025 году
Платформизация на базе ИИ в технологическом ландшафте Palo Alto: переосмысленные операции безопасности Технологический ландшафт Palo Alto решительно сместился в сторону...


Действительно ли AP Physics настолько сложен? Что студентам следует знать в 2025 году
Действительно ли AP Physics настолько сложен в 2025 году? Данные, процент сдачи и что на самом деле важно Спросите группу...


ChatGPT Сервис Прерван: Пользователи Испытывают Отключения Из-за Перебоев в Cloudflare | Hindustan Times
Сбой сервиса ChatGPT: перебои в Cloudflare вызвали глобальные отключения и ошибки 500 Волны нестабильности прокатились по сети, когда перебой в...


Лучшие ИИ для написания текстов 2025 года: всестороннее сравнение и руководство пользователя
Лучшие писательские ИИ 2025 года: сравнение производительности и реальные кейсы Выбор писательского ИИ в 2025 году похож на покупку камеры:...


Понимание остаточного изображения: причины, предотвращение и решения
Понимание остаточного изображения и выгорания экрана: определения, симптомы и динамика послеобраза на дисплее Остаточное изображение описывает слабый послеобраз на дисплее,...


Можно ли изменить контекстное окно в lmstudio?
Изменение окна контекста в LM Studio: что это и почему это важно Термин окно контекста описывает, сколько текста языковая модель...


Как получить текущее время в swift
Основы Swift: как получить текущее время с помощью Date, Calendar и DateFormatter Получить текущее время в Swift достаточно просто, но...


Как детекторы вейпов меняют безопасность в школах в 2025 году
Как детекторы вейпа меняют безопасность в школах в 2025 году: видимость на основе данных без излишнего контроля На всех площадках,...


Питает ли ИИ бредовые мысли? Растут опасения среди семей и экспертов
Подпитывает ли ИИ бред? Семьи и эксперты отслеживают тревожную закономерность Сообщения о бредах, подкрепляемых ИИ, перестали быть случайными историями и...


Как создавать и управлять окружениями Python с помощью conda env create в 2025 году
Создание окружения Conda в 2025 году: пошаговое построение изолированных, воспроизводимых Python-окружений Чистая изоляция — основа надежных Python-проектов. С помощью conda...


Откройте возможности группового чата ChatGPT бесплатно: пошаговое руководство по началу работы
Как получить бесплатный доступ и начать групповую беседу ChatGPT: пошаговое руководство для начала работы Групповая беседа ChatGPT перешла от пилотного...


Как максимизировать ваши выгоды от моих оценок в 2025 году
Как максимизировать свои выгоды от моих оценок в 2025 году: стратегия, ROI и исполнение Оценки 2025 года ценны ровно настолько,...

Планируйте свой следующий отдых прямо здесь: TripAdvisor запускает интегрированное приложение внутри ChatGPT
Интегрированное приложение TripAdvisor в ChatGPT: революция в планировании путешествий и бронировании поездок Появление интегрированного приложения TripAdvisor внутри ChatGPT выводит планирование...
-

 Модели ИИ20 hours ago
Модели ИИ20 hours agoвьетнамские модели 2025: новые лица и восходящие звезды, за которыми стоит следить
-

 Модели ИИ3 days ago
Модели ИИ3 days agoКак выбрать оптимальный ИИ для написания эссе в 2025 году
-
Uncategorized15 hours ago
Питает ли ИИ бредовые мысли? Растут опасения среди семей и экспертов
-
Технологии7 hours ago
Всеобъемлющий обзор технологического ландшафта Пало-Альто к 2025 году
-

 Технологии3 days ago
Технологии3 days agoВаша карта не поддерживает этот тип покупки: что это значит и как решить проблему
-
Uncategorized17 hours ago
Откройте возможности группового чата ChatGPT бесплатно: пошаговое руководство по началу работы