
Modèles d’IA
Pouvez-vous changer la fenêtre de contexte dans lmstudio ?
Changer la fenêtre de contexte dans LM Studio : ce que c’est et pourquoi c’est important
Le terme fenêtre de contexte décrit la quantité de texte qu’un modèle de langage peut considérer à la fois. Dans LM Studio (souvent abrégé en lmstudio par les praticiens), cette fenêtre régit la longueur d’entrée maximale et la quantité de conversation passée ou de documents qui influencent la génération de texte en cours. Si la limite de tokens est dépassée, des détails importants sont tronqués, ce qui peut fausser les réponses ou produire un raisonnement superficiel. Ajuster la taille de la fenêtre est donc l’un des paramètres IA les plus déterminants disponibles pour quiconque utilise des modèles localement.
Pourquoi la changer ? Les équipes manipulent souvent de gros PDF, des historiques de discussion étendus ou de longs fichiers sources. Un chercheur compilant des mémos de 30 pages a besoin de plus d’espace que pour un chatbot rapide. Un développeur analysant une base de code multi-fichiers bénéficie aussi d’un tampon plus grand. LM Studio expose les paramètres du modèle au chargement (par exemple, la longueur du contexte) et au moment de l’inférence (par exemple, le comportement en cas de dépassement), permettant des configurations adaptées à différentes charges de travail. Choisir la bonne taille signifie équilibrer rapidité, coût (en VRAM et RAM) et fidélité des réponses.
Considérons “Maya”, une analyste de données qui établit des rapports de conformité. Quand la fenêtre est trop serrée, Maya voit disparaître les citations et les références deviennent vagues. Après avoir augmenté la longueur du contexte dans LM Studio, le modèle conserve davantage de notes de bas de page, répond avec des références précises et maintient une terminologie cohérente sur plusieurs centaines de lignes. La différence n’est pas cosmétique ; elle change ce que le modèle peut connaître en pleine conversation.
Les raisons clés pour lesquelles les utilisateurs augmentent la limite incluent aussi des schémas d’appel de fonction plus longs, des prompts système complexes et des conversations multi-tours accompagnées de documents. La configuration de LM Studio leur permet d’ajuster le comportement au-delà des valeurs par défaut, mais la connaissance des maxima spécifiques au modèle est essentielle. Certains modèles sont livrés par défaut avec 4k–16k tokens ; d’autres annoncent 128k ou plus. La performance réelle dépend à la fois de l’entraînement du modèle et de l’approche au runtime (par exemple, l’encodage positionnel et les stratégies d’attention).
- 🔧 Agrandir la taille de la fenêtre pour préserver les instructions longues et réduire la troncature.
- 🧠 Améliorer le raisonnement multi-documents en conservant plus de contexte en mémoire.
- ⚡ Équilibrer vitesse et qualité ; les fenêtres plus larges peuvent ralentir la génération.
- 🛡️ Utiliser des politiques de dépassement pour contrôler la sécurité quand la limite de tokens est atteinte.
- 📈 Surveiller les compromis de qualité lors de l’utilisation de techniques de contexte étendu.
Choisir la bonne taille dépend aussi de la tâche. Pour une assistance au codage de haute précision, considérez un contexte moyen plus une récupération ciblée. Pour l’analyse littéraire ou la revue juridique, une grande fenêtre est utile—si le modèle peut vraiment la gérer. Dans l’écosystème de 2025, des comparaisons comme ChatGPT versus Perplexity et OpenAI versus Anthropic montrent comment les familles de modèles priorisent différemment le raisonnement sur long contexte. Les exécutions locales veulent cette puissance, mais doivent la configurer judicieusement.
| Concept ✨ | Ce que ça contrôle 🧭 | Impact sur les résultats 📊 |
|---|---|---|
| Fenêtre de contexte | Nombre maximal de tokens que le modèle peut “voir” | Rétention des instructions et références |
| Taille de la fenêtre | Longueur du contexte au chargement | Latence, utilisation mémoire, cohérence |
| Politique de dépassement | Comportement à la limite | Sécurité, déterminisme ou modèles de troncature |
| Paramètres du modèle | Mise à l’échelle RoPE, cache kv, etc. | Longueur max effective et stabilité |
| Paramètres IA | Configuration UI dans LM Studio | Adaptation du flux de travail selon les tâches |
En résumé : changer la longueur du contexte LM Studio n’est pas un simple interrupteur—c’est un choix stratégique qui décide combien le modèle peut se souvenir et raisonner en une seule passe.

Contrôles LM Studio : politique de dépassement, curseurs, et l’astuce de la “boîte rouge”
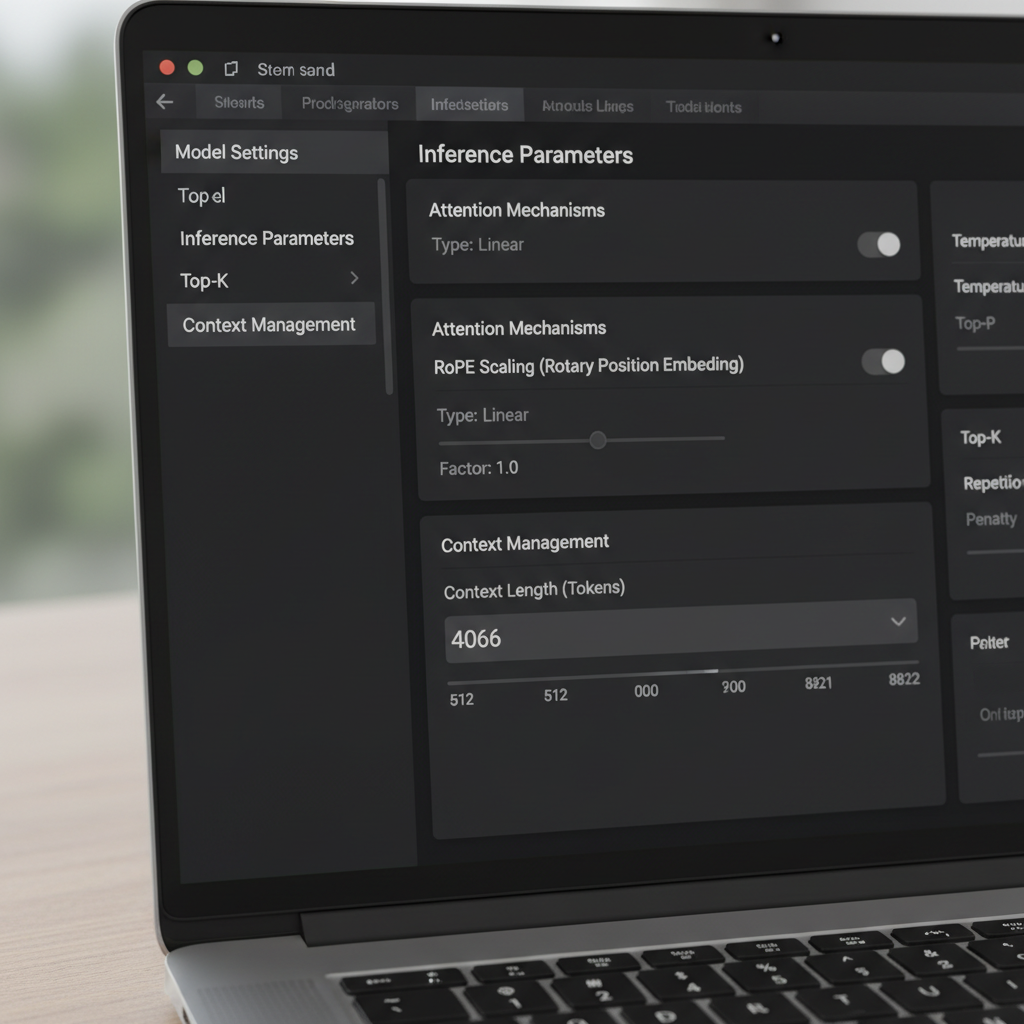
LM Studio offre plusieurs moyens pour modifier la fenêtre de contexte. Dans l’interface, un curseur et un champ numérique régissent la taille de la fenêtre configurée. Une bizarrerie rapportée par la communauté est un curseur plafonné à 16k pour certaines quantifications, bien que les métadonnées du modèle sous-jacent en supportent davantage (par exemple, 128k). Quand le curseur refuse d’aller plus à droite, beaucoup d’utilisateurs cliquent simplement sur la boîte numérique et saisissent le nombre de tokens souhaité. La valeur peut devenir rouge et indiquer qu’elle ne sera pas enregistrée—mais elle s’applique quand même au runtime. Ce comportement surprenant permet aux utilisateurs avancés de contourner les frictions UI sans outils personnalisés.
Un autre réglage critique est la Politique de dépassement du contexte. La valeur par défaut “garder le prompt système, tronquer le milieu” peut perturber certains gestionnaires de mémoire et agents. Passer à Arrêter à la limite assure que le modèle s’arrête au lieu de détruire le milieu d’un prompt structuré. Les utilisateurs intégrant des frameworks de mémoire ou des outils similaires à MemGPT ont constaté bien moins d’anomalies avec “Arrêter à la limite.” C’est une correction simple qui préserve la structure et évite la corruption silencieuse de textes importants.
Les nuances de version comptent. Certains ont observé que, dès une build 0.3.24 particulière, l’UI ne sauvegarde plus les tailles de contexte au-delà du maximum annoncé, les poussant soit à éditer des fichiers de config cachés, soit à lancer temporairement une build antérieure autorisant les valeurs manuelles. L’idée clé est que changer le champ numérique met souvent à jour un paramètre runtime, tandis que certaines entrées JSON sont des métadonnées d’affichage et n’affectent pas la conversion du modèle. Comprendre cette distinction évite des re-quantifications ou manipulations inutiles.
Pour les équipes qui débutent avec des LLM locaux, un petit guide réduit les erreurs. D’abord, vérifiez le maximum de contexte documenté du modèle. Ensuite, ajustez le champ numérique de LM Studio à ce maximum, même si le curseur plafonne tôt. Troisièmement, réglez le dépassement sur “Arrêter à la limite” pour les prompts structurés. Enfin, testez avec un long document synthétique pour confirmer que le contenu au-delà du plafond précédent est désormais reconnu et référencé correctement.
- 🧩 Si le curseur plafonne à 16k, tapez le nombre directement dans la boîte.
- 🛑 Préférez Arrêter à la limite quand vous avez besoin d’une structure stricte.
- 🧪 Validez avec un prompt factice long pour prouver que le changement a pris effet.
- 📂 Considérez les limites de config.json comme des métadonnées UI sauf indication contraire.
- 💡 Notez la version de LM Studio et le changelog pour comprendre le comportement sur la longueur de contexte.
Ces étapes s’accordent bien avec des évaluations plus larges. Par exemple, lire les décompositions de fonctionnalités comme Gemini versus ChatGPT et la revue ChatGPT 2025 aide à cadrer les attentes sur la performance long contexte entre écosystèmes. Observer où les géants du cloud insistent sur le contexte guide aussi les réglages locaux.
| Action 🔁 | Où dans LM Studio 🖥️ | Pourquoi c’est utile ✅ |
|---|---|---|
| Tapez manuellement la longueur du contexte | Champ numérique à côté du curseur | Contourne le plafond UI de 16k 🪄 |
| Réglez le dépassement sur “Arrêter à la limite” | Paramètres d’inférence | Évite la troncature en cours de prompt 🧱 |
| Vérifiez les métadonnées du modèle | Panneau d’informations du modèle | Confirme la longueur max annoncée 📜 |
| Vérification de version | À propos ou notes de version | Explique les changements dans la sauvegarde 🗂️ |
| Test de prompt long | Vue chat ou composition | Validation empirique de la nouvelle taille 🧪 |
Pour aller plus loin sur les habitudes de configuration et les comparaisons pratiques, des guides vidéo sur la mise en place de LLM local sont utiles.

Armées de ces contrôles, les équipes peuvent pousser LM Studio au-delà des valeurs par défaut et protéger leurs prompts contre une troncature furtive.
Dépasser les limites d’entraînement : mise à l’échelle RoPE et longueur de contexte effective
Étendre le contexte ne passe pas seulement par des curseurs. Beaucoup de modèles basés sur transformers s’appuient sur des Rotary Positional Embeddings (RoPE), et LM Studio expose un paramètre au chargement qui met à l’échelle les informations positionnelles. Augmenter ce facteur permet aux modèles de traiter des séquences plus longues en rendant l’encodage positionnel plus granulaire. C’est une astuce puissante—mais coûteuse. À mesure que le facteur augmente, la cohérence locale peut décliner, et certains modèles hallucinent davantage à des longueurs extrêmes. Savoir quand utiliser la mise à l’échelle RoPE est aussi important que savoir comment l’appliquer.
La documentation de LM Studio décrit comment un facteur d’échelle ajuste la fenêtre effective. En pratique, cela signifie qu’un modèle entraîné pour 8k peut parfois fonctionner entre 16k et 32k avec une perte de qualité tolérable, selon l’architecture et la quantification. Quand des utilisateurs signalent une build GGUF affichant un maximum 16k dans l’UI alors que le modèle en amont promet 128k, cela indique souvent un décalage dans les métadonnées. Dans ces cas, augmenter la valeur numérique et valider avec un long test de conversation clarifie le plafond réel. La communauté rapporte aussi qu’éditer la valeur—même si l’UI la met en rouge—peut toujours appliquer la longueur voulue au chargement.
Jusqu’où peut-on aller ? Cela dépend de la famille de modèles et du mécanisme d’attention. Des approches comme l’attention fenêtre-glissante et les architectures hybrides récurrentes/transformers tolèrent les longs contextes différemment de l’attention pure. L’intérêt pour des alternatives, incluant les approches espace-état, a augmenté alors que les équipes explorent des séquences plus longues sans explosion mémoire. Les discussions autour des modèles espace-état et usage mémoire expliquent pourquoi long-contexte n’est pas qu’un nombre ; c’est une question de stabilité et d’architecture.
L’équipe de Maya a utilisé la mise à l’échelle RoPE avec prudence pour des synthèses trimestrielles. À 24k tokens, les réponses restaient précises. À 48k, la latence augmentait et les synthèses oubliaient parfois des détails initiaux, suggérant des rendements décroissants. Ils ont choisi 32k avec augmentation par récupération, ce qui préservait la qualité tout en évitant d’énormes ralentissements. La leçon : les fenêtres plus larges doivent compléter la récupération et la découpe, pas les remplacer.
- 🧮 Commencez par une mise à l’échelle modérée (ex. 1,5–2×) avant d’aller plus loin.
- 🧭 Combinez long contexte avec récupération pour que le modèle ne voit que les tranches pertinentes.
- 📉 Surveillez la cohérence aux nombres de tokens très élevés.
- 🧰 Gardez à l’esprit la quantification et les limites VRAM en étendant la fenêtre.
- 🔍 Validez avec des tests longs spécifiques au domaine plutôt qu’avec des prompts génériques.
Des articles comparatifs tels que ChatGPT vs. Gemini en 2025 et des vues d’ensemble comme les étapes clés de l’évolution de ChatGPT offrent un contexte plus large sur la manière dont les fournisseurs abordent la course au long contexte. Même si le modèle local diffère, les compromis résonnent dans tout le domaine.
| Choix de mise à l’échelle RoPE 🧯 | Avantages 🌟 | Inconvénients ⚠️ | Utilisation recommandée 🎯 |
|---|---|---|---|
| 1.0× (par défaut) | Comportement stable et prévisible | Longueur max limitée | Tâches où la qualité est cruciale ✅ |
| 1.5–2.0× | Contexte nettement plus long | Léger impact sur la cohérence | Rapports, analyses légères de code 📄 |
| 2.5–4.0× | Sesssions multi-documents larges | Risques de latence et dérive | Recherche exploratoire 🔬 |
| 4.0×+ | Séquences extrêmes | Sorties probablement instables | Benchmarks et expérimentations 🧪 |
L’aperçu pragmatique : la mise à l’échelle RoPE peut étendre la portée, mais la récupération et l’ingénierie de prompt apportent souvent des gains plus stables par token.
Quand la taille de la fenêtre ne bouge pas : dépannage des problèmes de long contexte dans LM Studio
Parfois, LM Studio résiste aux modifications. Des utilisateurs ont rapporté un curseur “max 16k” pour certaines quantifications, alors que le modèle de base annonce bien plus. D’autres ont vu une build récente empêcher la sauvegarde de valeurs plus élevées, les incitant à utiliser temporairement une version antérieure ou à taper les valeurs directement malgré les avertissements en couleur. Ces problèmes sont frustrants mais résolubles avec une checklist systématique.
Premièrement, confirmez le maximum annoncé du modèle. Certaines cartes communautaires indiquent incorrectement 16k à cause d’une erreur d’emballage, alors que le modèle réel supporte 128k. Deuxièmement, essayez de taper le nombre dans le champ texte ; s’il devient rouge mais charge quand même, vous avez contourné le plafond du curseur. Troisièmement, réglez la politique de dépassement sur “Arrêter à la limite” pour éviter de déformer un prompt système soigneusement conçu. Quatrièmement, validez avec un long ensemble de paragraphes factices et demandez au modèle de résumer les sections initiales, médianes et finales pour prouver qu’il a une visibilité complète.
Si LM Studio refuse toujours, envisagez si la variante de quantification a un plafond dur dans ses métadonnées. Certaines conversions GGUF intègrent un contexte par défaut différent du modèle original. Parce que cette limite peut être une métadonnée d’affichage plutôt qu’un plafond véritable, l’approche du champ texte suffit souvent ; surveillez aussi les logs au chargement pour confirmer. Assurez-vous aussi que la VRAM est suffisante. Les grandes fenêtres gonflent le cache key-value, provoquant ralentissements ou erreurs de mémoire. Si les plantages persistent, réduisez un peu le contexte, utilisez une quantification moins précise ou découpez la tâche en morceaux.
Au-delà de LM Studio, il est sage de suivre comment les modèles leaders gèrent les longs prompts en pratique. Des analyses comme ChatGPT vs. Claude et des articles plus approfondis tels que comment DeepSeek rend l’entraînement abordable informent sur les attentes. Le long contexte est pertinent seulement si le modèle l’utilise fidèlement ; sinon, la récupération ou une meilleure structure du prompt surpasseront une simple augmentation de la taille.
- 🧰 Si le curseur s’arrête à 16k, essayez quand même le champ numérique.
- 🧯 Changez la politique de dépassement en “Arrêter à la limite” pour les tâches structurées.
- 🧠 Validez la compréhension début/milieu/fin avec un prompt synthétique long.
- 🖥️ Surveillez la VRAM ; un contexte élevé multiplie la mémoire du cache KV.
- 📜 Vérifiez les logs au chargement pour la longueur de contexte appliquée.
| Symptôme 🐞 | Cause probable 🔎 | Solution 🛠️ |
|---|---|---|
| Curseur plafonné à 16k | Quirk UI ou métadonnées | Tapez la longueur dans le champ numérique ➕ |
| Avertissement rouge à la sauvegarde | Validation, pas de blocage dur | Chargez pour confirmer que ça s’applique 🚦 |
| Erreur mémoire ou ralentissement | Explosion du cache KV | Réduisez le contexte ou utilisez une quantification plus légère 🧮 |
| Perte de structure | Troncature au milieu | Réglez le dépassement sur “Arrêter à la limite” 🧱 |
| Décalage avec la documentation | Métadonnées de conversion | Vérifiez les logs et faites un test de prompt long 🔍 |
Pour les apprenants visuels, des tutoriels sur les tests et benchmarks de long contexte sont précieux.

Avec une checklist disciplinée, les limites tenaces de contexte deviennent une nuisance temporaire plutôt qu’un blocage.
Choisir la bonne taille pour la génération locale de texte : guides pratiques, tests et stratégie
Il n’existe pas de meilleure taille de fenêtre universelle. Le bon choix découle de la tâche, de la famille de modèles et du matériel. Un assistant de codage profite d’une fenêtre moyenne plus une récupération des fichiers les plus pertinents. Un chercheur juridique privilégiera une grande fenêtre mais s’appuiera aussi sur le découpage pour éviter de noyer le modèle sous des pages hors sujet. Un podcasteur rédigeant des résumés d’épisodes longs peut combiner un contexte généreux avec un bon découpage pour maintenir la cohérence.
Une approche pratique est le “test en échelle” : commencez avec le maximum documenté, puis ajustez à la baisse ou à la hausse en vérifiant la latence et la précision. Utilisez des entrées longues spécifiques au domaine et vérifiez que les sections initiales et finales sont toutes deux référencées. Si le modèle semble oublier le début avec des tailles plus grandes, réduisez la fenêtre ou appliquez la mise à l’échelle RoPE avec prudence. Là où les prompts ultra-longs sont essentiels, complétez par récupération pour que le modèle ne voie qu’une tranche sélectionnée plutôt que l’archive entière.
Il aide aussi de cadrer les attentes par des benchmarks en lisant des comparatifs comme ChatGPT vs. GitHub Copilot et des aperçus industriels plus larges tels que la couverture du procès “bend time”. Ces références offrent du contexte sur la manière dont différents écosystèmes traitent les longues entrées et les flux de travail développeurs. Parallèlement, des guides sur des sujets opérationnels — comme maîtriser les clés API ChatGPT — soulignent comment les détails de configuration s’imbriquent en gains de productivité réels.
- 🪜 Utilisez des tests en échelle pour trouver le point d’équilibre selon votre matériel.
- 📚 Associez longues fenêtres à récupération et découpage pour plus de précision.
- ⏱️ Suivez les changements de latence à mesure que la fenêtre s’agrandit ; ajustez en conséquence.
- 🧭 Préférez “Arrêter à la limite” pour les prompts fragiles et structurés.
- 🧪 Validez la qualité avec des tâches qui reflètent les charges réelles.
| Cas d’utilisation 🎬 | Contexte suggéré 📏 | Politique de dépassement 🧱 | Notes 🗒️ |
|---|---|---|---|
| Assistant de code | 8k–24k | Arrêter à la limite | Associer à la récupération au niveau fichier 💼 |
| Revue juridique | 32k–64k | Arrêter à la limite | Découper par section ; garder les citations visibles 📖 |
| Transcriptions de podcasts | 16k–48k | Arrêter à la limite | Résumer par segment, puis fusionner 🎙️ |
| Synthèse de recherche | 24k–64k | Arrêter à la limite | RoPE scaling avec validation rigoureuse 🔬 |
| Chat général | 4k–16k | Arrêter à la limite | Archiver les tours anciens, récupérer selon besoin 💬 |
Ces guides rejoignent des perspectives de marché plus larges—voir des analyses telles que innovation dans les systèmes de raisonnement et un sondage des applications IA niche pour chatbot sur la manière dont divers outils poussent ou limitent les flux longs contexte. La méthode tient : ajustez la taille de la fenêtre selon le travail, puis prouvez-le par des tests reflétant la réalité.
Notes du terrain provenant de la communauté : versions, métadonnées et bonnes pratiques
Les retours communautaires ont cristallisé plusieurs vérités sur la modification de la fenêtre de contexte dans LM Studio. Un fil récurrent décrit un scénario “Q4KM affiche un maximum de 16k” qui s’est avéré être un problème de métadonnées plutôt qu’une limite dure. Un autre note que la boîte numérique de l’UI accepte des valeurs au-delà du curseur, même en rouge, et que ces valeurs s’appliquent au chargement. Les utilisateurs confirment aussi que la longueur de contexte dans certaines configurations affecte plus l’affichage que la conversion, ce qui explique pourquoi les modifications semblent inefficaces tandis que la longueur runtime change.
Le comportement des versions mérite attention. Une build 0.3.24 a renforcé la sauvegarde des valeurs au-delà du max, poussant certains à revenir à une build antérieure autorisant les entrées manuelles. Quelle que soit la version, la pratique la plus robuste est de taper la valeur cible, de régler le dépassement sur “Arrêter à la limite” et de valider avec des longues entrées. En cas de doute, fiez-vous aux logs, pas au curseur. Comprendre ce qui est métadonnée versus limite réelle fait gagner des heures.
Le matériel et la planification comptent aussi. De très grandes fenêtres étendent le cache KV et ralentissent les réponses. Pour un travail soutenu, réduisez le contexte ou combinez un contexte modéré avec récupération. Des articles stratégiques—comme le rôle de NVIDIA dans le scaling des infrastructures IA—rappellent que l’optimisation est un exercice de bout en bout. Pour les praticiens, des listes comme codes d’erreur courants offrent un contrepoids pratique lors des dépannages.
Enfin, il est utile de comparer et d’évaluer les hypothèses avec des comparatifs plus larges. Lire comment ChatGPT se mesure à Perplexity ou parcourir les tendances d’accès régionales ancre les attentes d’usage de long contexte au-delà d’un seul outil. Bien que LM Studio offre un contrôle granulaire localement, les habitudes héritées des modèles cloud nécessitent parfois un ajustement pour correspondre au matériel et aux réalités de quantification locaux.
- 📌 Considérez les plafonds UI “16k max” comme suspects ; confirmez avec logs et tests.
- 🧭 Préférez les entrées numériques tapées plutôt que les curseurs en cas de désaccord.
- 🧱 Utilisez “Arrêter à la limite” pour protéger les prompts et agents structurés.
- 🧮 Surveillez VRAM et quantification ; les longues fenêtres peuvent coûter cher.
- 🧪 Validez avec des entrées longues, réalistes et spécifiques à la tâche.
| Insight de la communauté 🗣️ | Ce que ça signifie 💡 | Étape à suivre 🚀 |
|---|---|---|
| Le curseur plafonne tôt | Probablement un décalage UI/métadonnées | Entrez la valeur manuellement, puis testez 📏 |
| La boîte rouge fonctionne quand même | Avertissement de validation, pas blocage | Chargez le modèle et vérifiez les logs 🚦 |
| Config vs. conversion | Certaines entrées sont des métadonnées seulement | Ne pas re-convertir ; ajustez au runtime 🧰 |
| Variabilité des versions | Comportement changé selon les builds | Gardez un installateur stable sous la main 🗃️ |
| Coût du long contexte | Le cache KV croît avec les tokens | Dimensionnez la fenêtre, utilisez la récupération 🧠 |
Pour une vue plus large, des comparatifs comme OpenAI vs. Anthropic et des éditoriaux comme choix stratégiques de talents dans la tech expliquent pourquoi la maîtrise de la configuration est aussi cruciale que le choix du modèle. La leçon durable : vérifiez, testez, documentez les réglages qui font vraiment la différence pour votre charge.
{« @context »: »https://schema.org », »@type »: »FAQPage », »mainEntity »:[{« @type »: »Question », »name »: »Can the context window be increased beyond the slider cap in LM Studio? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Yes. Click the numeric field next to the slider and type the desired token count. Even if the box turns red, LM Studio frequently applies the value at load time. Confirm by checking logs and testing with a long prompt. »}},{« @type »: »Question », »name »: »Which overflow policy is safest for structured prompts? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Stop at limit. It prevents mid-prompt truncation, protecting system prompts, function schemas, and tool formats. This setting is particularly useful for agent-style workflows and memory-heavy sessions. »}},{« @type »: »Question », »name »: »Does RoPE scaling guarantee good long-context performance? », »acceptedAnswer »:{« @type »: »Answer », »text »: »No. RoPE scaling can extend effective context but may reduce coherence at very high lengths. Use modest scaling, validate with real tasks, and combine with retrieval for reliable results. »}},{« @type »: »Question », »name »: »Why do some models show 16k max when the card says 128k? », »acceptedAnswer »:{« @type »: »Answer », »text »: »That mismatch often reflects metadata in the conversion package. Try entering a higher value manually and validate the applied length at runtime; treat the slider as advisory, not authoritative. »}},{« @type »: »Question », »name »: »How to choose the right window size for local text generation? », »acceptedAnswer »:{« @type »: »Answer », »text »: »Use ladder tests: start with the documented max, observe latency and quality, then adjust. Pair moderate windows with retrieval and set overflow to Stop at limit for structured work. »}}]}Can the context window be increased beyond the slider cap in LM Studio?
Yes. Click the numeric field next to the slider and type the desired token count. Even if the box turns red, LM Studio frequently applies the value at load time. Confirm by checking logs and testing with a long prompt.
Which overflow policy is safest for structured prompts?
Stop at limit. It prevents mid-prompt truncation, protecting system prompts, function schemas, and tool formats. This setting is particularly useful for agent-style workflows and memory-heavy sessions.
Does RoPE scaling guarantee good long-context performance?
No. RoPE scaling can extend effective context but may reduce coherence at very high lengths. Use modest scaling, validate with real tasks, and combine with retrieval for reliable results.
Why do some models show 16k max when the card says 128k?
That mismatch often reflects metadata in the conversion package. Try entering a higher value manually and validate the applied length at runtime; treat the slider as advisory, not authoritative.
How to choose the right window size for local text generation?
Use ladder tests: start with the documented max, observe latency and quality, then adjust. Pair moderate windows with retrieval and set overflow to Stop at limit for structured work.



OpenAI vs Microsoft : Principales différences entre ChatGPT et GitHub Copilot en 2025
Séparation architecturale en 2025 : accès direct au modèle vs génération augmentée orchestrée en entreprise La différence la plus conséquente...


Quel sera le meilleur IA pour créer un CV impressionnant en 2025 ?
Quelle sera la meilleure IA pour créer un CV impressionnant en 2025 ? Critères qui distinguent les gagnants de la...


Newsearch en 2025 : à quoi s’attendre de la prochaine génération de moteurs de recherche en ligne
Newsearch en 2025 : l’IA générative transforme les moteurs de recherche en assistants La recherche n’est plus une liste de...


Chya expliqué : avantages, utilisations et effets secondaires en 2025
Chya expliqué en 2025 : bienfaits pour la santé basés sur des preuves, antioxydants et densité nutritionnelle Chya—plus largement connu...


xr mise à jour : les principales actualités et analyses vr pour 2025
Mise à jour XR 2025 : actualités VR d’entreprise, signaux de ROI et percées sectorielles La mise à jour XR...


Comment maîtriser le jeu de clic sur la barre d’espace en 2025
Fondamentaux du Clicker à la Barre d’Espace : CPS, Boucles de Rétroaction et Maîtrise en Début de Partie Les jeux...


i bubble letter : idées créatives et tutoriels pour débutants
Comment dessiner une lettre i en bulles : tutoriel étape par étape pour débutants absolus Commencer par la lettre i...


Présentation d’une version gratuite de ChatGPT conçue spécialement pour les enseignants
Pourquoi une version gratuite de ChatGPT pour les enseignants est importante : espace de travail sécurisé, contrôles administratifs et outils...


Une vue d’ensemble complète du paysage technologique de Palo Alto en 2025
Plateformisation pilotée par l’IA dans le paysage technologique de Palo Alto : opérations de sécurité réinventées Le paysage technologique de...


le AP Physics est-il vraiment si difficile ? ce que les élèves doivent savoir en 2025
La physique AP est-elle vraiment si difficile en 2025 ? Données, taux de réussite et ce qui compte vraiment Demandez...


Service ChatGPT interrompue : les utilisateurs rencontrent des pannes suite à une interruption de Cloudflare | Hindustan Times
Service ChatGPT perturbé : une interruption Cloudflare déclenche des pannes mondiales et des erreurs 500 Des vagues d’instabilité ont déferlé...


Les meilleurs IA d’écriture de 2025 : une comparaison complète et un guide utilisateur
Meilleurs AIs d’écriture en 2025 : Performance en Duel et Cas d’Utilisation Réels Choisir une IA d’écriture en 2025 ressemble...


Comprendre la persistance de l’image : causes, prévention et solutions
Comprendre la persistance d’image vs la rémanence d’écran : définitions, symptômes et dynamique de l’image rémanente sur l’affichage La persistance...


Pouvez-vous changer la fenêtre de contexte dans lmstudio ?
Changer la fenêtre de contexte dans LM Studio : ce que c’est et pourquoi c’est important Le terme fenêtre de...


Comment obtenir l’heure actuelle en swift
Notions essentielles Swift : Comment obtenir l’heure actuelle avec Date, Calendar et DateFormatter Obtenir l’heure actuelle en Swift est simple,...


Comment les détecteurs de vape transforment la sécurité scolaire en 2025
Comment les détecteurs de vape transforment la sécurité scolaire en 2025 : une visibilité basée sur les données sans dérive...


L’IA alimente-t-elle des illusions ? Les inquiétudes grandissent parmi les familles et les experts
L’IA alimente-t-elle des illusions ? Familles et experts suivent un schéma inquiétant Les rapports d’illusions renforcées par l’IA sont passés...


Comment créer et gérer des environnements Python avec conda env create en 2025
Conda env create en 2025 : construire des environnements Python isolés et reproductibles étape par étape Une isolation propre est...


Déverrouillez la puissance du Chat de groupe ChatGPT gratuitement : un guide étape par étape pour commencer
Comment obtenir un accès gratuit et démarrer un chat de groupe ChatGPT : un guide étape par étape pour commencer...


Comment maximiser vos bénéfices de mes évaluations en 2025
Comment maximiser vos bénéfices de mes évaluations en 2025 : Stratégie, ROI et Exécution Les évaluations 2025 ne sont précieuses...
-

 Modèles d’IA21 heures ago
Modèles d’IA21 heures agomodèles vietnamiens en 2025 : nouveaux visages et étoiles montantes à suivre
-
Tech8 heures ago
Une vue d’ensemble complète du paysage technologique de Palo Alto en 2025
-

 Tech3 jours ago
Tech3 jours agoVotre carte ne prend pas en charge ce type d’achat : ce que cela signifie et comment le résoudre
-
Actualités17 heures ago
Déverrouillez la puissance du Chat de groupe ChatGPT gratuitement : un guide étape par étape pour commencer
-

 Modèles d’IA3 jours ago
Modèles d’IA3 jours agoOpenAI vs Tsinghua : Choisir entre ChatGPT et ChatGLM pour vos besoins en IA en 2025
-
Actualités7 heures ago
Présentation d’une version gratuite de ChatGPT conçue spécialement pour les enseignants