
Modelos de IA
Você pode alterar a janela de contexto no lmstudio?
Alterando a janela de contexto no LM Studio: o que é e por que importa
O termo janela de contexto descreve quanto texto um modelo de linguagem pode considerar de uma vez. No LM Studio (frequentemente abreviado para lmstudio por praticantes), essa janela determina o comprimento máximo de entrada e a quantidade de conversa passada ou documentos que influenciam a geração de texto atual. Se o limite de tokens for excedido, detalhes importantes são truncados, o que pode prejudicar respostas ou produzir raciocínios superficiais. Ajustar o tamanho da janela é, portanto, uma das configurações de IA mais importantes disponíveis para quem roda modelos localmente.
Por que alterá-la? Equipes frequentemente lidam com PDFs grandes, históricos extensos de chat ou arquivos de origem longos. Um pesquisador compilando memorandos de 30 páginas precisa de mais espaço do que um chatbot rápido. Um desenvolvedor analisando uma base de código com múltiplos arquivos também se beneficia de um buffer maior. O LM Studio expõe parâmetros do modelo no momento do carregamento (por exemplo, comprimento do contexto) e no tempo de inferência (por exemplo, comportamento de excesso), permitindo configurações personalizadas para diferentes cargas de trabalho. Escolher o tamanho certo significa equilibrar velocidade, custo (em VRAM e RAM) e fidelidade das respostas.
Considere “Maya”, uma analista de dados que organiza relatórios de conformidade. Quando a janela está muito pequena, Maya vê citações desaparecerem e referências ficarem vagas. Após aumentar o comprimento do contexto no LM Studio, o modelo retém mais notas de rodapé, responde com apontamentos precisos e mantém terminologia consistente em centenas de linhas. A diferença não é apenas cosmética; ela altera o que o modelo pode saber durante a conversa.
Principais motivos que levam usuários a aumentar o limite incluem também esquemas mais longos de chamadas de funções, prompts de sistema complexos e chats multi-turnos com documentos anexados. A configuração do LM Studio permite ajustar o comportamento além dos padrões, mas é vital conhecer os máximos específicos de cada modelo. Alguns modelos vêm com 4k–16k tokens por padrão; outros anunciam 128k ou mais. O desempenho real depende tanto do treinamento do modelo quanto da abordagem em tempo de execução (por exemplo, codificação posicional e estratégias de atenção).
- 🔧 Aumente o tamanho da janela para preservar instruções longas e reduzir truncamentos.
- 🧠 Melhore o raciocínio multi-documentos mantendo mais contexto na memória.
- ⚡ Equilibre velocidade versus qualidade; janelas maiores podem desacelerar a geração.
- 🛡️ Use políticas de overflow para controlar a segurança ao atingir o limite de tokens.
- 📈 Monitore os trade-offs de qualidade ao usar técnicas de contexto estendido.
Escolher o tamanho certo também depende da tarefa. Para assistência de codificação de alta precisão, considere um contexto médio mais recuperação direcionada. Para análise literária ou revisão legal, uma janela grande é útil—se o modelo a realmente suporta bem. No ecossistema de 2025, comparações como ChatGPT versus Perplexity e OpenAI versus Anthropic destacam como famílias de modelos priorizam raciocínio de longo contexto de formas diferentes. Executores locais querem o mesmo poder, mas devem configurá-lo com sabedoria.
| Conceito ✨ | O que controla 🧭 | Impacto nos resultados 📊 |
|---|---|---|
| Janela de contexto | Máximo de tokens que o modelo pode “ver” | Retenção de instruções e referências |
| Tamanho da janela | Comprimento do contexto no carregamento | Latência, uso de memória, coerência |
| Política de overflow | Como agir no limite | Segurança, determinismo ou padrões de truncamento |
| Parâmetros do modelo | Escala RoPE, cache kv, etc. | Comprimento máximo efetivo e estabilidade |
| Configurações de IA | Configuração da interface no LM Studio | Fluxo de trabalho para tarefas variadas |
Resumo: alterar o comprimento do contexto no LM Studio não é apenas um botão de liga/desliga—é uma escolha estratégica que determina quanto o modelo pode lembrar e raciocinar em uma única passagem.

Controles do LM Studio: política de overflow, sliders e o truque da “caixa vermelha”
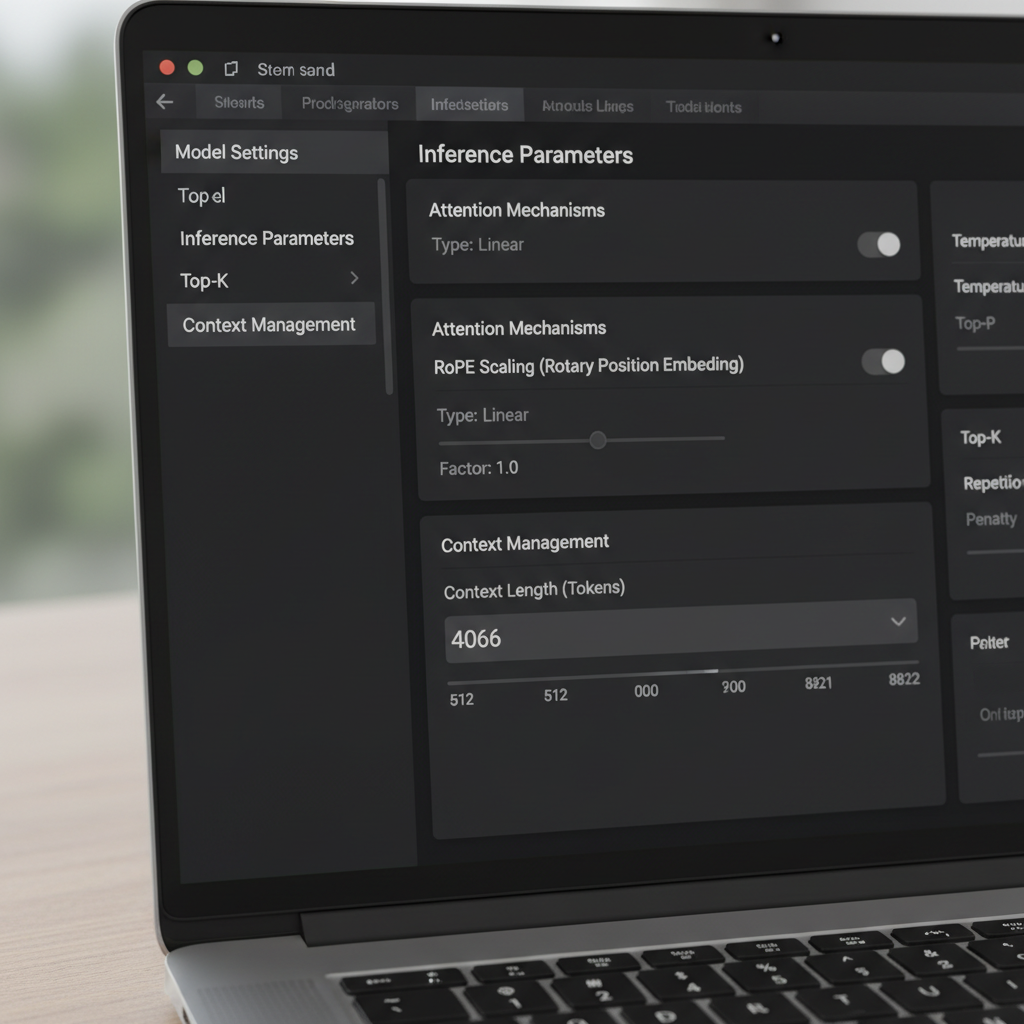
O LM Studio oferece múltiplas formas de alterar a janela de contexto. Na interface, um slider e um campo numérico governam o tamanho da janela configurado. Uma peculiaridade relatada por usuários da comunidade é um slider limitado a 16k para certas quantizações, embora os metadados do modelo subjacente suportem mais (por exemplo, 128k). Quando o slider recusa ir mais à direita, muitos usuários simplesmente clicam na caixa numérica e digitam a contagem de tokens desejada. O valor pode ficar vermelho e indicar que não salvará—mas ainda assim é aplicado no tempo de execução. Esse comportamento surpreendente permite que usuários avançados contornem o atrito da UI sem ferramentas personalizadas.
Outra configuração crítica é a Política de Overflow do Contexto. O padrão “manter prompt do sistema, truncar meio” pode quebrar certos gerenciadores de memória e agentes. Mudar para Parar no limite garante que o modelo pare em vez de mutilar o meio de um prompt estruturado. Usuários que integram frameworks de memória ou ferramentas similares ao MemGPT reportaram muito menos anomalias após escolher “Parar no limite”. É uma correção simples que preserva a estrutura e evita a corrupção silenciosa de texto importante.
As nuances da versão importam. Alguns usuários notaram que, a partir de uma certa build 0.3.24, a UI não salva mais tamanhos de contexto acima do máximo anunciado, levando-os a editar arquivos de configuração ocultos ou temporariamente usar uma build anterior que permitia valores manuais. A percepção-chave é que alterar o campo numérico frequentemente atualiza um parâmetro em tempo de execução, enquanto certas entradas JSON são metadados para exibição e não afetam a conversão do modelo. Compreender essa distinção evita re-quantizações ou manuseio desnecessário de arquivos.
Para equipes que estão começando com LLMs locais, um pequeno manual reduz erros. Primeiro, verifique o máximo documentado do modelo. Segundo, ajuste o campo numérico do LM Studio para esse máximo, mesmo que o slider pare cedo. Terceiro, defina o overflow para “Parar no limite” para prompts estruturados. Finalmente, teste com um documento sintético longo para confirmar que conteúdo além do teto anterior agora é reconhecido e referenciado corretamente.
- 🧩 Se o slider limitar em 16k, digite o número diretamente na caixa.
- 🛑 Prefira Parar no limite quando precisar de estrutura rigorosa.
- 🧪 Valide com um prompt dummy longo para provar que a mudança surtiu efeito.
- 📂 Considere limites no config.json como metadados da UI, salvo indicação contrária nas docs.
- 💡 Anote a versão do LM Studio e o changelog para comportamento do comprimento do contexto.
Esses passos combinam bem com avaliações mais amplas. Por exemplo, ler comparativos como Gemini versus ChatGPT e a análise do ChatGPT 2025 ajuda a moldar expectativas para desempenho em longo contexto entre ecossistemas. Observar onde os gigantes da nuvem enfatizam contexto também orienta ajustes locais.
| Ação 🔁 | Onde no LM Studio 🖥️ | Por que ajuda ✅ |
|---|---|---|
| Digite o comprimento do contexto manualmente | Campo numérico ao lado do slider | Contorna o limite de UI de 16k 🪄 |
| Defina overflow para “Parar no limite” | Configurações de inferência | Evita truncamento no meio do prompt 🧱 |
| Cheque metadados do modelo | Painel de informações do modelo | Confirma o máximo anunciado 📜 |
| Verifique a versão | Sobre ou notas da versão | Explica mudanças no comportamento de salvamento 🗂️ |
| Teste com prompt longo | Vista de chat ou composição | Validação empírica do novo tamanho da janela 🧪 |
Para um mergulho mais profundo em hábitos de configuração e comparações práticas, vídeos tutoriais sobre setup local de LLM são úteis.
Munidos desses controles, as equipes podem avançar com confiança além dos padrões do LM Studio e proteger seus prompts contra truncamento furtivo.
Ultrapassando limites de treinamento: escala RoPE e comprimento efetivo do contexto
Estender o contexto não é apenas uma questão de sliders. Muitos modelos baseados em transformadores dependem de Rotary Positional Embeddings (RoPE), e o LM Studio expõe um parâmetro de carga que escala a informação posicional. Aumentar esse fator permite que modelos atendam sequências mais longas ao tornar a codificação posicional mais granular. É um truque poderoso—mas não gratuito. À medida que o fator cresce, a coerência local pode degradar e alguns modelos alucinam mais em comprimentos extremos. Saber quando usar a escala RoPE é tão importante quanto saber como usar.
A documentação do LM Studio descreve como um fator de escala ajusta a janela efetiva. Na prática, isso significa que um modelo treinado para 8k pode às vezes operar em 16k–32k com perda de qualidade tolerável, dependendo da arquitetura e quantização. Quando usuários relatam uma build GGUF mostrando máximo de 16k na UI, mas o modelo upstream promete 128k, isso frequentemente indica um desalinhamento de metadados. Nesses casos, aumentar o valor numérico e validar com um teste longo esclarece o teto verdadeiro. Relatos da comunidade indicam também que editar o valor—mesmo que destaque em vermelho na UI—pode ainda aplicar o comprimento desejado na carga.
Até onde se pode chegar? Isso depende da família do modelo e do mecanismo de atenção. Abordagens como atenção por janela móvel e designs híbridos recorrentes/transformadores toleram contextos longos de forma diferente da atenção pura. O interesse por alternativas, incluindo abordagens de espaço de estado, cresceu conforme equipes exploram sequências longas sem aumento exorbitante de memória. Discussões sobre modelos de espaço de estado e uso de memória destacam porque contexto longo não é apenas um número; é questão de estabilidade e arquitetura.
A equipe de Maya usou a escala RoPE com moderação para resumos trimestrais. Em 24k tokens, as respostas permaneceram nítidas. Em 48k, a latência aumentou e os resumos às vezes esqueceram detalhes iniciais, sugerindo retornos decrescentes. Eles optaram por 32k com aumento por recuperação, que preservou qualidade evitando lentidões massivas. A lição: janelas maiores devem complementar recuperação e fragmentação, não substituí-las.
- 🧮 Comece com escala modesta (por exemplo, 1.5–2×) antes de elevar.
- 🧭 Combine contexto longo com recuperação para que o modelo veja apenas fatias relevantes.
- 📉 Observe quedas de coerência em contagens muito altas de tokens.
- 🧰 Mantenha em mente limites de quantização e VRAM ao estender a janela.
- 🔍 Valide com testes longos específicos do domínio ao invés de prompts genéricos.
Textos comparativos como ChatGPT vs. Gemini em 2025 e visões gerais como marcos na evolução do ChatGPT oferecem contexto amplo sobre como fornecedores enquadram a corrida do longo contexto. Mesmo que o modelo local seja diferente, os trade-offs ecoam no campo.
| Escolha da escala RoPE 🧯 | Prós 🌟 | Contras ⚠️ | Use quando 🎯 |
|---|---|---|---|
| 1.0× (padrão) | Comportamento estável e previsível | Comprimento máximo limitado | Tarefas críticas de qualidade ✅ |
| 1.5–2.0× | Contexto visivelmente mais longo | Queda leve na coerência | Relatórios, análise leve de código 📄 |
| 2.5–4.0× | Sessões grandes multi-doc | Riscos de latência e deriva | Pesquisa exploratória 🔬 |
| 4.0×+ | Sequências extremas | Saídas instáveis prováveis | Benchmark e experimentos 🧪 |
O insight pragmático: a escala RoPE pode ampliar alcance, mas recuperação e engenharia de prompts frequentemente entregam ganhos mais estáveis por token.
Quando o tamanho da janela não muda: solucionando problemas de contexto longo no LM Studio
Ocasionalmente, o LM Studio resiste a uma alteração. Usuários relataram um slider “máximo 16k” para certas quantizações, embora o modelo base anuncie muito mais. Outros viram uma build mais nova impedir salvar valores maiores, forçando uso temporário de versão anterior ou digitação direta dos valores apesar da cor de alerta. Esses problemas são frustrantes mas solucionáveis com uma lista de verificação sistemática.
Primeiro, confirme o máximo anunciado do modelo. Alguns cards comunitários indicam errado 16k devido a erro de empacotamento, enquanto o modelo real suporta 128k. Segundo, tente digitar o número no campo de texto; se ficar vermelho mas carregar, você ultrapassou o limite do slider. Terceiro, defina a política de overflow para “Parar no limite” para evitar corromper um prompt sistemático cuidadosamente elaborado. Quarto, valide com um conjunto longo de parágrafos fictícios e peça ao modelo para resumir partes iniciais, médias e finais para provar que tem visibilidade total.
Se o LM Studio ainda recusar, considere se a variante de quantização tem um limite rígido nos metadados. Algumas conversões GGUF embutem um contexto padrão diferente do modelo original. Como o limite pode atuar como metadado de exibição e não teto efetivo, a abordagem do campo de texto muitas vezes basta; ainda assim, monitore logs de carga para confirmar. Também certifique-se de que a VRAM é suficiente. Janelas muito grandes incham a cache key-value, levando a lentidão ou erros por falta de memória. Se os travamentos persistirem, reduza o contexto, use quantização de menor precisão ou divida a tarefa em partes.
Fora do LM Studio, é prudente acompanhar como modelos líderes tratam prompts longos na prática. Análises como ChatGPT vs. Claude e artigos detalhados como como o DeepSeek mantém treinamento acessível ajudam a formar expectativas. Contexto longo só tem significado se o modelo realmente o usa; caso contrário, recuperação ou melhor estrutura de prompt podem superar aumentos brutos de tamanho.
- 🧰 Se o slider parar em 16k, tente usar o campo numérico de qualquer forma.
- 🧯 Mude a política de overflow para “Parar no limite” para tarefas estruturadas.
- 🧠 Valide compreensão inicial/média/final com prompt sintético longo.
- 🖥️ Monitore VRAM; contexto alto multiplica memória do cache KV.
- 📜 Cheque logs ao carregar para conhecer o comprimento aplicado do contexto.
| Sintoma 🐞 | Causa provável 🔎 | Correção 🛠️ |
|---|---|---|
| Slider limitado a 16k | Quirks de UI ou metadados | Digite o comprimento no campo numérico ➕ |
| Aviso vermelho ao salvar | Portão de validação, não bloqueio rígido | Carregue para confirmar que ainda se aplica 🚦 |
| OOM ou lentidão | Explosão do cache KV | Reduza contexto ou use quantização mais leve 🧮 |
| Estrutura perdida | Truncamento do meio | Defina política de overflow para “Parar no limite” 🧱 |
| Desalinhamento com docs | Metadados da conversão | Confira logs e faça teste com prompt longo 🔍 |
Para aprendizes visuais, tutoriais sobre teste e benchmarking de contexto longo são inestimáveis.
Com uma lista disciplinada, limites teimosos de contexto tornam-se um incômodo temporário em vez de um bloqueio.
Escolhendo o tamanho certo para geração local de texto: manuais, testes e estratégia
Não existe um tamanho de janela universalmente melhor. A escolha certa deriva da tarefa, da família do modelo e do hardware. Um assistente de codificação se beneficia de uma janela média mais recuperação dos arquivos mais relevantes. Um pesquisador legal pode priorizar uma janela maior, mas ainda assim usar fragmentação para evitar entupir o modelo com páginas irrelevantes. Um podcaster que redige resumos de episódios de longas transcrições pode misturar contexto generoso com seccionamento inteligente para manter coerência.
Uma abordagem prática é o “teste escada”: comece com o máximo documentado, então desça ou suba observando latência e precisão. Use entradas longas específicas do domínio e verifique se as seções iniciais e finais são ambas referenciadas. Se o modelo parece esquecer o começo em tamanhos maiores, reduza a janela ou aplique escala RoPE com cautela. Quando prompts ultra-longos forem vitais, complemente com recuperação para que o modelo veja uma fatia selecionada em vez do arquivo inteiro.
Também ajuda comparar expectativas lendo recursos comparativos como ChatGPT vs. GitHub Copilot e panoramas industriais mais amplos como a cobertura do processo “bend time”. Essas referências oferecem contexto sobre como diferentes ecossistemas tratam entradas longas e fluxos de trabalho de desenvolvedor. Paralelamente, guias sobre temas operacionais—como dominar chaves de API do ChatGPT—destacam como detalhes de configuração repercutem em ganhos reais de produtividade.
- 🪜 Use testes escada para achar o ponto ideal para seu hardware.
- 📚 Combine janelas longas com recuperação e fragmentação para precisão.
- ⏱️ Acompanhe mudanças na latência conforme a janela cresce; ajuste conforme.
- 🧭 Prefira “Parar no limite” para prompts frágeis e estruturados.
- 🧪 Valide qualidade com tarefas que espelhem cargas reais.
| Uso 🎬 | Contexto sugerido 📏 | Política de overflow 🧱 | Notas 🗒️ |
|---|---|---|---|
| Assistente de código | 8k–24k | Parar no limite | Associe a recuperação em nível de arquivo 💼 |
| Revisão legal | 32k–64k | Parar no limite | Fragmentar por seção; manter citações visíveis 📖 |
| Transcrições de podcast | 16k–48k | Parar no limite | Resumir por segmento, depois mesclar 🎙️ |
| Síntese de pesquisa | 24k–64k | Parar no limite | Escala RoPE com validação cuidadosa 🔬 |
| Chat geral | 4k–16k | Parar no limite | Arquivar turnos antigos, recuperar conforme necessário 💬 |
Esses manuais se combinam com perspectivas práticas do mercado—veja análises como inovação em sistemas de raciocínio e uma pesquisa de apps de chatbots AI de nicho para entender como várias ferramentas ampliam ou limitam fluxos de trabalho de contexto longo. O método prevalece: ajuste o tamanho da janela para a tarefa, depois prove com testes que refletem a realidade.
Notas do mundo real da comunidade: versões, metadados e práticas seguras
O feedback da comunidade cristalizou várias verdades sobre alterar a janela de contexto no LM Studio. Um tema recorrente descreve o cenário “Q4KM mostra máximo de 16k” que se revelou ser problema de metadados em vez de limite rígido. Outro nota que a caixa numérica da UI aceita valores além do slider, mesmo marcada em vermelho, e esses valores são aplicados na carga. Usuários também confirmam que o comprimento do contexto em algumas configs afeta mais a exibição do que a conversão, explicando porque edições aparentemente não funcionam, mas o comprimento em runtime muda.
O comportamento por versão merece atenção. Uma certa build 0.3.24 endureceu o salvamento na UI para valores acima do máximo, o que levou alguns usuários a voltar para versões anteriores que permitiam entradas manuais. Independentemente da versão, a prática mais robusta é digitar o valor alvo, definir overflow para “Parar no limite” e validar com inputs longos. Na dúvida, confie nos logs, não no slider. Clareza sobre o que é metadado versus limite imposto economiza horas.
Hardware e planejamento também importam. Janelas muito grandes aumentam a cache KV e desaceleram respostas. Para trabalho sustentado, ou reduza o contexto ou combine contexto moderado com recuperação. Artigos de orientação estratégica—como o papel da NVIDIA na escala da infraestrutura de IA—lembram que ajuste de desempenho é um exercício de ponta a ponta. Para praticantes, listas como códigos de erro comuns oferecem um checklist prático na solução de problemas.
Por fim, ajuda medir suposições contra comparativos mais amplos. Ler como o ChatGPT se compara ao Perplexity ou explorar tendências de acesso regionais fundamenta expectativas para uso de longo contexto além de uma ferramenta só. Enquanto o LM Studio oferece controle granular localmente, hábitos importados de modelos em nuvem às vezes precisam de ajustes para combinar com hardware local e realidades de quantização.
- 📌 Considere “máximo 16k” das caps de UI como suspeito; confirme com logs e testes.
- 🧭 Prefira entradas numéricas digitadas em vez de sliders se discordarem.
- 🧱 Use “Parar no limite” para proteger prompts estruturados e agentes.
- 🧮 Cuidado com VRAM e quantização; janelas grandes podem ser caras.
- 🧪 Valide com entradas longas, específicas e realistas.
| Insight da comunidade 🗣️ | O que significa 💡 | Passo acionável 🚀 |
|---|---|---|
| Slider para cedo | Provável desalinhamento UI/metadados | Digite valor manualmente, depois teste 📏 |
| Caixa vermelha ainda funciona | Aviso de validação, não imposição | Carregue modelo e cheque logs 🚦 |
| Config vs. conversão | Algumas entradas são só metadados | Não reconverta; ajuste em runtime 🧰 |
| Variabilidade por versão | Comportamento mudou entre builds | Tenha instalador estável à mão 🗃️ |
| Custos do contexto longo | Cache KV cresce com tokens | Dimensione certo a janela, use recuperação 🧠 |
Para visão mais ampla, comparativos como OpenAI vs. Anthropic e editoriais como escolhas estratégicas de talentos em tecnologia mostram por que fluência em configuração é tão importante quanto a escolha do modelo. A conclusão duradoura: verifique, teste e documente as configurações que realmente fazem diferença para sua carga de trabalho.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Can the context window be increased beyond the slider cap in LM Studio?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Yes. Click the numeric field next to the slider and type the desired token count. Even if the box turns red, LM Studio frequently applies the value at load time. Confirm by checking logs and testing with a long prompt.”}},{“@type”:”Question”,”name”:”Which overflow policy is safest for structured prompts?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Stop at limit. It prevents mid-prompt truncation, protecting system prompts, function schemas, and tool formats. This setting is particularly useful for agent-style workflows and memory-heavy sessions.”}},{“@type”:”Question”,”name”:”Does RoPE scaling guarantee good long-context performance?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”No. RoPE scaling can extend effective context but may reduce coherence at very high lengths. Use modest scaling, validate with real tasks, and combine with retrieval for reliable results.”}},{“@type”:”Question”,”name”:”Why do some models show 16k max when the card says 128k?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”That mismatch often reflects metadata in the conversion package. Try entering a higher value manually and validate the applied length at runtime; treat the slider as advisory, not authoritative.”}},{“@type”:”Question”,”name”:”How to choose the right window size for local text generation?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Use ladder tests: start with the documented max, observe latency and quality, then adjust. Pair moderate windows with retrieval and set overflow to Stop at limit for structured work.”}}]}A janela de contexto pode ser aumentada além do limite do slider no LM Studio?
Sim. Clique no campo numérico ao lado do slider e digite a contagem de tokens desejada. Mesmo que a caixa fique vermelha, o LM Studio frequentemente aplica o valor no momento da carga. Confirme verificando os logs e testando com um prompt longo.
Qual política de overflow é mais segura para prompts estruturados?
Parar no limite. Evita truncamento no meio do prompt, protegendo prompts do sistema, esquemas de função e formatos de ferramentas. Essa configuração é particularmente útil para fluxos de trabalho do tipo agente e sessões com muita memória.
A escala RoPE garante bom desempenho em contexto longo?
Não. A escala RoPE pode estender o contexto efetivo, mas pode reduzir a coerência em comprimentos muito altos. Use escala modesta, valide com tarefas reais e combine com técnicas de recuperação para resultados confiáveis.
Por que alguns modelos mostram máximo de 16k quando o cartão indica 128k?
Esse desalinhamento frequentemente reflete metadados no pacote de conversão. Tente digitar manualmente um valor maior e valide o comprimento aplicado na execução; trate o slider como um indicativo, não como definitivo.
Como escolher o tamanho correto da janela para geração local de texto?
Use testes em escada: comece com o máximo documentado, observe a latência e qualidade, depois ajuste. Combine janelas moderadas com recuperação e defina overflow para Parar no limite em trabalhos estruturados.



OpenAI vs Microsoft: Principais Diferenças Entre ChatGPT e GitHub Copilot em 2025
Divisão Arquitetônica em 2025: Acesso Direto ao Modelo vs RAG Empresarial Orquestrado A diferença mais decisiva entre o ChatGPT da...


Qual Será a Principal IA para Criar um Currículo Impressionante em 2025?
Qual Será a Principal IA para Criar um Currículo Impressionante em 2025? Critérios Que Separam os Vencedores do Grupo Nos...


Newsearch em 2025: o que esperar da próxima geração de motores de busca online
Newsearch em 2025: IA generativa transforma motores de busca online em assistentes A busca não é mais uma lista de...


Chya explicado: benefícios, usos e efeitos colaterais em 2025
Chya explicado em 2025: benefícios para a saúde baseados em evidências, antioxidantes e densidade nutricional Chya—mais conhecido como chaya (Cnidoscolus...


xr update: as principais notícias e insights de vr para 2025
Atualização XR 2025: Notícias Empresariais sobre VR, Sinais de ROI e Avanços Setoriais A Atualização XR nas empresas mostra uma...


Como dominar o jogo de clicar na barra de espaço em 2025
Fundamentos do Clicker da Barra de Espaço: CPS, Loops de Feedback e Domínio no Início do Jogo Jogos clicker da...


i bubble letter: ideias criativas e tutoriais para iniciantes
Como Desenhar a Letra Bolha i: Tutorial Passo a Passo para Iniciantes Absolutos Começar com a letra bolha i minúscula...


Apresentando uma Versão Gratuita do ChatGPT Projetada Especificamente para Educadores
Por que um ChatGPT Gratuito para Educadores é Importante: Espaço de Trabalho Seguro, Controles Administrativos e Ferramentas de Ensino Focadas...


Uma Visão Abrangente do Panorama Tecnológico em Palo Alto até 2025
Plataformização Movida por IA no Panorama Tecnológico de Palo Alto: Operações de Segurança Reimaginadas O Panorama Tecnológico de Palo Alto...


a física AP realmente é tão difícil? o que os estudantes devem saber em 2025
AP Physics é realmente tão difícil em 2025? Dados, taxas de aprovação e o que realmente importa Pergunte a um...


ChatGPT Serviço Interrompido: Usuários Enfrentam Quedas Durante Interrupção do Cloudflare | Hindustan Times
Serviço ChatGPT Interrompido: Interrupção do Cloudflare Gera Quedas Globais e Erros 500 Ondas de instabilidade varreram a web quando uma...


Principais IAs de Escrita de 2025: Uma Comparação Abrangente e Guia do Usuário
Principais IAs de Escrita de 2025: Performance Comparativa e Casos Reais de Uso Escolher uma IA de escrita em 2025...


Compreendendo a persistência da imagem: causas, prevenção e soluções
Compreendendo persistência de imagem versus burn-in de tela: definições, sintomas e dinâmica de imagem residual do display Persistência de imagem...


Você pode alterar a janela de contexto no lmstudio?
Alterando a janela de contexto no LM Studio: o que é e por que importa O termo janela de contexto...


Como obter a hora atual em swift
Essenciais do Swift: Como Obter a Hora Atual com Date, Calendar e DateFormatter Obter a hora atual em Swift é...


Como os detectores de vape estão transformando a segurança escolar em 2025
Como os detectores de vape estão transformando a segurança escolar em 2025: visibilidade orientada por dados sem invasão da privacidade...


A IA Está Alimentando Delírios? Preocupações Crescentes Entre Famílias e Especialistas
A IA Está Alimentando Delírios? Famílias e Especialistas Acompanham um Padrão Preocupante Relatos de Delírios reforçados por IA saíram de...


Como criar e gerenciar ambientes Python com conda env create em 2025
Conda env create em 2025: construindo ambientes Python isolados e reprodutíveis passo a passo Isolamento limpo é a base de...


Desbloqueie o Poder do ChatGPT Group Chat Gratuitamente: Um Guia Passo a Passo para Começar
Como Obter Acesso Gratuito e Iniciar um Bate-Papo em Grupo no ChatGPT: Um Guia Passo a Passo para Começar O...


Como maximizar seus benefícios das minhas avaliações em 2025
Como maximizar seus benefícios com minhas avaliações em 2025: Estratégia, ROI e Execução As avaliações de 2025 valem tanto quanto...
-

 Modelos de IA20 hours ago
Modelos de IA20 hours agomodelos vietnamitas em 2025: novos rostos e estrelas em ascensão para ficar de olho
-
Tecnologia8 hours ago
Uma Visão Abrangente do Panorama Tecnológico em Palo Alto até 2025
-

 Tecnologia3 days ago
Tecnologia3 days agoSeu cartão não suporta este tipo de compra: o que significa e como resolver
-
Uncategorized17 hours ago
Desbloqueie o Poder do ChatGPT Group Chat Gratuitamente: Um Guia Passo a Passo para Começar
-

 Modelos de IA3 days ago
Modelos de IA3 days agoOpenAI vs Tsinghua: Escolhendo Entre ChatGPT e ChatGLM para Suas Necessidades de IA em 2025
-
Uncategorized6 hours ago
Apresentando uma Versão Gratuita do ChatGPT Projetada Especificamente para Educadores