
Modelos de IA
¿Puedes cambiar la ventana de contexto en lmstudio?
Cambiar la ventana de contexto en LM Studio: qué es y por qué importa
El término ventana de contexto describe cuánto texto puede considerar un modelo de lenguaje a la vez. En LM Studio (a menudo abreviado como lmstudio por los practicantes), esta ventana regula la longitud máxima de entrada y la cantidad de conversación pasada o documentos que influyen en la generación de texto actual. Si se supera el límite de tokens, se truncan detalles importantes, lo que puede desviar las respuestas o producir razonamientos superficiales. Por lo tanto, ajustar el tamaño de ventana es una de las configuraciones de IA más importantes disponibles para cualquiera que ejecute modelos localmente.
¿Por qué cambiarla? Los equipos a menudo manejan PDFs grandes, historiales extensos de chat o archivos fuente largos. Un investigador que compila memorandos de 30 páginas necesita más espacio que un chatbot rápido. Un desarrollador que analiza una base de código con múltiples archivos también se beneficia de un búfer mayor. LM Studio expone parámetros del modelo en tiempo de carga (por ejemplo, longitud de contexto) y en tiempo de inferencia (por ejemplo, comportamiento cuando hay desbordamiento), permitiendo configuraciones adaptadas para diferentes cargas de trabajo. Elegir el tamaño correcto es equilibrar velocidad, costo (en VRAM y RAM) y fidelidad de las respuestas.
Considera a “Maya,” una analista de datos que selecciona reportes de cumplimiento. Cuando la ventana está muy ajustada, Maya ve desaparecer las citas y las referencias se vuelven vagas. Tras aumentar la longitud de contexto en LM Studio, el modelo retiene más notas al pie, responde con punteros precisos y mantiene terminología consistente a lo largo de cientos de líneas. La diferencia no es cosmética; cambia lo que el modelo puede saber en mitad de la conversación.
Las razones clave por las que los usuarios aumentan el límite incluyen esquemas de llamada de funciones más largos, indicaciones complejas del sistema y chats de múltiples turnos con documentos adjuntos. La configuración de LM Studio permite ajustar el comportamiento más allá de los valores predeterminados, pero es vital conocer los máximos específicos del modelo. Algunos modelos vienen con 4k–16k tokens por defecto; otros anuncian 128k o más. El desempeño real depende tanto del entrenamiento del modelo como del enfoque en tiempo de ejecución (por ejemplo, codificación posicional y estrategias de atención).
- 🔧 Amplía el tamaño de la ventana para preservar instrucciones largas y reducir la truncación.
- 🧠 Mejora el razonamiento sobre múltiples documentos manteniendo más contexto en memoria.
- ⚡ Equilibra velocidad y calidad; ventanas más grandes pueden ralentizar la generación.
- 🛡️ Usa políticas de desbordamiento para controlar la seguridad al alcanzar el límite de tokens.
- 📈 Monitorea las compensaciones de calidad al usar técnicas de contexto extendido.
La elección del tamaño adecuado también depende de la tarea. Para asistencia en programación de alta precisión, considera un contexto medio más recuperación dirigida. Para análisis literarios o revisión legal, una ventana grande es útil—si el modelo la maneja bien. En el ecosistema de 2025, comparaciones como ChatGPT versus Perplexity y OpenAI versus Anthropic resaltan cómo las familias de modelos priorizan de manera diferente el razonamiento con contexto largo. Los ejecutores locales desean el mismo poder, pero deben configurarlo sabiamente.
| Concepto ✨ | Qué controla 🧭 | Impacto en los resultados 📊 |
|---|---|---|
| Ventana de contexto | Máximo tokens que el modelo puede “ver” | Retención de instrucciones y referencias |
| Tamaño de ventana | Longitud de contexto en tiempo de carga | Latencia, uso de memoria, coherencia |
| Política de desbordamiento | Cómo comportarse al límite | Seguridad, determinismo o patrones de truncado |
| Parámetros del modelo | Escalado RoPE, caché kv, etc. | Longitud máxima efectiva y estabilidad |
| Configuraciones de IA | Configuración UI en LM Studio | Ajuste de flujo de trabajo para distintas tareas |
En resumen: cambiar la longitud de contexto en LM Studio no es solo un interruptor — es una elección estratégica que decide cuánto puede recordar y razonar el modelo en una sola pasada.

Controles de LM Studio: política de desbordamiento, deslizadores y el truco de la “caja roja”
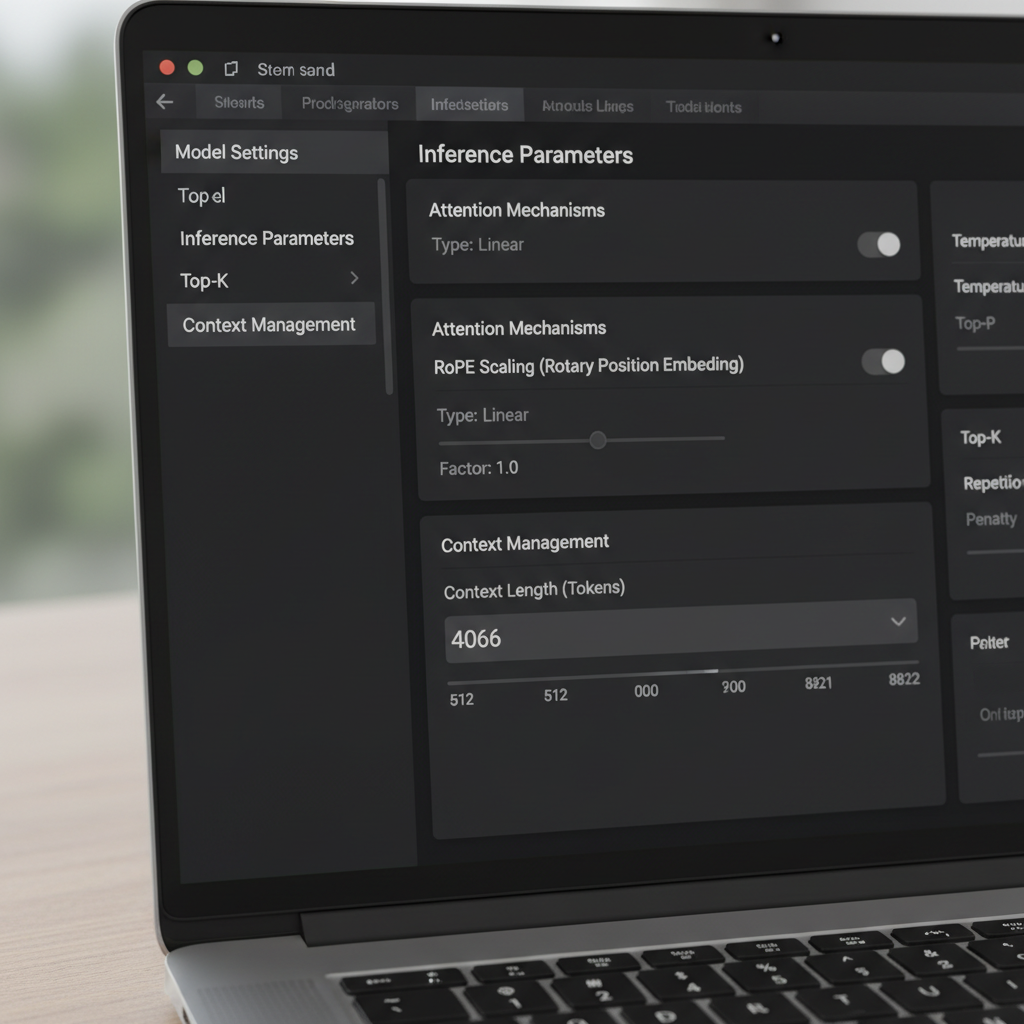
LM Studio ofrece múltiples formas de cambiar la ventana de contexto. En la UI, un deslizador y un campo numérico controlan el tamaño de ventana configurado. Un detalle reportado por usuarios de la comunidad es un deslizador limitado a 16k para ciertas cuantizaciones, a pesar de que los metadatos del modelo subyacente soportan más (por ejemplo, 128k). Cuando el deslizador no avanza más, muchos usuarios simplemente hacen clic en la caja numérica y escriben el conteo de tokens deseado. El valor puede volverse rojo y advertir que no se guardará—sin embargo, sigue aplicándose en tiempo de ejecución. Ese comportamiento sorprendente permite a usuarios avanzados evitar la fricción de la UI sin herramientas personalizadas.
Otra configuración crítica es la Política de Desbordamiento de Contexto. La opción predeterminada “mantener el prompt del sistema, truncar el medio” puede romper ciertos gestores de memoria y agentes. Cambiar a Detener al límite asegura que el modelo se detenga en lugar de desconfigurar la mitad de un prompt estructurado. Usuarios que integran marcos de memoria o herramientas similares a MemGPT han reportado muchas menos anomalías tras elegir “Detener al límite.” Es una solución simple que preserva la estructura y evita la corrupción silenciosa de texto importante.
Las diferencias de versión importan. Algunos usuarios observaron que, a partir de una compilación específica 0.3.24, la UI ya no guarda tamaños de contexto por encima del máximo anunciado, por lo que deben editar archivos de configuración ocultos o ejecutar temporalmente una versión anterior que permitía valores manuales. La clave es que cambiar el campo numérico actualiza frecuentemente un parámetro en tiempo de ejecución, mientras que ciertas entradas JSON son metadatos para la visualización y no afectan la conversión del modelo. Entender esta distinción evita re-cuantizaciones o manejar archivos innecesariamente.
Para equipos que adoptan LLMs locales, un pequeño manual reduce errores. Primero, verifica el máximo contexto documentado del modelo. Segundo, ajusta el campo numérico de LM Studio a ese máximo, incluso si el deslizador se queda corto. Tercero, configura el desbordamiento en “Detener al límite” para prompts estructurados. Finalmente, prueba con un documento largo sintético para confirmar que el contenido más allá del límite anterior ahora se reconoce y referencia correctamente.
- 🧩 Si el deslizador se limita a 16k, escribe el número directamente en la caja.
- 🛑 Prefiere Detener al límite cuando necesites estructura estricta.
- 🧪 Valida con un prompt largo falso para demostrar que el cambio surtió efecto.
- 📂 Trata los límites de config.json como metadatos de UI salvo que la documentación indique lo contrario.
- 💡 Toma nota de la versión de LM Studio y el diario de cambios para el comportamiento del rango de contexto.
Estos pasos funcionan bien junto con evaluaciones más amplias. Por ejemplo, leer análisis de características como Gemini versus ChatGPT y la reseña de ChatGPT 2025 ayuda a enmarcar las expectativas para el rendimiento con contexto largo en los ecosistemas. Observar dónde los gigantes cloud enfatizan el contexto también guía la configuración local.
| Acción 🔁 | Dónde en LM Studio 🖥️ | Por qué ayuda ✅ |
|---|---|---|
| Escribir longitud de contexto manualmente | Campo numérico junto al deslizador | Evita el límite de UI de 16k 🪄 |
| Configurar desbordamiento en “Detener al límite” | Configuración de inferencia | Evita truncado a mitad de prompt 🧱 |
| Revisar metadatos del modelo | Panel de información del modelo | Confirma longitud máxima anunciada 📜 |
| Verificar versión | Acerca de o notas de lanzamiento | Explica cambios en la forma de guardar 🗂️ |
| Prueba con prompt largo | Vista de chat o composición | Validación empírica del nuevo tamaño 🧪 |
Para profundizar en hábitos de configuración y comparaciones prácticas, los videos sobre configuración de LLM local resultan útiles.

Con estos controles, los equipos pueden empujar a LM Studio más allá de los valores predeterminados y proteger sus prompts de truncaciones no detectadas.
Ir más allá de los límites de entrenamiento: escalado RoPE y longitud efectiva de contexto
Extender el contexto no es solo cuestión de deslizadores. Muchos modelos basados en transformadores dependen de Embeddings Posicionales Rotatorios (RoPE), y LM Studio expone un parámetro en tiempo de carga que escala la información posicional. Aumentar este factor permite que los modelos atiendan secuencias más largas volviendo la codificación posicional más granular. Es un truco poderoso—pero no gratuito. Al aumentar el factor, la coherencia local puede deteriorarse y algunos modelos alucinan más con longitudes extremas. Saber cuándo usar el escalado RoPE es tan importante como saber cómo usarlo.
La documentación de LM Studio describe cómo un factor de escalado ajusta la ventana efectiva. En la práctica, eso significa que un modelo entrenado para 8k puede operar a veces a 16k–32k con pérdida de calidad tolerable, dependiendo de la arquitectura y cuantización. Cuando los usuarios reportan una compilación GGUF mostrando un máximo de 16k en la UI pero el modelo upstream promete 128k, suele indicar un desajuste de metadatos. En esos casos, aumentar el valor numérico y validar con una conversación larga de prueba aclara el techo real. Reportes comunitarios también indican que editar el valor—incluso si la UI lo resalta en rojo—puede seguir aplicando la longitud deseada en tiempo de carga.
¿Hasta dónde se puede llegar? Eso depende de la familia del modelo y del mecanismo de atención. Enfoques como atención deslizante y diseños híbridos recurrente/transformador toleran contextos largos de manera distinta a la atención simple. El interés en alternativas, incluyendo modelos de espacio de estados, ha crecido a medida que los equipos exploran secuencias largas sin aumentar exorbitantemente la memoria. Las discusiones sobre modelos de espacio de estados y uso de memoria resaltan por qué el contexto largo no es solo un número; es una cuestión de estabilidad y arquitectura.
El equipo de Maya usó el escalado RoPE de manera juiciosa para resúmenes trimestrales. A 24k tokens, las respuestas se mantuvieron claras. A 48k, la latencia creció y los resúmenes a veces olvidaron detalles iniciales, lo que sugiere rendimientos decrecientes. Se decidieron por 32k con aumento de recuperación, que preservó calidad evitando grandes ralentizaciones. La lección: las ventanas grandes deberían complementar la recuperación y la segmentación, no reemplazarlas.
- 🧮 Comienza con escalado moderado (p. ej., 1.5–2×) antes de ir más alto.
- 🧭 Combina contexto largo con recuperación para que el modelo vea solo fragmentos relevantes.
- 📉 Observa caídas en coherencia a conteos muy altos de tokens.
- 🧰 Ten en cuenta la cuantización y límites de VRAM al estirar la ventana.
- 🔍 Valida con pruebas largas específicas del dominio en vez de prompts genéricos.
Escrituras comparativas como ChatGPT vs. Gemini en 2025 y resúmenes como hitos en la evolución de ChatGPT ofrecen un contexto más amplio sobre cómo los proveedores enfocan la carrera del contexto largo. Incluso si el modelo local es distinto, las compensaciones se reflejan en todo el campo.
| Elección de escalado RoPE 🧯 | Pros 🌟 | Contras ⚠️ | Úsalo cuando 🎯 |
|---|---|---|---|
| 1.0× (predeterminado) | Comportamiento estable y predecible | Longitud máxima limitada | Tareas críticas de calidad ✅ |
| 1.5–2.0× | Contexto visiblemente más largo | Pequeña pérdida de coherencia | Reportes, análisis ligero de código 📄 |
| 2.5–4.0× | Sesiones grandes con múltiples documentos | Latencia, riesgos de deriva | Investigación exploratoria 🔬 |
| 4.0×+ | Secuencias extremas | Salidas inestables probables | Benchmarks y experimentos 🧪 |
El insight pragmático: el escalado RoPE puede extender el alcance, pero la recuperación y la ingeniería de prompts a menudo ofrecen ganancias más estables por token.
Cuando el tamaño de ventana no cambia: solución de problemas con contexto largo en LM Studio
Ocasionalmente, LM Studio se resiste a un cambio. Los usuarios han reportado un deslizador “máximo 16k” para ciertas cuantizaciones, aunque el modelo base anuncia mucho más. Otros vieron que una versión más nueva impide guardar valores más altos, empujándolos a usar temporalmente una versión anterior o escribir valores directamente a pesar de las advertencias en colores. Estos problemas son frustrantes pero solucionables con un checklist sistemático.
Primero, confirma el máximo anunciado del modelo. Algunas fichas comunitarias listan erróneamente 16k debido a un error de empaquetado, mientras el modelo real soporta 128k. Segundo, prueba escribir el número en el campo de texto; si se vuelve rojo pero carga, habrás evitado el límite del deslizador. Tercero, configura la política de desbordamiento en “Detener al límite” para evitar dañar un prompt del sistema cuidadosamente elaborado. Cuarto, valida con un conjunto largo de párrafos falsos y pide al modelo que resuma secciones tempranas, medias y tardías para demostrar que tiene plena visibilidad.
Si LM Studio sigue negándose, considera si la variante de cuantización tiene un límite estricto en sus metadatos. Algunas conversiones GGUF incluyen un contexto por defecto diferente al original. Como el límite puede actuar como metadato de visualización en vez de ser un techo obligatorio, la aproximación por campo de texto suele ser suficiente; aun así, revisa los registros en carga para confirmar. Asegúrate también de que la VRAM sea suficiente. Ventanas muy grandes inflan la caché key-value, causando ralentizaciones o errores por falta de memoria. Si los fallos persisten, reduce un poco el contexto, usa cuantización de menor precisión o divide la tarea en fragmentos.
Más allá de LM Studio, es sensato seguir cómo los modelos líderes manejan prompts largos en la práctica. Análisis como ChatGPT vs. Claude y textos profundos como cómo DeepSeek mantiene el entrenamiento asequible informan las expectativas. El contexto largo tiene sentido solo si el modelo lo usa fielmente; de lo contrario, la recuperación o mejor estructura de prompts pueden superar el mero aumento de tamaño.
- 🧰 Si el deslizador se detiene en 16k, prueba el campo numérico de todos modos.
- 🧯 Cambia el desbordamiento a “Detener al límite” para tareas estructuradas.
- 🧠 Valida comprensión temprana/media/tardía con un prompt largo sintético.
- 🖥️ Observa la VRAM; el contexto alto multiplica la memoria caché KV.
- 📜 Revisa los registros en carga para la longitud de contexto aplicada.
| Síntoma 🐞 | Causa probable 🔎 | Solución 🛠️ |
|---|---|---|
| Deslizador limitado a 16k | Cuestión de UI o metadatos | Escribe la longitud en el campo numérico ➕ |
| Advertencia roja al guardar | Puerta de validación, no paro duro | Carga para confirmar que aún aplica 🚦 |
| OOM o lentitud | Explosión de caché KV | Reduce contexto o usa cuantización ligera 🧮 |
| Estructura perdida | Truncado en el medio | Configura desbordamiento en “Detener al límite” 🧱 |
| Desajuste con la documentación | Metadatos de conversión | Revisa registros y haz prueba con prompt largo 🔍 |
Para aprendices visuales, los walkthroughs sobre pruebas y benchmarks de contexto largo son invaluables.

Con un checklist disciplinado, los límites de contexto tercos se vuelven una molestia temporal en vez de un bloqueo.
Elegir el tamaño correcto para la generación local de texto: manuales, pruebas y estrategia
No existe un tamaño de ventana universal. La elección correcta surge de la tarea, la familia del modelo y el hardware. Un asistente de programación se beneficia de una ventana media más recuperación de los archivos más relevantes. Un investigador legal podría priorizar una ventana más grande pero aún apoyarse en la segmentación para evitar saturar al modelo con páginas irrelevantes. Un podcaster que redacta resúmenes de episodios para transcripciones largas puede combinar un contexto generoso con una segmentación inteligente para mantener la coherencia.
Un enfoque práctico es la “prueba de escalera”: comienza con el máximo documentado, luego baja o sube mientras verificas latencia y precisión. Usa entradas largas específicas del dominio y verifica que se referencien tanto las secciones tempranas como las tardías. Si el modelo parece olvidar el inicio a tamaños más grandes, reduce la ventana o aplica el escalado RoPE con moderación. Donde los prompts ultra-largos son vitales, complementa con recuperación para que el modelo vea un fragmento seleccionado en lugar del archivo completo.
También ayuda comparar expectativas leyendo características comparativas como ChatGPT vs. GitHub Copilot y panoramas industriales como la cobertura de la demanda “bend time”. Estas referencias ofrecen contexto sobre cómo diferentes ecosistemas tratan entradas largas y flujos de trabajo para desarrolladores. En paralelo, guías sobre temas operativos—como dominar claves API—subrayan cómo los detalles de configuración impactan en ganancias reales de productividad.
- 🪜 Usa pruebas de escalera para encontrar el punto ideal para tu hardware.
- 📚 Combina ventanas largas con recuperación y segmentación para precisión.
- ⏱️ Sigue cambios en latencia conforme crece la ventana; ajusta según sea necesario.
- 🧭 Prefiere “Detener al límite” para prompts frágiles y estructurados.
- 🧪 Valida la calidad con tareas que reflejen cargas reales de trabajo.
| Caso de uso 🎬 | Contexto sugerido 📏 | Política de desbordamiento 🧱 | Notas 🗒️ |
|---|---|---|---|
| Asistente de código | 8k–24k | Detener al límite | Combinar con recuperación a nivel de archivo 💼 |
| Revisión legal | 32k–64k | Detener al límite | Segmentar por secciones; mantener citas visibles 📖 |
| Transcripciones de podcast | 16k–48k | Detener al límite | Resumir por segmentos, luego combinar 🎙️ |
| Síntesis de investigación | 24k–64k | Detener al límite | Escalado RoPE con validación cuidadosa 🔬 |
| Chat general | 4k–16k | Detener al límite | Archivar turnos anteriores, recuperar según necesidad 💬 |
Estos manuales encajan con perspectivas prácticas del mercado—véanse análisis como innovación en sistemas de razonamiento y una encuesta de apps de chatbots AI de nicho sobre cómo distintas herramientas impulsan o limitan flujos de trabajo con contexto largo. El método se mantiene: ajusta el tamaño de ventana al trabajo, luego confírmalo con pruebas que reflejen la realidad.
Notas del mundo real de la comunidad: versiones, metadatos y prácticas seguras
El feedback comunitario ha cristalizado varias verdades sobre cambiar la ventana de contexto en LM Studio. Un hilo recurrente describe un caso “Q4KM muestra un máximo de 16k” que resultó ser un problema de metadatos y no un límite duro. Otro apunta que la caja numérica de la UI acepta valores más allá del deslizador, incluso cuando está en rojo, y que estos valores se aplican en tiempo de carga. Los usuarios también confirman que la longitud de contexto en algunas configuraciones afecta más la visualización que la conversión, lo que explica por qué las ediciones aparentemente no hacen nada pero la longitud en tiempo de ejecución cambia.
El comportamiento por versión merece atención. Una compilación 0.3.24 restringió la manera de guardar valores por encima del máximo, lo que llevó a algunos usuarios a revertir a una versión anterior que permitía entradas manuales. Independientemente de la versión, la práctica más robusta es escribir el valor objetivo, configurar el desbordamiento en “Detener al límite” y validar con entradas largas. En caso de duda, confía en los registros, no en el deslizador. Claridad sobre qué es metadato versus límite obligatorio ahorra horas.
El hardware y la planificación también importan. Ventanas muy grandes expanden la caché KV y ralentizan las respuestas. Para trabajo sostenido, baja el contexto o combina contexto moderado con recuperación. Artículos de guía estratégica—como el papel de NVIDIA en escalar la infraestructura de IA—recuerdan a los equipos que la optimización del rendimiento es un ejercicio integral. Para practicantes activos, listas como códigos de error comunes ofrecen un chequeo práctico al solucionar problemas.
Finalmente, ayuda contrastar suposiciones con comparaciones más amplias. Leer cómo ChatGPT se mide con Perplexity o revisar tendencias regionales de acceso asienta expectativas para patrones de uso de contexto largo más allá de una sola herramienta. Mientras LM Studio ofrece control granular localmente, hábitos importados de modelos cloud a veces necesitan ajustes para coincidir con hardware y realidades de cuantización locales.
- 📌 Trata los límites de “16k max” en la UI como sospechosos; confirma con registros y pruebas.
- 🧭 Prefiere entradas numéricas escritas en vez de deslizadores si no concuerdan.
- 🧱 Usa “Detener al límite” para proteger prompts estructurados y agentes.
- 🧮 Observa VRAM y cuantización; ventanas largas pueden ser costosas.
- 🧪 Valida con entradas largas, realistas y específicas de la tarea.
| Insight comunitario 🗣️ | Qué significa 💡 | Paso accionable 🚀 |
|---|---|---|
| Deslizador limitado prematuramente | Probable desajuste UI/metadatos | Introduce valor manualmente, luego prueba 📏 |
| La caja roja aún funciona | Advertencia de validación, no imposición | Carga el modelo y revisa registros 🚦 |
| Config vs. conversión | Algunas entradas son solo metadatos | No reconviertas; ajusta en tiempo de ejecución 🧰 |
| Variabilidad según versión | Comportamiento cambió entre builds | Mantén un instalador estable a mano 🗃️ |
| Costo del contexto largo | La caché KV crece con tokens | Tamaño adecuado de ventana, usa recuperación 🧠 |
Para una perspectiva más amplia, comparaciones como OpenAI vs. Anthropic y resúmenes editoriales como decisiones estratégicas en talento tecnológico explican por qué la fluidez en configuración es tan importante como la elección del modelo. La conclusión duradera: verifica, prueba y documenta las configuraciones que realmente impactan tu carga de trabajo.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Can the context window be increased beyond the slider cap in LM Studio?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Yes. Click the numeric field next to the slider and type the desired token count. Even if the box turns red, LM Studio frequently applies the value at load time. Confirm by checking logs and testing with a long prompt.”}},{“@type”:”Question”,”name”:”Which overflow policy is safest for structured prompts?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Stop at limit. It prevents mid-prompt truncation, protecting system prompts, function schemas, and tool formats. This setting is particularly useful for agent-style workflows and memory-heavy sessions.”}},{“@type”:”Question”,”name”:”Does RoPE scaling guarantee good long-context performance?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”No. RoPE scaling can extend effective context but may reduce coherence at very high lengths. Use modest scaling, validate with real tasks, and combine with retrieval for reliable results.”}},{“@type”:”Question”,”name”:”Why do some models show 16k max when the card says 128k?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”That mismatch often reflects metadata in the conversion package. Try entering a higher value manually and validate the applied length at runtime; treat the slider as advisory, not authoritative.”}},{“@type”:”Question”,”name”:”How to choose the right window size for local text generation?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Use ladder tests: start with the documented max, observe latency and quality, then adjust. Pair moderate windows with retrieval and set overflow to Stop at limit for structured work.”}}]}¿Se puede aumentar la ventana de contexto más allá del límite del deslizador en LM Studio?
Sí. Haz clic en el campo numérico junto al deslizador y escribe el conteo de tokens deseado. Incluso si la caja se pone roja, LM Studio frecuentemente aplica el valor en tiempo de carga. Confirma revisando los registros y probando con un prompt largo.
¿Cuál es la política de desbordamiento más segura para prompts estructurados?
Detener al límite. Previene el truncado a mitad de prompt, protegiendo prompts del sistema, esquemas de función y formatos de herramientas. Esta configuración es especialmente útil para flujos de trabajo tipo agente y sesiones con mucha memoria.
¿El escalado RoPE garantiza buen rendimiento con contexto largo?
No. El escalado RoPE puede extender el contexto efectivo pero puede reducir la coherencia en longitudes muy altas. Usa escalado modesto, valida con tareas reales y combina con recuperación para resultados confiables.
¿Por qué algunos modelos muestran un máximo de 16k cuando la ficha dice 128k?
Esa discrepancia suele reflejar metadatos en el paquete de conversión. Prueba ingresar un valor mayor manualmente y valida la longitud aplicada en tiempo de ejecución; trata el deslizador como un consejo, no una autoridad.
¿Cómo elegir el tamaño correcto de ventana para generación de texto local?
Usa pruebas de escalera: comienza con el máximo documentado, observa latencia y calidad, luego ajusta. Combina ventanas moderadas con recuperación y configura el desbordamiento en Detener al límite para trabajo estructurado.



OpenAI vs Microsoft: Diferencias clave entre ChatGPT y GitHub Copilot en 2025
División Arquitectónica en 2025: Acceso Directo al Modelo vs RAG Empresarial Orquestado La diferencia más trascendental entre ChatGPT de OpenAI...


¿Cuál Será la Principal IA para Crear un Currículum Impresionante en 2025?
¿Cuál Será la Mejor IA para Crear un Currículum Impresionante en 2025? Criterios Que Separan a los Ganadores del Resto...


Newsearch en 2025: qué esperar de la próxima generación de motores de búsqueda en línea
Newsearch en 2025: La IA generativa convierte los motores de búsqueda en asistentes La búsqueda ya no es una lista...


Chya explicado: beneficios, usos y efectos secundarios en 2025
Chya explicado en 2025: beneficios para la salud basados en evidencia, antioxidantes y densidad nutricional Chya—más conocido como chaya (Cnidoscolus...


xr actualización: las noticias e insights clave de vr para 2025
Actualización XR 2025: Noticias Empresariales de VR, Señales de ROI y Avances Sectoriales La Actualización XR en las empresas muestra...


Cómo dominar el juego de hacer clic en la barra espaciadora en 2025
Fundamentos del Clicker de Barra Espaciadora: CPS, Bucles de Retroalimentación y Dominio en el Juego Temprano Los juegos de clicker...


i letra burbuja: ideas creativas y tutoriales para principiantes
Cómo dibujar una letra burbuja i: tutorial paso a paso para principiantes absolutos Comenzar con la letra burbuja i minúscula...


Presentando una versión gratuita de ChatGPT diseñada específicamente para educadores
Por qué importa un ChatGPT gratuito para educadores: espacio de trabajo seguro, controles administrativos y herramientas de enseñanza enfocadas ChatGPT...


Una visión integral del panorama tecnológico en Palo Alto para 2025
Plataformización impulsada por IA en el panorama tecnológico de Palo Alto: Operaciones de seguridad reinventadas El panorama tecnológico de Palo...


¿Es realmente tan difícil AP Physics? Lo que los estudiantes deben saber en 2025
¿Realmente es tan difícil AP Physics en 2025? Datos, tasas de aprobación y lo que realmente importa Pregunta a un...


Servicio de ChatGPT Interrumpido: Usuarios Experimentan Caídas en Medio de la Interrupción de Cloudflare | Hindustan Times
Servicio de ChatGPT Interrumpido: Interrupción de Cloudflare Provoca Fallos Globales y Errores 500 Olas de inestabilidad recorrieron la web cuando...


Las mejores AIs de escritura de 2025: una comparación completa y guía para usuarios
Las mejores IA de escritura de 2025: rendimiento comparativo y casos de uso reales Elegir una IA de escritura en...


Comprendiendo la persistencia de imagen: causas, prevención y soluciones
Entendiendo la persistencia de imagen vs. quemado de pantalla: definiciones, síntomas y dinámica de la imagen residual en pantallas La...


¿Puedes cambiar la ventana de contexto en lmstudio?
Cambiar la ventana de contexto en LM Studio: qué es y por qué importa El término ventana de contexto describe...


Cómo obtener la hora actual en swift
Aspectos esenciales de Swift: Cómo obtener la hora actual con Date, Calendar y DateFormatter Obtener la hora actual en Swift...


Cómo los detectores de vapeo están transformando la seguridad escolar en 2025
Cómo los detectores de vapeo están transformando la seguridad escolar en 2025: visibilidad basada en datos sin invasión de privacidad...


¿Está la IA alimentando delirios? Crecen las preocupaciones entre familias y expertos
¿Está la IA alimentando delirios? Familias y expertos siguen un patrón preocupante Los informes sobre Delirios reforzados por IA han...


Cómo crear y gestionar entornos de Python con conda env create en 2025
Conda env create en 2025: construyendo entornos de Python aislados y reproducibles paso a paso El aislamiento limpio es la...


Desbloquea el Poder del Chat en Grupo de ChatGPT Gratis: Una Guía Paso a Paso para Comenzar
Cómo obtener acceso gratuito y empezar un chat grupal en ChatGPT: una guía paso a paso para comenzar El chat...


Cómo maximizar tus beneficios de mis evaluaciones en 2025
Cómo maximizar tus beneficios de mis evaluaciones en 2025: Estrategia, ROI y Ejecución Las evaluaciones 2025 solo tienen valor si...
-

 Modelos de IA21 hours ago
Modelos de IA21 hours agomodelos vietnamitas en 2025: nuevas caras y estrellas emergentes para observar
-
Tecnologia8 hours ago
Una visión integral del panorama tecnológico en Palo Alto para 2025
-
17 hours ago
Desbloquea el Poder del Chat en Grupo de ChatGPT Gratis: Una Guía Paso a Paso para Comenzar
-

 Tecnologia3 days ago
Tecnologia3 days agoSu tarjeta no admite este tipo de compra: qué significa y cómo solucionarlo
-

 Modelos de IA3 days ago
Modelos de IA3 days agoOpenAI vs Tsinghua: Elegir entre ChatGPT y ChatGLM para tus necesidades de IA en 2025
-
6 hours ago
Presentando una versión gratuita de ChatGPT diseñada específicamente para educadores