
AI-modellen
Kun je het contextvenster in lmstudio wijzigen?
Het wijzigen van het contextvenster in LM Studio: wat het is en waarom het belangrijk is
De term contextvenster beschrijft hoeveel tekst een taalmodel tegelijk kan overwegen. In LM Studio (vaak afgekort tot lmstudio door gebruikers) bepaalt dit venster de maximale invoerlengte en de hoeveelheid eerdere gesprekken of documenten die invloed hebben op de huidige tekstgeneratie. Als de tokenlimiet wordt overschreden, worden belangrijke details afgekapt, wat antwoorden kan verstoren of oppervlakkige redeneringen kan opleveren. Het aanpassen van de venstergrootte is daarom een van de meest ingrijpende AI-instellingen die beschikbaar zijn voor iedereen die modellen lokaal draait.
Waarom zou je het überhaupt veranderen? Teams werken vaak met grote PDF-bestanden, uitgebreide gespreksgeschiedenissen of lange bronbestanden. Een onderzoeker die 30-pagina’s lange memo’s samenstelt, heeft meer ruimte nodig dan een snelle chatbot. Een ontwikkelaar die een codebase met meerdere bestanden analyseert, profiteert ook van een groter buffergebied. LM Studio stelt modelparameters beschikbaar bij het laden (bijv. contextlengte) en tijdens inferentie (bijv. overflow-gedrag), zodat er setups op maat kunnen worden gemaakt voor verschillende werklasten. De juiste grootte kiezen betekent een afweging maken tussen snelheid, kosten (in VRAM en RAM) en nauwkeurigheid van antwoorden.
Neem “Maya,” een data-analist die compliance-rapporten samenstelt. Wanneer het venster te krap is ingesteld, verdwijnen citaties en worden verwijzingen vaag. Na het vergroten van de contextlengte in LM Studio, onthoudt het model meer voetnoten, reageert met precieze verwijzingen en handhaaft consistente terminologie over honderden regels. Het verschil is niet cosmetisch; het verandert wat het model midden in het gesprek kan weten.
Belangrijke redenen waarom gebruikers de limiet verhogen zijn onder meer langere functionerende schemas, complexe systeem-prompten en multi-turn chats met bijgevoegde documenten. De configuratie van LM Studio stelt hen in staat om het gedrag verder af te stemmen dan standaardinstellingen, maar bewustzijn van model-specifieke maxima is essentieel. Sommige modellen worden standaard geleverd met 4k–16k tokens; andere adverteren 128k of meer. De daadwerkelijke prestaties hangen samen met zowel de training van het model als de runtime-benadering (bijv. positionele codering en attentiestrategieën).
- 🔧 Vergroot de venstergrootte om lange instructies te behouden en afkapping te verminderen.
- 🧠 Verbeter multi-document redenering door meer context in het geheugen te houden.
- ⚡ Balans tussen snelheid en kwaliteit; grotere vensters kunnen generaties vertragen.
- 🛡️ Gebruik overflow-beleid om veiligheid te waarborgen bij het bereiken van de tokenlimiet.
- 📈 Houd kwaliteitsafwegingen in de gaten bij het gebruik van uitgebreide contexttechnieken.
De juiste grootte kiezen hangt ook af van de taak. Voor nauwkeurige codehulp, overweeg een gemiddeld contextvenster plus gerichte ophalen. Voor literaire analyse of juridische beoordeling is een groot venster nuttig—als het model het echt goed aankan. In het ecosysteem van 2025 laten vergelijkingen zoals ChatGPT versus Perplexity en OpenAI versus Anthropic zien hoe model-families lang-ctx-redenering verschillend prioriteren. Lokale gebruikers willen dezelfde kracht, maar moeten het verstandig configureren.
| Concept ✨ | Wat het controleert 🧭 | Invloed op resultaten 📊 |
|---|---|---|
| Contextvenster | Max tokens die model kan “zien” | Behouden van instructies en verwijzingen |
| Venstergrootte | Contextlengte bij laden | Latency, geheugengebruik, coherentie |
| Overflow-beleid | Hoe te handelen bij de limiet | Veiligheid, determinisme, of afkappingspatronen |
| Modelparameters | RoPE-scaling, kv-cache, enz. | Effectieve max lengte en stabiliteit |
| AI-instellingen | UI-configuratie in LM Studio | Workflow passend voor verschillende taken |
Conclusie: het veranderen van de contextlengte in LM Studio is niet zomaar een schakelaar—het is een strategische keuze die bepaalt hoeveel het model in één keer kan onthouden en over kan redeneren.

LM Studio-controles: overflow-beleid, schuifregelaars en de “rode doos” truc
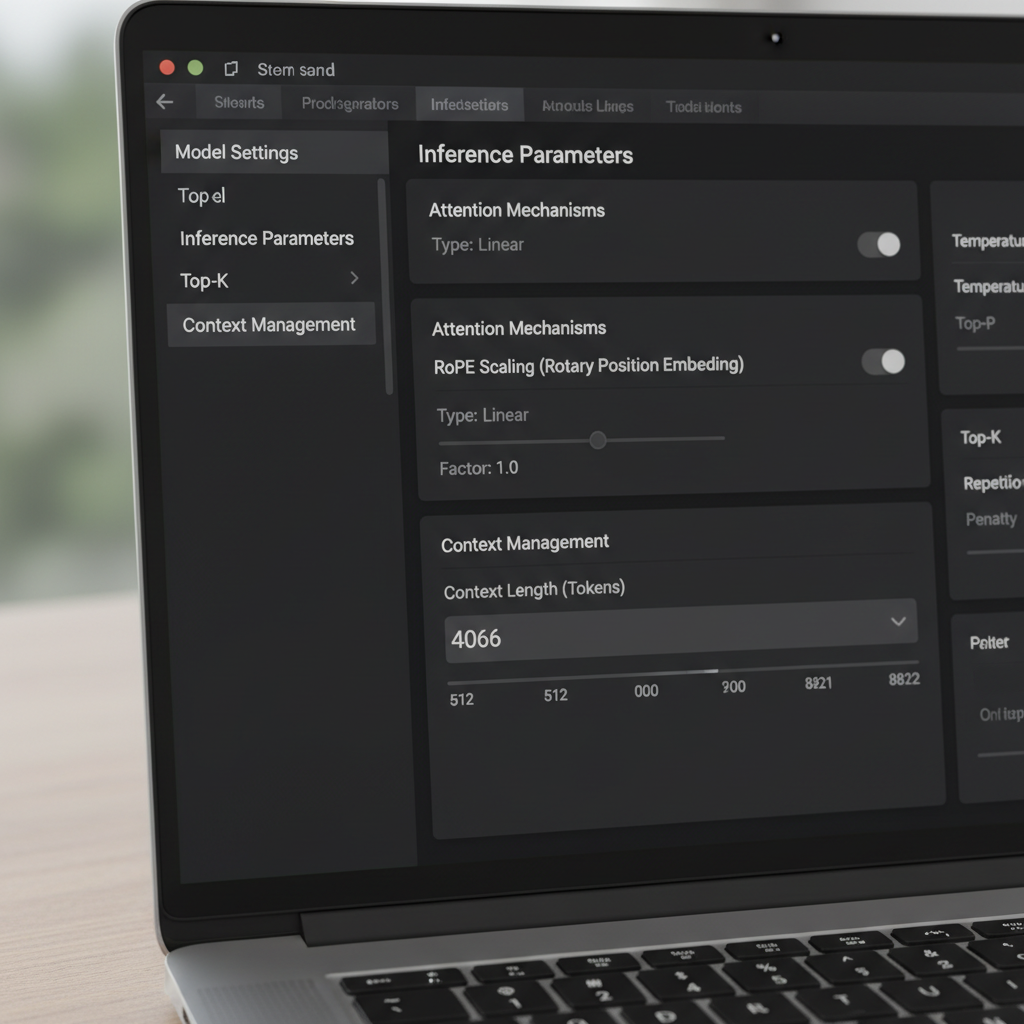
LM Studio biedt meerdere manieren om het contextvenster te wijzigen. In de UI regelen een schuifregelaar en een numeriek veld de geconfigureerde venstergrootte. Een eigenaardigheid die door communitygebruikers wordt gemeld, is een schuifregelaar die bij bepaalde quantisaties stopt bij 16k, ondanks dat de onderliggende modelmetadata meer ondersteunt (bijv. 128k). Als de schuifregelaar niet verder naar rechts gaat, klikken veel gebruikers gewoon in het numerieke vak en typen ze het gewenste aantal tokens. De waarde kan rood kleuren en aangeven dat het niet opslaat—maar het wordt toch toegepast bij runtime. Dit verrassende gedrag stelt gevorderde gebruikers in staat om UI-wrijving te omzeilen zonder aangepaste tools.
Een andere kritische instelling is het Context Overflow-beleid. De standaard “systeem-prompt behouden, midden afkappen” kan sommige geheugensystemen en agents breken. Overschakelen naar Stop bij limiet zorgt ervoor dat het model stopt in plaats van het midden van een gestructureerde prompt te verminken. Gebruikers die geheugenframeworks of tools vergelijkbaar met MemGPT integreren, meldden veel minder problemen na het kiezen voor “Stop bij limiet.” Het is een eenvoudige oplossing die structuur behoudt en stille corruptie van belangrijke tekst voorkomt.
Versieunauances zijn belangrijk. Sommige gebruikers merkten op dat vanaf een bepaalde 0.3.24 build de UI geen contextgroottes boven de geadverteerde limiet meer opslaat, waardoor ze verborgen configuratiebestanden moesten bewerken of tijdelijk een eerdere build moesten gebruiken die handmatige waarden toestond. Het belangrijkste inzicht is dat het wijzigen van het numerieke veld vaak een runtime-parameter bijwerkt, terwijl bepaalde JSON-items metadata voor weergave zijn en geen invloed hebben op modelconversie. Het begrijpen van dit onderscheid voorkomt onnodige re-quantisatie of het jongleren met bestanden.
Voor teams die lokaal LLM’s gaan gebruiken, vermindert een kleine playbook fouten. Controleer eerst de gedocumenteerde maximale context van het model. Pas ten tweede het numerieke veld van LM Studio aan tot dat maximum, ook als de schuifregelaar eerder stopt. Ten derde stel overflow in op “Stop bij limiet” voor gestructureerde prompten. Test ten slotte met een synthetisch lang document om te bevestigen dat content buiten de vorige limiet nu correct wordt herkend en weergegeven.
- 🧩 Als de schuifregelaar stopt bij 16k, typ het aantal dan rechtstreeks in het vak.
- 🛑 Geef de voorkeur aan Stop bij limiet wanneer strikte structuur vereist is.
- 🧪 Valideer met een lange dummy-prompt om te bewijzen dat de wijziging effect heeft.
- 📂 Behandel config.json-limieten als UI-metadata tenzij de documentatie anders zegt.
- 💡 Houd een notitie bij van de LM Studio-versie en changelog voor contextlengtegedrag.
Deze stappen passen goed bij bredere evaluaties. Bijvoorbeeld het lezen van feature-analyses zoals Gemini versus ChatGPT en de 2025 ChatGPT review helpt bij het kaderen van verwachtingen omtrent lang-ctx-prestaties in verschillende ecosystemen. Observeren waar cloudgiganten nadruk leggen op context, helpt ook bij lokale afstemming.
| Actie 🔁 | Waar in LM Studio 🖥️ | Waarom het helpt ✅ |
|---|---|---|
| Typ contextlengte handmatig | Numeriek veld naast schuifregelaar | Omzeilt 16k UI-limiet 🪄 |
| Stel overflow in op “Stop bij limiet” | Inferentie-instellingen | Voorkomt afkapping middenin prompt 🧱 |
| Controleer modelmetadata | Model informatiepaneel | Bevestigt geadverteerde max lengte 📜 |
| Versiecontrole | Over of release notes | Legt veranderingen in opslaan uit 🗂️ |
| Test lange prompt | Chat- of samenstellingsweergave | Empirische validatie nieuwe venstergrootte 🧪 |
Voor een diepere duik in configuratiegewoonten en praktische vergelijkingen zijn videogidsen over lokale LLM-setup behulpzaam.

Bewapend met deze controles kunnen teams LM Studio zelfverzekerd verder dan de standaardinstellingen schuiven en hun prompten beschermen tegen onopgemerkte afkapping.
Voorbij trainingslimieten: RoPE-scaling en effectieve contextlengte
Het uitbreiden van context is niet alleen een kwestie van schuifregelaars. Veel transformer-gebaseerde modellen gebruiken Rotary Positional Embeddings (RoPE), en LM Studio biedt een laadtijdparameter die positionele informatie schaalt. Het verhogen van deze factor maakt het modellen mogelijk om over langerereeksen aandacht te geven door positionele codering gedetailleerder te maken. Het is een krachtige truc—maar niet gratis. Naarmate de factor stijgt, kan lokale coherentie verslechteren en kunnen sommige modellen meer hallucineren bij extreme lengtes. Weten wanneer RoPE-scaling te gebruiken is net zo belangrijk als weten hoe.
De documentatie van LM Studio beschrijft hoe een schaalfactor het effectieve venster aanpast. In de praktijk betekent dit dat een model dat is getraind voor 8k soms kan werken op 16k–32k met acceptabel kwaliteitsverlies, afhankelijk van architectuur en quantisatie. Wanneer gebruikers een GGUF-build zien die in de UI een maximum van 16k toont, maar het upstream model 128k belooft, wijst dat vaak op een metadata-mismatch. In die gevallen verduidelijkt het verhogen van de numerieke waarde en validatie met een lang testgesprek het ware plafond. Community-rapporten geven ook aan dat het bewerken van de waarde—zelfs als de UI deze rood markeert—toch de gewenste lengte bij laadtijd kan toepassen.
Hoe ver kun je gaan? Dat hangt af van model-familie en attentiemechanisme. Benaderingen zoals sliding-window attention en hybride recurrent/transformer-ontwerpen verdragen langere contexten anders dan gewone aandacht. De belangstelling voor alternatieven, inclusief state-space benaderingen, is gegroeid nu teams langerereeksen onderzoeken zonder enorme geheugenvraag. Discussies over state-space modellen en geheugengebruik benadrukken waarom lang-ctx niet zomaar een getal is; het is een stabiliteits- en architectuurvraagstuk.
Het team van Maya gebruikte RoPE-scaling voorzichtig voor kwartaaloverzichten. Bij 24k tokens bleven reacties scherp. Bij 48k nam de latency toe en vergaten samenvattingen soms vroege details, wat duidt op afnemende baten. Ze kozen voor 32k met retrieval-augmentatie, wat kwaliteit behield en grote vertragingen verminderde. De les: grotere vensters moeten retrieval en chunking aanvullen, niet vervangen.
- 🧮 Begin met gematigde schaal (bijv. 1,5–2×) voordat je verder verhoogt.
- 🧭 Combineer lange context met retrieval zodat het model alleen relevante delen ziet.
- 📉 Let op coherentie-daling bij erg hoge token-aantallen.
- 🧰 Houd quantisatie- en VRAM-beperkingen in de gaten bij het rekken van het venster.
- 🔍 Valideer met domeinspecifieke lange tests in plaats van generieke prompts.
Vergelijkende artikelen zoals ChatGPT vs. Gemini in 2025 en overzichten zoals mijlpalen in de evolutie van ChatGPT bieden bredere context over hoe leveranciers de lange-ctx-race frame. Ook al wijkt het lokale model af, de afwegingen klinken door in het veld.
| RoPE scaling keuze 🧯 | Voordelen 🌟 | Nadelen ⚠️ | Gebruik wanneer 🎯 |
|---|---|---|---|
| 1.0× (standaard) | Stabiel en voorspelbaar gedrag | Beperkte max lengte | Kwaliteitskritische taken ✅ |
| 1.5–2.0× | Merkbaar langere context | Lichte coherentie-impact | Rapporten, lichte code-analyse 📄 |
| 2.5–4.0× | Grote multi-document sessies | Latency, drift-risico’s | Verkennend onderzoek 🔬 |
| 4.0×+ | Extreme sequenties | Waarschijnlijk instabiele output | Benchmarking en experimenten 🧪 |
De pragmatische conclusie: RoPE-scaling kan het bereik vergroten, maar retrieval en prompt-engineering leveren vaak stabielere winst per token.
Wanneer de venstergrootte niet meewerkt: problemen met lange context in LM Studio oplossen
Af en toe weigert LM Studio een wijziging. Gebruikers melden een “max 16k” schuifregelaar voor bepaalde quantisaties, hoewel het basismodel veel meer belooft. Anderen zagen dat een nieuwere build hogere waarden niet opslaat, waardoor ze tijdelijk een eerdere versie gebruikten of waarden direct typeten ondanks waarschuwingskleuren. Deze problemen zijn frustrerend maar oplosbaar met een systematische checklist.
Bevestig eerst de geadverteerde maximale context van het model. Sommige community-kaarten vermelden ten onrechte 16k door een verpakkingfout, terwijl het model 128k ondersteunt. Probeer ten tweede het getal in het tekstveld te typen; als het rood wordt maar toch laadt, heb je de schuifregelaarlimiet omzeild. Ten derde stel je overflow in op “Stop bij limiet” om het beschadigen van een zorgvuldig samengestelde systeem-prompt te voorkomen. Ten vierde valideer je met een lange dummy-set paragrafen en vraag je het model om vroege, midden- en late secties samen te vatten zodat bewezen wordt dat het volledige bereik zichtbaar is.
Als LM Studio nog steeds weigert, overweeg dan of de quantisatie-variant een harde limiet in de metadata heeft. Sommige GGUF-conversies embedden een default context die verschilt van het originele model. Omdat de limiet zich vaak gedraagt als weergavemetadata in plaats van een afdwingbare grens, is de tekstveld-aanpak vaak toereikend; houd echter logs bij het laden in de gaten om te bevestigen. Controleer ook of er voldoende VRAM is. Zeer grote vensters vergroten de key-value-cache, wat leidt tot vertragingen of out-of-memory-fouten. Als crashes aanhouden, verlaag dan de context, gebruik quantisatie met lagere precisie of splits de taak in stukken.
Buiten LM Studio is het verstandig om te controleren hoe toonaangevende modellen omgaan met lange prompten in de praktijk. Analyses zoals ChatGPT vs. Claude en diepgaande stukken zoals hoe DeepSeek betaalbare training mogelijk maakt bieden inzicht. Lange context is alleen zinvol als het model het getrouw gebruikt; anders kan retrieval of betere promptstructuur beter scoren dan alleen een groter venster.
- 🧰 Als de schuifregelaar stopt bij 16k, probeer het nummer toch in het numerieke veld.
- 🧯 Schakel overflow in op “Stop bij limiet” voor gestructureerde taken.
- 🧠 Valideer begrip vroeg/mid/laat met een synthetische lange prompt.
- 🖥️ Houd VRAM in de gaten; hoge context vermenigvuldigt de KV-cache-geheugenvraag.
- 📜 Controleer logs bij het laden voor de toegepaste contextlengte.
| Symptoom 🐞 | Waarschijnlijke oorzaak 🔎 | Oplossing 🛠️ |
|---|---|---|
| Schuifregelaar stopt bij 16k | UI- of metadata-eigenaardigheid | Typ lengte in het numerieke veld ➕ |
| Rode waarschuwing bij opslaan | Validatiepoort, geen harde stop | Laad om te bevestigen dat het toch wordt toegepast 🚦 |
| OOM of vertraging | KV-cache explosie | Verlaag context of gebruik lichtere quantisatie 🧮 |
| Verloren structuur | Afkapping middenin | Stel overflow in op “Stop bij limiet” 🧱 |
| Mismatch met documenten | Conversiemetadata | Controleer logs en voer lange-prompt-test uit 🔍 |
Voor visuele leerlingen zijn walkthroughs over lange-context tests en benchmarking onmisbaar.

Met een gedisciplineerde checklist wordt een hardnekkige contextlimiet een tijdelijke hinderpaal in plaats van een blokkade.
De juiste grootte kiezen voor lokale tekstgeneratie: playbooks, testen en strategie
Er is geen universele beste venstergrootte. De juiste keuze hangt af van de taak, modelfamilie en hardware. Een code-assistent profiteert van een gemiddeld venster plus ophalen van de meest relevante bestanden. Een juridisch onderzoeker geeft mogelijk prioriteit aan een groter venster, maar vertrouwt nog steeds op chunking om het model niet te overspoelen met irrelevante pagina’s. Een podcastmaker die afleveringssamenvattingen maakt van lange transcripties kan een royale context combineren met slimme sectie-indeling om coherentie te behouden.
Een praktische aanpak is een “laddert-test”: begin met het gedocumenteerde maximum, en verlaag of verhoog terwijl je latency en nauwkeurigheid bewaakt. Gebruik lange, domeinspecifieke invoer en verifieer dat vroege en late secties worden genoemd. Als het model bij grotere maten lijkt te vergeten wat in het begin stond, verlaag dan het venster of pas RoPE-scaling voorzichtig toe. Waar ultralange prompts cruciaal zijn, vul aan met retrieval zodat het model een geselecteerd deel ziet in plaats van het hele archief.
Het helpt ook om verwachtingen te benchmarken door vergelijkende functies te lezen zoals ChatGPT vs. GitHub Copilot en bredere industrienotities zoals de “bend time” rechtszaakverslaggeving. Deze referenties bieden context over hoe verschillende ecosystemen omgaan met lange inputs en ontwikkelaar-workflows. Tegelijkertijd benadrukken handleidingen over operationele onderwerpen—zoals het beheersen van API-sleutels—hoe configuratiedetails leiden tot echte productiviteitswinst.
- 🪜 Gebruik laddertests om de beste balans voor je hardware te vinden.
- 📚 Combineer lange vensters met retrieval en chunking voor precisie.
- ⏱️ Volg latency-veranderingen bij groeiend venster; pas aan waar nodig.
- 🧭 Geef de voorkeur aan “Stop bij limiet” voor kwetsbare, gestructureerde prompts.
- 🧪 Valideer kwaliteit met taken die echte werklasten nabootsen.
| Gebruikssituatie 🎬 | Voorgestelde context 📏 | Overflow-beleid 🧱 | Notities 🗒️ |
|---|---|---|---|
| Code-assistent | 8k–24k | Stop bij limiet | Combineren met bestand-niveau ophalen 💼 |
| Juridische beoordeling | 32k–64k | Stop bij limiet | Chunk per sectie; houd citaties zichtbaar 📖 |
| Podcasttranscripties | 16k–48k | Stop bij limiet | Samenvatten per segment, daarna samenvoegen 🎙️ |
| Onderzoeksynthese | 24k–64k | Stop bij limiet | RoPE-scaling met zorgvuldige validatie 🔬 |
| Algemene chat | 4k–16k | Stop bij limiet | Archiveer oudere beurten, haal op indien nodig 💬 |
Die playbooks sluiten aan bij praktische marktinzichten—zie bijvoorbeeld analyses zoals innovatie in redeneersystemen en een overzicht van niche AI chatbot-apps over hoe verschillende tools lange-ctx-workflows stimuleren of beperken. De methode blijft: stem venstergrootte af op de taak, en bewijs het met tests die de praktijk weerspiegelen.
Praktijkervaringen uit de community: versies, metadata en veilige werkwijzen
Communityfeedback heeft meerdere waarheden rond het wijzigen van het contextvenster in LM Studio geformuleerd. Een terugkerende situatie beschrijft dat “Q4KM een maximum van 16k toont” dat bleek een metadata-kwestie, geen harde limiet. Een ander punt is dat het numerieke veld in de UI waarden accepteert boven de schuifregelaar, zelfs als rood gemarkeerd, en dat deze waarden bij het laden van het model worden toegepast. Gebruikers bevestigen ook dat de contextlengte in sommige configuraties meer voor weergave is dan voor conversie, wat verklaart waarom aanpassingen geen effect lijken te hebben terwijl de runtime-lengte toch verandert.
Het versiegedrag verdient aandacht. Een bepaalde 0.3.24-build heeft het opslaan van waarden boven het maximum strenger gemaakt, waardoor sommige gebruikers terugkeerden naar een eerdere build die handmatige invoer toestond. Ongeacht de versie is de stevigste praktijk het typen van de doelwaarde, overflow instellen op “Stop bij limiet” en valideren met lange input. Vertrouw bij twijfel op logs, niet op de schuifregelaar. Duidelijkheid over wat metadata is versus een strikte limiet bespaart uren werk.
Hardware en planning zijn ook belangrijk. Zeer grote vensters vergroten de KV-cache en vertragen reacties. Voor langdurig werk kun je beter de context verlagen of matige context combineren met retrieval. Strategische artikelen—zoals de rol van NVIDIA in het opschalen van AI-infrastructuur—herinneren eraan dat performance tuning een end-to-end oefening is. Voor hands-on gebruikers bieden lijsten zoals veelvoorkomende foutcodes een praktische check bij probleemoplossing.
Tot slot helpt het om aannames te benchmarken aan de hand van bredere vergelijkingen. Het lezen van hoe ChatGPT zich verhoudt tot Perplexity of het bekijken van regionale toegangsstatistieken verankert de verwachtingen over lang-ctx-gebruik buiten één enkele tool. Terwijl LM Studio fijne lokale controle geeft, vereisen gewoonten uit cloudmodellen soms aanpassingen voor lokale hardware en quantisatierealiteit.
- 📌 Behandel “16k max” UI-limieten als verdachte gevallen; bevestig met logs en tests.
- 🧭 Geef de voorkeur aan typen in getallen boven schuifregelaars bij discrepantie.
- 🧱 Gebruik “Stop bij limiet” om gestructureerde prompten en agents te beschermen.
- 🧮 Houd VRAM en quantisatie in de gaten; lange vensters kunnen duur zijn.
- 🧪 Valideer met taak-specifieke, lange en realistische inputs.
| Community-inzicht 🗣️ | Wat het betekent 💡 | Uitvoerbare stap 🚀 |
|---|---|---|
| Schuifregelaar stopt vroeg | Waarschijnlijke UI-/metadata-mismatch | Waarde handmatig invoeren en testen 📏 |
| Rode doos werkt toch | Validatiewaarschuwing, geen afdwinging | Model laden en logs controleren 🚦 |
| Config vs. conversie | Sommige items zijn alleen metadata | Niet opnieuw converteren; runtime aanpassen 🧰 |
| Versieverschillen | Gedrag veranderde over builds | Houd een stabiele installer bij de hand 🗃️ |
| Kosten lange context | KV-cache groeit met tokens | Venster juist afstemmen, retrieval gebruiken 🧠 |
Voor bredere context bieden vergelijkingen zoals OpenAI vs. Anthropic en redactionele overzichten zoals strategische talentkeuzes in technologie inzicht waarom vloeiendheid in configureren net zo belangrijk is als modelkeuze. De blijvende boodschap: verifieer, test en documenteer de instellingen die echt impact hebben op je werklast.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Kan het contextvenster verhoogd worden voorbij de schuifregelaarlimiet in LM Studio?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Ja. Klik op het numerieke veld naast de schuifregelaar en typ het gewenste aantal tokens. Zelfs als het vak rood wordt, past LM Studio de waarde vaak toe bij het laden. Bevestig dit door logs te controleren en te testen met een lange prompt.”}},{“@type”:”Question”,”name”:”Welk overflow-beleid is het veiligst voor gestructureerde prompten?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Stop bij limiet. Het voorkomt dat prompts middenin worden afgekapt, waardoor systeem-prompten, functionschema’s en toolformaten worden beschermd. Deze instelling is vooral nuttig voor agent-achtige workflows en geheugenintensieve sessies.”}},{“@type”:”Question”,”name”:”Garandeert RoPE-scaling goede lange-context prestaties?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Nee. RoPE-scaling kan het effectieve bereik vergroten, maar kan coherentie verminderen bij zeer hoge lengtes. Gebruik gematigde scaling, valideer met echte taken en combineer met retrieval voor betrouwbare resultaten.”}},{“@type”:”Question”,”name”:”Waarom tonen sommige modellen een max van 16k terwijl de kaart 128k zegt?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Die mismatch weerspiegelt vaak metadata in het conversiepakket. Probeer een hogere waarde handmatig in te voeren en valideer de toegepaste lengte tijdens runtime; beschouw de schuifregelaar als advies, niet als autoriteit.”}},{“@type”:”Question”,”name”:”Hoe kies je de juiste venstergrootte voor lokale tekstgeneratie?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Gebruik laddertests: begin met het gedocumenteerde maximum, observeer latency en kwaliteit, en pas aan. Combineer matige vensters met retrieval en stel overflow in op Stop bij limiet voor gestructureerd werk.”}}]}Kan het contextvenster verhoogd worden voorbij de schuifregelaarlimiet in LM Studio?
Ja. Klik op het numerieke veld naast de schuifregelaar en typ het gewenste aantal tokens. Zelfs als het vak rood wordt, past LM Studio de waarde vaak toe bij het laden. Bevestig dit door logs te controleren en te testen met een lange prompt.
Welk overflow-beleid is het veiligst voor gestructureerde prompten?
Stop bij limiet. Het voorkomt dat prompts middenin worden afgekapt, waardoor systeem-prompten, functionschema’s en toolformaten worden beschermd. Deze instelling is vooral nuttig voor agent-achtige workflows en geheugenintensieve sessies.
Garandeert RoPE-scaling goede lange-context prestaties?
Nee. RoPE-scaling kan het effectieve bereik vergroten, maar kan coherentie verminderen bij zeer hoge lengtes. Gebruik gematigde scaling, valideer met echte taken en combineer met retrieval voor betrouwbare resultaten.
Waarom tonen sommige modellen een max van 16k terwijl de kaart 128k zegt?
Die mismatch weerspiegelt vaak metadata in het conversiepakket. Probeer een hogere waarde handmatig in te voeren en valideer de toegepaste lengte tijdens runtime; beschouw de schuifregelaar als advies, niet als autoriteit.
Hoe kies je de juiste venstergrootte voor lokale tekstgeneratie?
Gebruik laddertests: begin met het gedocumenteerde maximum, observeer latency en kwaliteit, en pas aan. Combineer matige vensters met retrieval en stel overflow in op Stop bij limiet voor gestructureerd werk.



Wat wordt de beste AI voor het maken van een indrukwekkend cv in 2025?
Wat Wordt de Top AI voor het Maken van een Indrukwekkend Cv in 2025? Criteria die Winnaars Onderscheiden van de...


Newsearch in 2025: wat te verwachten van de volgende generatie online zoekmachines
Newsearch in 2025: Generatieve AI verandert online zoekmachines in assistenten Zoeken is niet langer een lijst met blauwe links. Het...


Chya verklaard: voordelen, toepassingen en bijwerkingen in 2025
Chya uitgelegd in 2025: op bewijs gebaseerde gezondheidsvoordelen, antioxidanten en voedingsdichtheid Chya—bekender als chaya (Cnidoscolus aconitifolius) of “boomspinazie”—is een voedingsrijke...


xr update: de belangrijkste vr-nieuws en inzichten voor 2025
XR-update 2025: Enterprise VR-nieuws, ROI-signalen en sector-doorbraken De XR-update binnen ondernemingen toont een beslissende verschuiving van pilots naar productie. Organisaties...


Hoe je het space bar clicker spel in 2025 kunt beheersen
Space Bar Clicker Fundamenten: CPS, Feedbackloops en Vroege-game Meesterschap Space bar clicker games veranderen een enkele toetsaanslag in een eindeloos...


i bubble letter: creatieve ideeën en tutorials voor beginners
Hoe teken je een i Bubble Letter: Stap-voor-stap Tutorial voor Absolute Beginners Beginnen met de kleine i bubble letter is...


Introductie van een gratis ChatGPT-versie speciaal ontworpen voor docenten
Waarom een Gratis ChatGPT voor Onderwijzers Belangrijk Is: Beveiligde Werkruimte, Beheerscontroles en Gerichte Onderwijshulpmiddelen Gratis ChatGPT op maat gemaakt voor...


Een uitgebreide overzicht van het technologielandschap in Palo Alto tegen 2025
AI-gedreven Platformisering in het Technologielandschap van Palo Alto: Security Operations Hernieuwd Het technologielandschap van Palo Alto is resoluut gekanteld naar...


is ap physics echt zo moeilijk? wat studenten moeten weten in 2025
Is AP Physics Echt Zo Moeilijk in 2025? Data, Slaagpercentages en Wat Echt Belangrijk Is Vraag een groep leerlingen in...


ChatGPT-service onderbroken: gebruikers ervaren storingen tijdens Cloudflare-onderbreking | Hindustan Times
ChatGPT-dienst verstoord: Cloudflare-onderbreking veroorzaakt wereldwijde storingen en 500-fouten Golven van instabiliteit rolden over het web toen een Cloudflare-onderbreking kern-edge-diensten in...


Top Writing AIs van 2025: Een Uitgebreide Vergelijking en Gebruikersgids
Top Schrijfassistent-AI’s van 2025: Vergelijkende Prestaties en Praktische Toepassingen Het kiezen van een schrijfassistent AI in 2025 voelt als het...


Begrip van beeldpersistentie: oorzaken, preventie en oplossingen
Begrip van beeldpersistentie vs scherm branden: definities, symptomen en dynamiek van beeldnasleep op displays Beeldpersistentie beschrijft het zwakke beeldnasleep dat...


Kun je het contextvenster in lmstudio wijzigen?
Het wijzigen van het contextvenster in LM Studio: wat het is en waarom het belangrijk is De term contextvenster beschrijft...


Hoe krijg je de huidige tijd in swift
Swift Essentials: Hoe je de huidige tijd krijgt met Date, Calendar en DateFormatter Het verkrijgen van de huidige tijd in...


Hoe vape detectors de veiligheid op scholen transformeren in 2025
Hoe vape-detectoren de veiligheid op scholen in 2025 transformeren: datagedreven zichtbaarheid zonder surveillance-overlast Op campussen groot en klein zijn vape-detectoren...


Voedt AI waanideeën? Groeiend bezorgdheid bij families en experts
Voedt AI Waanideeën? Families en Experts Volgen een Verontrustend Patroon Meldingen van door AI versterkte Waanideeën zijn verschoven van marginale...


Hoe je Python-omgevingen maakt en beheert met conda env create in 2025
Conda env create in 2025: stap voor stap geïsoleerde, reproduceerbare Python-omgevingen bouwen Schone isolatie is de basis van betrouwbare Python-projecten....


Ontgrendel de Kracht van ChatGPT Groepschat Gratis: Een Stapsgewijze Handleiding om te Beginnen
Hoe gratis toegang te krijgen en een ChatGPT-groepschat te starten: een stapsgewijze handleiding voor aan de slag ChatGPT Groepschat is...


Hoe u uw voordelen uit mijn evaluaties in 2025 kunt maximaliseren
Hoe u uw voordelen uit mijn evaluaties in 2025 maximaliseert: Strategie, ROI en Uitvoering Evaluaties 2025 zijn alleen zo waardevol...

Plan je volgende uitje hier: TripAdvisor lanceert geïntegreerde app binnen ChatGPT
TripAdvisor’s Geïntegreerde App in ChatGPT: De Game-Changer voor Reisplanning en Boekingen De komst van de TripAdvisor Geïntegreerde App binnen ChatGPT...
-
Uncategorized17 hours ago
Ontgrendel de Kracht van ChatGPT Groepschat Gratis: Een Stapsgewijze Handleiding om te Beginnen
-

 AI-modellen1 day ago
AI-modellen1 day agoDe Beste ChatGPT-bibliotheken Verkennen om Je Projecten in 2025 te Verbeteren
-

 AI-modellen20 hours ago
AI-modellen20 hours agovietnamese modellen in 2025: nieuwe gezichten en opkomende sterren om in de gaten te houden
-

 Tools4 days ago
Tools4 days agoHoe een ap spanish score calculator te gebruiken voor nauwkeurige resultaten in 2025
-

 Uncategorized3 days ago
Uncategorized3 days agoVerkenning van proefversies nyt: wat te verwachten in 2025
-

 Uncategorized2 days ago
Uncategorized2 days agoChatGPT Gegevenslek: Gebruikersnamen en e-mails gelekt; Bedrijf dringt aan op voorzichtigheid en herinnert gebruikers eraan waakzaam te blijven