
KI-Modelle
Kannst du das Kontextfenster in lmstudio ändern?
Ändern des Kontextfensters in LM Studio: was es ist und warum es wichtig ist
Der Begriff Kontextfenster beschreibt, wie viel Text ein Sprachmodell auf einmal berücksichtigen kann. In LM Studio (oft von Praktikern zu lmstudio verkürzt) steuert dieses Fenster die maximale Eingabelänge und die Menge der vergangenen Gespräche oder Dokumente, die die aktuelle Textgenerierung beeinflussen. Wenn das Token-Limit überschritten wird, werden wichtige Details abgeschnitten, was Antworten entgleisen lassen oder oberflächliches Denken erzeugen kann. Daher ist die Anpassung der Fenstergröße eine der folgenschwersten KI-Einstellungen, die jedem zur Verfügung stehen, der Modelle lokal betreibt.
Warum überhaupt ändern? Teams jonglieren oft mit großen PDFs, langen Chatverläufen oder umfangreichen Quelltexten. Ein Forscher, der 30-seitige Memos erstellt, benötigt mehr Spielraum als ein schneller Chatbot. Auch ein Entwickler, der einen mehrteiligen Code-Base analysiert, profitiert von einem größeren Puffer. LM Studio bietet Modellparameter zur Ladezeit (z. B. Kontextlänge) und Inferenzzeit (z. B. Überlaufverhalten) an, wodurch maßgeschneiderte Einstellungen für unterschiedliche Arbeitslasten möglich sind. Die Wahl der richtigen Größe bedeutet, Geschwindigkeit, Kosten (in VRAM und RAM) und Antwortqualität abzuwägen.
Nehmen Sie „Maya“ als Beispiel, eine Datenanalystin, die Compliance-Berichte zusammenstellt. Wenn das Fenster zu eng eingestellt ist, verschwinden Zitate und Verweise werden vage. Nach Erhöhung der Kontextlänge in LM Studio behält das Modell mehr Fußnoten, antwortet mit präzisen Verweisen und verwendet über hunderte Zeilen hinweg konsistente Terminologie. Der Unterschied ist nicht nur kosmetisch; er verändert, was das Modell während eines Gesprächs wissen kann.
Wichtige Gründe, warum Nutzer das Limit erhöhen, sind auch längere Funktionsaufruf-Schemata, komplexe Systemprompts und mehrstufige Chats mit angehängten Dokumenten. Die Konfiguration von LM Studio erlaubt, das Verhalten über die Standardeinstellungen hinaus anzupassen, allerdings ist das Bewusstsein für modell-spezifische Maxima entscheidend. Einige Modelle liefern standardmäßig 4k–16k Tokens, andere werben mit 128k oder mehr. Die tatsächliche Leistung hängt sowohl vom Training des Modells als auch vom Laufzeitansatz (z. B. Positionskodierung und Aufmerksamkeitsstrategien) ab.
- 🔧 Erweitern Sie die Fenstergröße, um lange Anweisungen zu bewahren und Abschneidungen zu reduzieren.
- 🧠 Verbessern Sie das Multidokumenten-Denken, indem mehr Kontext im Speicher gehalten wird.
- ⚡ Balancieren Sie Geschwindigkeit gegen Qualität; größere Fenster können die Generierung verlangsamen.
- 🛡️ Verwenden Sie Überlaufregeln, um Sicherheit beim Erreichen des Token-Limits zu gewährleisten.
- 📈 Überwachen Sie Qualitätskompromisse bei Verwendung erweiterter Kontexttechniken.
Die Wahl der richtigen Größe hängt auch von der Aufgabe ab. Für hochpräzise Programmierunterstützung empfiehlt sich ein mittleres Kontextfenster plus gezielte Suche. Für literarische Analysen oder juristische Prüfungen ist ein großes Fenster nützlich – sofern das Modell es tatsächlich gut handhaben kann. Im Ökosystem von 2025 zeigen Vergleiche wie ChatGPT versus Perplexity und OpenAI versus Anthropic, wie Modellfamilien Prioritäten unterschiedlich gewichten, wenn es um Langzeit-Kontextverständnis geht. Lokale Ausführungen wollen dieselbe Power, müssen sie aber klug konfigurieren.
| Konzept ✨ | Was es steuert 🧭 | Auswirkung auf Ergebnisse 📊 |
|---|---|---|
| Kontextfenster | Maximale Tokens, die das Modell „sehen“ kann | Beibehaltung von Anweisungen und Verweisen |
| Fenstergröße | Kontextlänge zur Ladezeit | Latenz, Speicherverbrauch, Kohärenz |
| Überlaufregel | Verhalten bei Erreichen des Limits | Sicherheit, Determinismus oder Abschneidemuster |
| Modellparameter | RoPE-Skalierung, KV-Cache usw. | Effektive Maximal-Länge und Stabilität |
| KI-Einstellungen | UI-Konfiguration in LM Studio | Arbeitsabläufe passend zu verschiedenen Aufgaben |
Fazit: Die Änderung der Kontextlänge in LM Studio ist kein bloßer Schalter – es ist eine strategische Entscheidung, die bestimmt, wie viel das Modell in einem Durchgang behalten und ableiten kann.

LM Studio-Steuerungen: Überlaufregel, Schieberegler und der „rote Box“-Trick
LM Studio bietet mehrere Wege, das Kontextfenster zu verändern. In der UI steuern ein Schieberegler und ein Zahlenfeld die konfigurierte Fenstergröße. Ein von der Community gemeldeter Sonderfall ist, dass der Schieberegler bei 16k Tokens für bestimmte Quantisierungen begrenzt ist, obwohl die zugrundeliegenden Modelldaten mehr unterstützen (zum Beispiel 128k). Wenn der Regler nicht weiter nach rechts geht, klicken viele Nutzer einfach auf das Zahlenfeld und geben die gewünschte Tokenanzahl ein. Der Wert kann rot werden und anzeigen, dass es nicht gespeichert wird – dennoch wird er oft zur Laufzeit angewendet. Dieses unerwartete Verhalten ermöglicht erfahrenen Nutzern, UI-Hürden ohne zusätzliche Werkzeuge zu umgehen.
Eine weitere wichtige Einstellung ist die Überlaufregel für den Kontext. Der Standard „System-Prompt behalten, Mitte abschneiden“ kann bestimmte Speicherverwaltungen und Agenten unterbrechen. Der Wechsel zu „Stop at limit“ sorgt dafür, dass das Modell an der Grenze stoppt, statt die Mitte eines strukturierten Prompts zu zerstören. Nutzer, die Speicher-Frameworks oder Tools ähnlich MemGPT integrieren, berichten nach der Wahl von „Stop at limit“ von deutlich weniger Problemen. Es ist ein einfacher Fix, der die Struktur bewahrt und stille Beschädigung wichtigen Textes verhindert.
Versionsdetails sind wichtig. Einige Nutzer beobachteten, dass ab einer bestimmten Version 0.3.24 die UI keine Kontextgrößen oberhalb des beworbenen Maximums mehr speichert, wodurch sie entweder versteckte Konfigurationsdateien bearbeiten oder vorübergehend eine frühere Version verwenden mussten, die manuelle Werte zuließ. Die Kernbotschaft ist, dass die Änderung im Zahlenfeld häufig einen Laufzeitparameter aktualisiert, während einige JSON-Einträge nur als Metadaten für die Anzeige dienen und die Modellkonvertierung nicht beeinflussen. Wenn man diesen Unterschied versteht, vermeidet man unnötiges Re-Quantisieren oder Datei-Hantieren.
Für Teams, die mit lokalen LLMs starten, hilft ein kleines Playbook, Fehltritte zu vermeiden. Erstens überprüfen Sie das dokumentierte maximale Kontextfenster des Modells. Zweitens stellen Sie in LM Studio das Zahlenfeld auf dieses Maximum, auch wenn der Schieberegler früher endet. Drittens setzen Sie den Überlauf auf „Stop at limit“ für strukturierte Prompts. Schließlich testen Sie mit einem synthetischen langen Dokument, ob Inhalte jenseits der bisherigen Grenze jetzt erkannt und korrekt referenziert werden.
- 🧩 Wenn der Schieberegler bei 16k abschließt, geben Sie die Zahl direkt in das Feld ein.
- 🛑 Bevorzugen Sie „Stop at limit“, wenn Sie strikte Struktur brauchen.
- 🧪 Validieren Sie mit einem langen Dummy-Prompt, um die Änderung nachzuweisen.
- 📂 Behandeln Sie config.json-Grenzen als UI-Metadaten, sofern nicht anders dokumentiert.
- 💡 Notieren Sie sich die LM Studio-Version und das Changelog für Kontextlängen-Verhalten.
Diese Schritte passen gut zu breiteren Evaluierungen. Beispielsweise helfen Feature-Vergleiche wie Gemini versus ChatGPT und die 2025 ChatGPT-Bewertung, Erwartungen an Langzeit-Kontextperformance zwischen verschiedenen Ökosystemen einzuordnen. Zu beobachten, wo Cloud-Giganten den Kontext betonen, leitet auch lokales Feintuning an.
| Aktion 🔁 | Ort in LM Studio 🖥️ | Warum es hilft ✅ |
|---|---|---|
| Kontextlänge manuell eingeben | Zahlenfeld neben dem Schieberegler | Umgeht 16k UI-Begrenzung 🪄 |
| Überlauf auf „Stop at limit“ setzen | Inference-Einstellungen | Verhindert Abschneiden mitten im Prompt 🧱 |
| Modell-Metadaten prüfen | Modell-Info-Panel | Bestätigt beworbene Maximal-Länge 📜 |
| Versionscheck | Info oder Release-Notes | Erklärt geändertes Speicherverhalten 🗂️ |
| Lang-Prompt-Test | Chat- oder Kompositionsansicht | Empirische Validierung der neuen Fenstergröße 🧪 |
Für tiefere Einblicke in Konfigurationsgewohnheiten und praktische Vergleiche sind Videoanleitungen zum lokalen LLM-Setup hilfreich.

Mit diesen Steuerungen können Teams LM Studio sicher über die Standardeinstellungen hinaus schieben und ihre Prompts vor heimlichem Abschneiden schützen.
Über die Trainingsgrenzen hinaus: RoPE-Skalierung und effektive Kontextlänge
Kontext erweitern ist nicht nur eine Frage von Schiebereglern. Viele transformer-basierte Modelle nutzen Rotary Positional Embeddings (RoPE), und LM Studio zeigt einen Ladezeitparameter, der die Positionsinformation skaliert. Durch Erhöhung dieses Faktors können Modelle längere Sequenzen berücksichtigen, indem die Positionskodierung feiner wird. Das ist ein mächtiger Trick – aber nicht kostenlos. Mit steigender Skalierung kann die lokale Kohärenz abnehmen und manche Modelle hallucinieren bei sehr langen Kontexten stärker. Zu wissen, wann RoPE-Skalierung sinnvoll ist, ist genauso wichtig wie zu wissen, wie man sie einsetzt.
Die LM Studio-Dokumentation beschreibt, wie ein Skalierungsfaktor das effektive Fenster anpasst. Praktisch bedeutet das, dass ein für 8k trainiertes Modell mit tolerierbarem Qualitätsverlust manchmal bei 16k–32k läuft, abhängig von Architektur und Quantisierung. Wenn Nutzer berichten, dass ein GGUF-Build ein 16k-Maximum in der UI zeigt, das zugrundeliegende Modell aber 128k verspricht, weist das oft auf einen Metadaten-Fehler hin. In solchen Fällen klärt eine Erhöhung des Zahlenwerts und eine Validierung durch einen langen Testdialog die tatsächliche Grenze. Community-Berichte zeigen auch, dass das Editieren des Werts – selbst wenn die UI ihn rot markiert – zur Ladezeit die gewünschte Länge anwenden kann.
Wie weit kann man gehen? Das hängt von Modellfamilie und Aufmerksamkeitsmechanismus ab. Ansätze wie Sliding-Window-Attention und hybride Recurrent/Transformer-Designs vertragen längere Kontexte anders als reine Attention-Mechanismen. Das Interesse an Alternativen, darunter State-Space-Modelle, wächst, da Teams lange Sequenzen ohne übermäßigen Speicherverbrauch erforschen. Diskussionen über State-Space-Modelle und Speicherverbrauch verdeutlichen, warum Langzeit-Kontext nicht nur eine Zahl ist, sondern eine Frage von Stabilität und Architektur.
Mayas Team nutzte RoPE-Skalierung vernünftig für Quartalszusammenfassungen. Bei 24k Tokens blieben Antworten klar. Bei 48k wuchs die Latenz, und Zusammenfassungen vergaßen manchmal frühe Details, was auf abnehmenden Nutzen hindeutete. Sie entschieden sich für 32k mit Retrieval-Unterstützung, was Qualität bewahrte und massive Verlangsamungen vermied. Die Lehre: Größere Fenster sollten Retrieval und Chunking ergänzen, nicht ersetzen.
- 🧮 Beginnen Sie mit moderater Skalierung (z. B. 1,5–2×) bevor Sie höher gehen.
- 🧭 Kombinieren Sie Langzeit-Kontext mit Retrieval, damit das Modell nur relevante Ausschnitte sieht.
- 📉 Achten Sie auf Kohärenzeinbußen bei sehr hohen Token-Anzahlen.
- 🧰 Behalten Sie Quantisierung und VRAM-Grenzen im Blick, wenn Sie das Fenster strecken.
- 🔍 Validieren Sie mit domänenspezifischen Langzeit-Tests statt generischen Prompts.
Vergleichende Berichte wie ChatGPT vs. Gemini 2025 und Überblicke wie Meilensteine in ChatGPTs Entwicklung geben weiteren Kontext, wie Anbieter das Rennen um Langzeit-Kontext gestalten. Auch wenn das lokale Modell anders ist, spiegeln sich ähnliche Kompromisse im gesamten Feld wider.
| RoPE-Skalierungsoption 🧯 | Vorteile 🌟 | Nachteile ⚠️ | Anwendung 🎯 |
|---|---|---|---|
| 1,0× (Standard) | Stabil, vorhersehbar | Begrenzte Maximal-Länge | Qualitätskritische Aufgaben ✅ |
| 1,5–2,0× | Deutlich längerer Kontext | Leichter Kohärenzverlust | Berichte, leichte Codeanalyse 📄 |
| 2,5–4,0× | Große Multi-Dokument-Sessions | Latenz, Drift-Risiken | Explorative Forschung 🔬 |
| 4,0×+ | Extreme Sequenzen | Wahrscheinlich instabile Ausgaben | Benchmarks und Experimente 🧪 |
Die pragmatische Erkenntnis: RoPE-Skalierung kann die Reichweite verlängern, aber Retrieval und Prompt-Engineering liefern oft stabilere Verbesserungen pro Token.
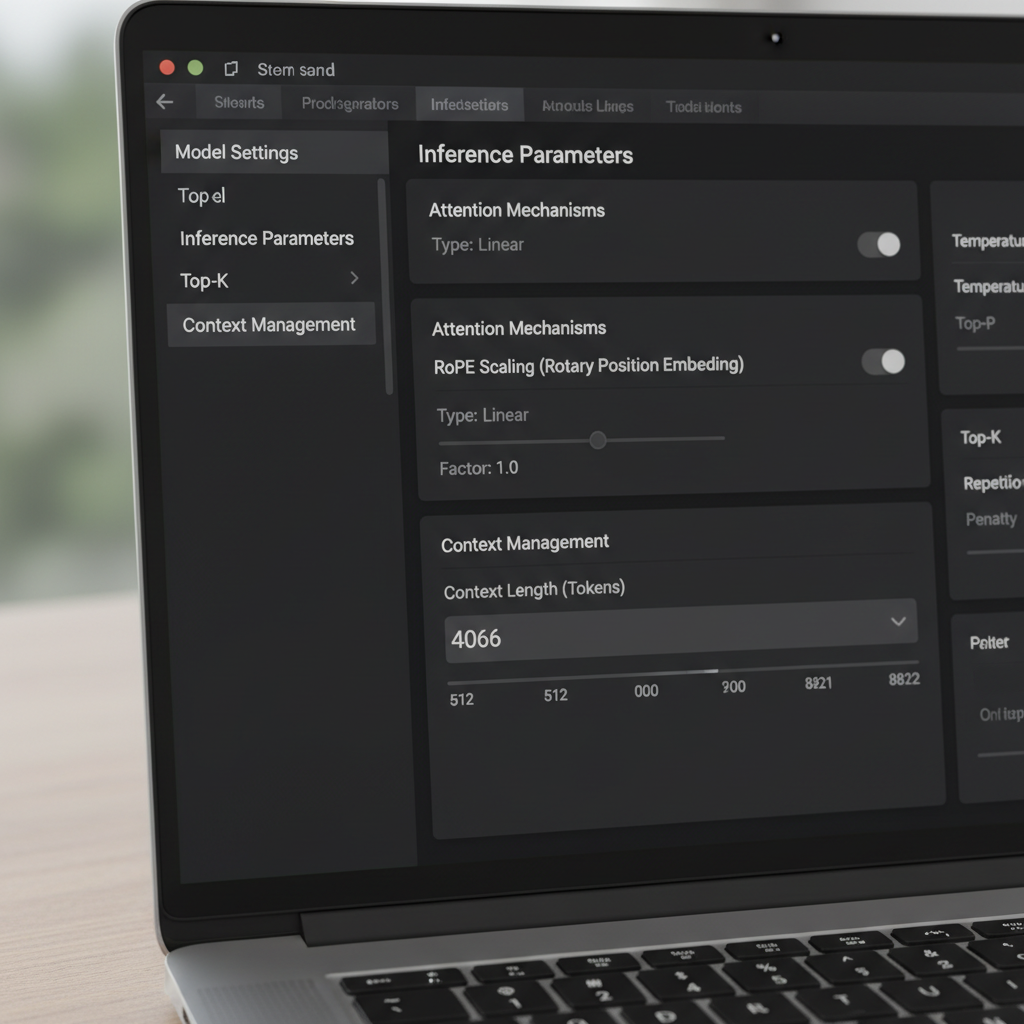
Wenn die Fenstergröße nicht weicht: Fehlerbehebung bei Langzeit-Kontextproblemen in LM Studio
Gelegentlich widersetzt sich LM Studio einer Änderung. Nutzer berichten von einem „max 16k“-Schieberegler bei bestimmten Quantisierungen, obwohl das Basismodell weitaus mehr unterstützt. Andere sahen, dass eine neuere Version das Speichern höherer Werte verhinderte, was sie zwang, eine ältere Version temporär zu verwenden oder Werte trotz Warnfarben direkt einzutippen. Diese Probleme sind ärgerlich, aber mit checklistenartiger Vorgehensweise lösbar.
Erstens: Bestätigen Sie das dokumentierte maximale Kontextvolumen des Modells. Manche Community-Karten listen irrtümlich 16k aufgrund eines Verpackungsfehlers, obwohl das tatsächliche Modell 128k unterstützt. Zweitens: Versuchen Sie, die Zahl im Textfeld einzugeben; wird sie rot, aber lädt dennoch, haben Sie die Begrenzung des Schiebereglers umgangen. Drittens: Stellen Sie die Überlaufregel auf „Stop at limit“, um ein Zerreißen eines sorgfältig gestalteten System-Prompts zu verhindern. Viertens: Validieren Sie mit langen Dummy-Absätzen und lassen Sie das Modell frühe, mittlere und späte Abschnitte zusammenfassen, um vollständige Sichtbarkeit zu beweisen.
Wenn LM Studio weiterhin widerspenstig ist, prüfen Sie, ob die Quantisierungs-Variante eine harte Grenze in den Metadaten hat. Manche GGUF-Konvertierungen enthalten einen Standard-Kontext, der vom Originalmodell abweicht. Da die Grenze oft nur als Anzeige-Metadatum und nicht als harte Decke wirkt, reicht häufig der Weg übers Textfeld; beobachten Sie dennoch die Logs beim Laden, um sicherzugehen. Vergewissern Sie sich außerdem, dass der VRAM ausreicht. Sehr große Fenster vergrößern den Key-Value-Cache, was zu Verlangsamungen oder Speicherfehlern führt. Bei anhaltenden Abstürzen reduzieren Sie den Kontext, nutzen eine Quantisierung mit niedrigerer Präzision oder teilen die Aufgabe in kleinere Abschnitte.
Über LM Studio hinaus lohnt es sich, nachzuvollziehen, wie führende Modelle lange Prompts praktisch handhaben. Analysen wie ChatGPT vs. Claude und tiefere Berichte wie wie DeepSeek günstiges Training ermöglicht informieren die Erwartungen. Langzeit-Kontext ist nur dann sinnvoll, wenn er vom Modell auch treu genutzt wird; sonst liefern Retrieval oder bessere Prompt-Strukturen oft mehr als bloßes Vergrößern.
- 🧰 Wenn der Schieberegler bei 16k endet, versuchen Sie es trotzdem mit dem Zahlenfeld.
- 🧯 Schalten Sie den Überlauf für strukturierte Aufgaben auf „Stop at limit“.
- 🧠 Validieren Sie frühes/mittleres/spätes Verständnis mit einem synthetischen Lang-Prompt.
- 🖥️ Achten Sie auf VRAM; hoher Kontext vergrößert den KV-Cache erheblich.
- 📜 Prüfen Sie beim Laden die Logs für die angewandte Kontextlänge.
| Symptom 🐞 | Wahrscheinliche Ursache 🔎 | Lösung 🛠️ |
|---|---|---|
| Schieberegler endet bei 16k | UI- oder Metadatenbesonderheit | Länge im Zahlenfeld eingeben ➕ |
| Rote Warnung beim Speichern | Validierungstor, kein Stopp | Laden und prüfen, ob Wert angewandt wird 🚦 |
| OOM oder Verlangsamung | Explosion des KV-Caches | Kontext reduzieren oder leichtere Quantisierung nutzen 🧮 |
| Struktur verloren | Abschneiden in der Mitte | Überlauf auf „Stop at limit“ stellen 🧱 |
| Diskrepanz zu Dokumentation | Konvertierungsmetadaten | Logs prüfen und Lang-Prompt-Test machen 🔍 |
Für visuelle Lerntypen sind Schritt-für-Schritt-Anleitungen zu Langzeit-Kontexttests und Benchmarks sehr wertvoll.

Mit einem disziplinierten Checklist-Ansatz werden hartnäckige Kontextgrenzen eher vorübergehend zum Ärgernis statt zum Blocker.
Die richtige Größe für lokale Textgenerierung wählen: Playbooks, Tests und Strategie
Es gibt kein universelles bestes Fenstergröße-Setting. Die richtige Wahl ergibt sich aus Aufgabe, Modellfamilie und Hardware. Ein Programmierassistent profitiert von einem mittleren Fenster plus Retrieval der relevantesten Dateien. Ein Jurist könnte ein großes Fenster bevorzugen, setzt aber immer noch auf Chunking, um das Modell nicht mit irrelevanten Seiten zu überladen. Ein Podcaster, der Episodenzusammenfassungen aus langen Transkripten erstellt, kann großzügigen Kontext mit intelligenter Abschnittsbildung kombinieren, um Kohärenz zu wahren.
Ein praktischer Ansatz ist der „Leiter-Test“: Starten Sie mit dem dokumentierten Maximum, gehen sie schrittweise runter oder rauf, während Sie Latenz und Genauigkeit prüfen. Verwenden Sie lange, domänenspezifische Eingaben und verifizieren Sie, dass frühe und späte Abschnitte angesprochen werden. Wenn das Modell Anfangsabschnitte bei größeren Einstellungen vergisst, reduzieren Sie das Fenster oder wenden RoPE-Skalierung vorsichtig an. Wo ultra-lange Prompts kritisch sind, sollte Retrieval ergänzend eingesetzt werden, damit das Modell nur einen kuratierten Ausschnitt statt des gesamten Archivs sieht.
Es hilft auch, Erwartungen durch Benchmarking zu untermauern, indem man Vergleichsfeatures wie ChatGPT vs. GitHub Copilot und branchenweite Übersichten wie die „bend time“-Klageschlagzeilen liest. Diese Quellen bieten Kontext, wie verschiedene Ökosysteme Langtexte und Entwickler-Workflows behandeln. Parallel dazu schaffen Anleitungen zu operativen Themen – wie Meisterung von API-Schlüsseln – Bewusstsein dafür, wie Details in der Konfiguration zu tatsächlichen Produktivitätsgewinnen führen.
- 🪜 Nutzen Sie Leiter-Tests, um den Sweet Spot für Ihre Hardware zu finden.
- 📚 Kombinieren Sie lange Fenster mit Retrieval und Chunking für Präzision.
- ⏱️ Verfolgen Sie Latenzveränderungen mit wachsendem Fenster; passen Sie an.
- 🧭 Bevorzugen Sie „Stop at limit“ für fragile, strukturierte Prompts.
- 🧪 Validieren Sie Qualität mit Aufgaben, die reale Arbeitslasten widerspiegeln.
| Einsatzgebiet 🎬 | Empfohlener Kontext 📏 | Überlaufregel 🧱 | Hinweise 🗒️ |
|---|---|---|---|
| Code-Assistent | 8k–24k | Stop at limit | Kombinieren mit dateiebene Retrieval 💼 |
| Juristische Prüfung | 32k–64k | Stop at limit | Nach Abschnitten chunking; Zitate sichtbar halten 📖 |
| Podcast-Transkripte | 16k–48k | Stop at limit | Segmentweise Zusammenfassung, dann Zusammenführung 🎙️ |
| Forschungssynthese | 24k–64k | Stop at limit | RoPE-Skalierung mit sorgfältiger Validierung 🔬 |
| Allgemeiner Chat | 4k–16k | Stop at limit | Ältere Runden archivieren, nach Bedarf abrufen 💬 |
Diese Playbooks passen zu praktischen Marktperspektiven – siehe Analysen wie Innovation in Reasoning-Systemen und Umfragen zu Nischen-AI-Chatbots, wie verschiedene Tools Langzeit-Kontextworkflows forcieren oder begrenzen. Die Methode bleibt: Fenstergröße an den Job anpassen und mit realitätsnahen Tests beweisen.
Praxiserfahrungen aus der Community: Versionen, Metadaten und sichere Vorgehensweisen
Community-Feedback hat mehrere Erkenntnisse zum Ändern des Kontextfensters in LM Studio gefestigt. Ein wiederkehrendes Thema beschreibt ein „Q4KM zeigt maximal 16k“-Szenario, das sich als Metadatenproblem und nicht als harte Grenze herausstellte. Ein anderes beschreibt, dass das Zahlenfeld Werte über dem Schieberegler erlaubt, auch wenn sie rot markiert sind, und dass diese zur Ladezeit angewandt werden. Nutzer bestätigen zudem, dass die Kontextlänge in manchen Konfigurationen mehr die Anzeige betrifft als die Konvertierung, was erklärt, warum Änderungen scheinbar keine Wirkung zeigen, die Laufzeitlänge jedoch variiert.
Das Verhalten von Versionen verdient Aufmerksamkeit. Eine bestimmte Version 0.3.24 verschärfte das Speicherverhalten für Werte über dem Maximum, weshalb einige Anwender auf eine frühere Version zurückgriffen, die manuelle Eingaben erlaubte. Unabhängig von der Version ist die robusteste Vorgehensweise, den Zielwert zu tippen, Überlauf auf „Stop at limit“ zu setzen und mit langen Eingaben zu validieren. Im Zweifel verlässt man sich auf Logs, nicht auf den Schieberegler. Klarheit darüber, was Metadaten und was harte Grenzen sind, spart viel Zeit.
Hardware und Planung spielen ebenfalls eine Rolle. Sehr große Fenster erweitern den KV-Cache und verlangsamen die Antworten. Für dauerhafte Arbeit empfiehlt es sich, den Kontext zu reduzieren oder moderat zu halten und Retrieval zu kombinieren. Strategische Artikel – wie NVIDIAs Rolle beim Skalieren der KI-Infrastruktur – erinnern daran, dass Performance-Tuning eine End-to-End-Aufgabe ist. Für Praktiker bieten Listen wie häufige Fehlercodes praktische Hilfen beim Troubleshooting.
Zuletzt hilft es, Annahmen mit breiteren Vergleichen abzugleichen. Lesen Sie wie ChatGPT im Vergleich zu Perplexity abschneidet oder verfolgen Sie regionale Zugangstrends um Erwartungen für Langzeit-Kontextjutzung über einzelne Tools hinaus zu fundieren. Während LM Studio granular lokale Kontrolle bietet, erfordern Gewohnheiten aus Cloud-Modellen manchmal Anpassungen für lokale Hardware und Quantisierungsrealitäten.
- 📌 Behandeln Sie „16k max“-UI-Begrenzungen skeptisch; prüfen Sie mit Logs und Tests.
- 🧭 Bevorzugen Sie Zahlen-Eingaben über Schieberegler, wenn diese abweichen.
- 🧱 Verwenden Sie „Stop at limit“ zum Schutz strukturierter Prompts und Agenten.
- 🧮 Achten Sie auf VRAM und Quantisierung; lange Fenster können teuer sein.
- 🧪 Validieren Sie mit aufgabenspezifischen, langen und realistischen Eingaben.
| Community-Einsicht 🗣️ | Bedeutung 💡 | Konkrete Handlung 🚀 |
|---|---|---|
| Schieberegler begrenzt früh | Wahrscheinlich UI-/Metadaten-Missmatch | Wert manuell eingeben und testen 📏 |
| Rote Box funktioniert dennoch | Validierungswarnung, keine Durchsetzung | Modell laden und Logs prüfen 🚦 |
| Config vs. Konvertierung | Einige Einträge nur Metadaten | Keine Neu-Konvertierung; Laufzeit anpassen 🧰 |
| Versionsabweichungen | Verhalten ändert sich mit Builds | Stabile Installation griffbereit halten 🗃️ |
| Langzeit-Kontextkosten | KV-Cache wächst mit Tokens | Fenster passgenau wählen, Retrieval nutzen 🧠 |
Für breitere Perspektive bieten Vergleiche wie OpenAI vs. Anthropic und Artikel wie strategische Talententscheidungen im Tech-Bereich Einblick, warum Fluenz in der Konfiguration ebenso wichtig ist wie die Modellwahl. Die beständige Erkenntnis: Prüfen, testen und dokumentieren Sie die Einstellungen, die Ihre Workload wirklich voranbringen.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Kann das Kontextfenster in LM Studio über die Begrenzung des Schiebereglers hinaus vergrößert werden?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Ja. Klicken Sie auf das Zahlenfeld neben dem Schieberegler und geben Sie die gewünschte Tokenanzahl ein. Auch wenn das Feld rot wird, wendet LM Studio den Wert häufig zur Laufzeit an. Bestätigen Sie dies durch Prüfung der Logs und Tests mit einem langen Prompt.”}},{“@type”:”Question”,”name”:”Welche Überlaufregel ist für strukturierte Prompts am sichersten?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Stop at limit. Sie verhindert das Abschneiden mitten im Prompt und schützt System-Prompts, Funktionsschemata und Tool-Formate. Diese Einstellung ist besonders nützlich für Agenten-Arbeitsabläufe und speicherintensive Sitzungen.”}},{“@type”:”Question”,”name”:”Garantiert RoPE-Skalierung gute Langzeit-Kontextperformance?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Nein. RoPE-Skalierung kann den effektiven Kontext erweitern, kann aber die Kohärenz bei sehr langen Kontexten reduzieren. Verwenden Sie moderate Skalierung, validieren Sie mit realen Aufgaben und kombinieren Sie mit Retrieval für zuverlässige Ergebnisse.”}},{“@type”:”Question”,”name”:”Warum zeigen manche Modelle 16k max, obwohl die Karte 128k angibt?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Diese Diskrepanz spiegelt oft Metadaten im Konvertierungspaket wider. Versuchen Sie, manuell einen höheren Wert einzugeben und prüfen Sie die angewandte Länge zur Laufzeit; betrachten Sie den Schieberegler als Richtwert, nicht als verbindliche Grenze.”}},{“@type”:”Question”,”name”:”Wie wählt man die richtige Fenstergröße für lokale Textgenerierung?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Verwenden Sie Leiter-Tests: Starten Sie mit dem dokumentierten Maximum, beobachten Sie Latenz und Qualität, und justieren Sie nach. Kombinieren Sie moderate Fenster mit Retrieval und setzen Sie Überlauf für strukturierte Arbeit auf Stop at limit.”}}]}Kann das Kontextfenster in LM Studio über die Begrenzung des Schiebereglers hinaus vergrößert werden?
Ja. Klicken Sie auf das Zahlenfeld neben dem Schieberegler und geben Sie die gewünschte Tokenanzahl ein. Auch wenn das Feld rot wird, wendet LM Studio den Wert häufig zur Laufzeit an. Bestätigen Sie dies durch Prüfung der Logs und Tests mit einem langen Prompt.
Welche Überlaufregel ist für strukturierte Prompts am sichersten?
Stop at limit. Sie verhindert das Abschneiden mitten im Prompt und schützt System-Prompts, Funktionsschemata und Tool-Formate. Diese Einstellung ist besonders nützlich für Agenten-Arbeitsabläufe und speicherintensive Sitzungen.
Garantiert RoPE-Skalierung gute Langzeit-Kontextperformance?
Nein. RoPE-Skalierung kann den effektiven Kontext erweitern, kann aber die Kohärenz bei sehr langen Kontexten reduzieren. Verwenden Sie moderate Skalierung, validieren Sie mit realen Aufgaben und kombinieren Sie mit Retrieval für zuverlässige Ergebnisse.
Warum zeigen manche Modelle 16k max, obwohl die Karte 128k angibt?
Diese Diskrepanz spiegelt oft Metadaten im Konvertierungspaket wider. Versuchen Sie, manuell einen höheren Wert einzugeben und prüfen Sie die angewandte Länge zur Laufzeit; betrachten Sie den Schieberegler als Richtwert, nicht als verbindliche Grenze.
Wie wählt man die richtige Fenstergröße für lokale Textgenerierung?
Verwenden Sie Leiter-Tests: Starten Sie mit dem dokumentierten Maximum, beobachten Sie Latenz und Qualität, und justieren Sie nach. Kombinieren Sie moderate Fenster mit Retrieval und setzen Sie Überlauf für strukturierte Arbeit auf Stop at limit.



Kannst du das Kontextfenster in lmstudio ändern?
Ändern des Kontextfensters in LM Studio: was es ist und warum es wichtig ist Der Begriff Kontextfenster beschreibt, wie viel...


Wie bekommt man die aktuelle Zeit in Swift
Swift Essentials: Wie man die aktuelle Uhrzeit mit Date, Calendar und DateFormatter erhält Die aktuelle Uhrzeit in Swift zu erhalten...


Wie Vape-Detektoren die Sicherheit an Schulen im Jahr 2025 verändern
Wie Vape-Detektoren die Sicherheit an Schulen im Jahr 2025 verändern: datengetriebene Transparenz ohne Überwachungswahn Auf Schulgeländen groß und klein haben...


Befeuert KI Wahnideen? Besorgnis wächst bei Familien und Experten
Beheizt KI Wahnvorstellungen? Familien und Experten verfolgen ein beunruhigendes Muster Berichte über KI-verstärkte Wahnvorstellungen haben sich von Randanekdoten zu stetigen...


Wie man Python-Umgebungen mit conda env create im Jahr 2025 erstellt und verwaltet
Conda env create im Jahr 2025: Schritt für Schritt isolierte, reproduzierbare Python-Umgebungen aufbauen Saubere Isolation ist die Grundlage für verlässliche...


Entfesseln Sie die Kraft des ChatGPT Gruppen-Chats kostenlos: Eine Schritt-für-Schritt-Anleitung zum Einstieg
Wie man kostenlosen Zugang erhält und einen ChatGPT-Gruppenchat startet: Eine Schritt-für-Schritt-Anleitung für den Einstieg Der ChatGPT-Gruppenchat hat die Pilotphase verlassen...


Wie Sie 2025 Ihre Vorteile aus meinen Bewertungen maximieren
Wie Sie Ihre Vorteile aus meinen Bewertungen 2025 maximieren: Strategie, ROI und Umsetzung Evaluierungen 2025 sind nur so wertvoll wie...

Planen Sie Ihre nächste Auszeit direkt hier: TripAdvisor startet integrierte App innerhalb von ChatGPT
Die integrierte TripAdvisor-App in ChatGPT: Der Game-Changer für Reiseplanung und Buchung Die Einführung der TripAdvisor-integrierten App innerhalb von ChatGPT katapultiert...


wie Klonmaschinen die Wissenschaft und Medizin im Jahr 2025 revolutionieren
Klonmaschinen im Jahr 2025: Cloud-native Biofabriken, die eine Biotechnologie-Revolution vorantreiben Klonmaschinen im Jahr 2025 sind keine einzelnen Geräte – sie...


vietnamesische Models im Jahr 2025: neue Gesichter und aufstrebende Stars, die man beobachten sollte
Vietnamesische Models im Jahr 2025: backstage Power und neue Gesichter auf globalen Laufstegen Die Diskussion um vietnamesische Models im Jahr...

Wie man YouTube-Videos 2025 ganz einfach herunterlädt: ein kompletter Leitfaden
Sichere und legale Möglichkeiten, YouTube-Videos im Jahr 2025 herunterzuladen: Was Creators wissen müssen Bevor Sie einen Video-Downloader verwenden, gibt es...


Erfolg freisetzen: die Bedeutung und Kraft hinter „Du verfehlst jeden Schuss, den du nicht abgibst“
Erfolg freischalten: Ursprung und reale Kraft hinter „Du verpasst jeden Schuss, den du nicht abgibst“ Der oft zitierte Satz „Du...


Entdeckung der Einkaufsforschung mit ChatGPT: Eine neue Ära der intelligenten Shopping-Unterstützung
ChatGPT Shopping Research: Intelligente Einkaufsunterstützung, die Fragen in sichere Entscheidungen verwandelt Shopping Research in ChatGPT führt ein zweiseitiges Gespräch ein,...


Ein umfassender Leitfaden zur Webnavigation mit ChatGPT im Jahr 2025
Webnavigation mit ChatGPT Atlas: Grundlagen des Smart Browsings für ein besseres Nutzererlebnis Die Webnavigation hat sich verändert, seit ChatGPT Atlas...


Erkundung der besten ChatGPT-Bibliotheken zur Verbesserung Ihrer Projekte im Jahr 2025
Wesentliche ChatGPT-Bibliotheken für schnelle Projektverbesserungen im Jahr 2025 Organisationen, die Projektverbesserungen mit Conversational AI anstreben, konzentrieren sich auf einen pragmatischen...


Showdown der Titanen: Wer wird 2025 den Thron besteigen, ChatGPT oder Bard?
KI-Titanen im Fokus: Das Duell der Titanen zwischen ChatGPT und Bard (Gemini) um die Vorherrschaft im Jahr 2025 Das Rampenlicht...


Top KI-Anwendungen, die die Inneneinrichtung im Jahr 2025 revolutionieren
Top KI-Anwendungen, die 2025 die Innenarchitektur revolutionieren: Visuelle Intelligenz und generatives Konzeptdesign Fotorealistische Visualisierungen haben sich von einem netten Extra...


Wie viele Wochen ab heute? Ein praktischer Leitfaden zum Zählen der Wochen im Jahr 2025
Wie viele Wochen ab heute? Zuverlässige Methoden zur Datumsberechnung für Zeitpläne 2025 Praktische Planung beginnt oft mit einer einfachen Frage:...


Wie OpenAI reagierte, als ChatGPT-Nutzer die Realität zu entgleiten begann
Warnungen vor Realitätsverlust: Wie OpenAI frühe Signale in ChatGPT-Gesprächen verfolgte Als Anzeichen von Realitätsverlust in ChatGPT-Austauschen auftauchten, machte die Größenordnung...


Verstehen von agentic ai vista: Hauptmerkmale und praktische Anwendungen im Jahr 2025
Agentic AI Vista im Jahr 2025: Schlüsselfunktionen, die autonome Agenten neu definieren Agentic AI Vista signalisiert eine entscheidende Verschiebung von...
-
KI-Modelle8 hours ago
vietnamesische Models im Jahr 2025: neue Gesichter und aufstrebende Stars, die man beobachten sollte
-
5 hours ago
Entfesseln Sie die Kraft des ChatGPT Gruppen-Chats kostenlos: Eine Schritt-für-Schritt-Anleitung zum Einstieg
-

 Tech3 days ago
Tech3 days agoIhre Karte unterstützt diesen Kaufart nicht: was das bedeutet und wie Sie das Problem lösen können
-

 KI-Modelle2 days ago
KI-Modelle2 days agoOpenAI vs Tsinghua: Die Wahl zwischen ChatGPT und ChatGLM für Ihre KI-Bedürfnisse im Jahr 2025
-
Innovation3 hours ago
Wie Vape-Detektoren die Sicherheit an Schulen im Jahr 2025 verändern
-
KI-Modelle17 hours ago
Showdown der Titanen: Wer wird 2025 den Thron besteigen, ChatGPT oder Bard?