
Modelli di IA
Puoi cambiare la finestra di contesto in lmstudio?
Modificare la finestra di contesto in LM Studio: cos’è e perché è importante
Il termine finestra di contesto descrive quanta parte del testo un modello linguistico può considerare contemporaneamente. In LM Studio (spesso abbreviato in lmstudio dagli operatori), questa finestra regola la lunghezza massima dell’input e la quantità di conversazioni passate o documenti che influenzano la generazione del testo attuale. Se si supera il limite di token, dettagli importanti vengono troncati, il che può compromettere le risposte o produrre ragionamenti superficiali. Regolare la dimensione della finestra è quindi una delle impostazioni AI più importanti a disposizione di chiunque esegua modelli localmente.
Perché modificarla? I team spesso gestiscono grandi PDF, lunghe cronologie di chat o file sorgente estesi. Un ricercatore che compila memo di 30 pagine ha bisogno di più spazio rispetto a un chatbot rapido. Anche uno sviluppatore che analizza un codice distribuito su più file beneficia di un buffer più ampio. LM Studio espone i parametri del modello al momento del caricamento (ad esempio, la lunghezza del contesto) e al momento dell’inferenza (ad esempio, il comportamento in caso di overflow), consentendo configurazioni personalizzate per diversi carichi di lavoro. Scegliere la dimensione giusta significa bilanciare velocità, costo (in VRAM e RAM) e fedeltà delle risposte.
Considera “Maya”, un’analista dati che cura i rapporti di conformità. Quando la finestra è troppo stretta, Maya vede sparire le citazioni e le referenze diventano vaghe. Dopo aver aumentato la lunghezza del contesto in LM Studio, il modello trattiene più note a piè di pagina, risponde con riferimenti precisi e mantiene una terminologia coerente su centinaia di righe. La differenza non è solo estetica; cambia ciò che il modello può conoscere a metà conversazione.
I motivi principali per cui gli utenti aumentano il limite includono anche schemi di chiamata funzione più lunghi, prompt di sistema complessi e chat multigiro con documenti allegati. La configurazione di LM Studio consente di regolare il comportamento oltre i valori predefiniti, ma è fondamentale conoscere i massimi specifici dei modelli. Alcuni modelli vengono consegnati con 4k–16k token di default; altri pubblicizzano 128k o più. Le prestazioni effettive dipendono sia dall’addestramento del modello sia dall’approccio al runtime (ad esempio, encoding posizionale e strategie di attenzione).
- 🔧 Espandi la dimensione della finestra per preservare istruzioni lunghe e ridurre la troncatura.
- 🧠 Migliora il ragionamento multi-documento mantenendo più contesto in memoria.
- ⚡ Bilancia velocità e qualità; finestre più grandi possono rallentare la generazione.
- 🛡️ Usa le politiche di overflow per controllare la sicurezza al raggiungimento del limite di token.
- 📈 Monitora i compromessi di qualità quando utilizzi tecniche di contesto esteso.
Scegliere la dimensione giusta dipende anche dal compito. Per un’assistenza alla programmazione ad alta precisione, considera un contesto medio più un recupero mirato. Per un’analisi letteraria o una revisione legale, una finestra ampia è utile—se il modello la gestisce davvero bene. Nell’ecosistema del 2025, confronti come ChatGPT contro Perplexity e OpenAI contro Anthropic evidenziano come le famiglie di modelli diano priorità in modo differente al ragionamento a lungo contesto. I runner locali vogliono lo stesso potere, ma devono configurarlo saggiamente.
| Concetto ✨ | Cosa controlla 🧭 | Impatto sui risultati 📊 |
|---|---|---|
| Finestra di contesto | Token massimi che il modello può “vedere” | Ritenzione di istruzioni e riferimenti |
| Dimensione finestra | Lunghezza del contesto al caricamento | Latencia, uso memoria, coerenza |
| Politica di overflow | Comportamento al limite | Sicurezza, determinismo o modalità di troncatura |
| Parametri del modello | Scaling RoPE, cache kv, ecc. | Lunghezza massima efficace e stabilità |
| Impostazioni AI | Configurazione UI in LM Studio | Flusso di lavoro adatto a diversi compiti |
In sintesi: cambiare la lunghezza di contesto in LM Studio non è solo un interruttore—è una scelta strategica che decide quanta parte il modello può ricordare e ragionare in una sola passata.

Controlli di LM Studio: politica di overflow, slider e il trucco del “riquadro rosso”
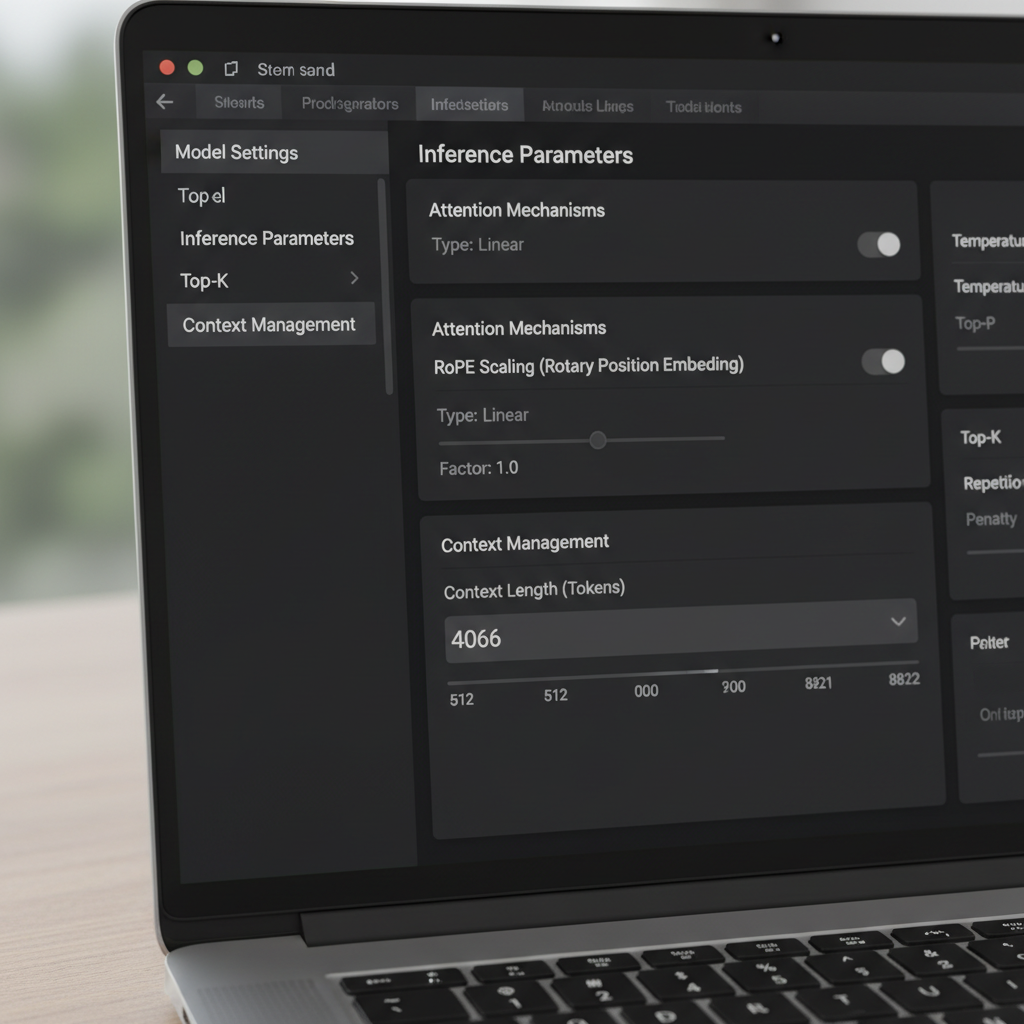
LM Studio offre più modi per modificare la finestra di contesto. Nell’interfaccia, uno slider e un campo numerico regolano la dimensione della finestra configurata. Un’anomalia segnalata dagli utenti della community è uno slider limitato a 16k per alcune quantizzazioni, nonostante i metadati sottostanti del modello supportino valori maggiori (ad esempio, 128k). Quando lo slider non scorre oltre, molti utenti scrivono direttamente nel campo numerico il conteggio di token desiderato. Il valore può diventare rosso e indicare che non si salverà—eppure si applica comunque al runtime. Questo comportamento sorprendente permette agli utenti avanzati di bypassare le limitazioni dell’interfaccia senza strumenti personalizzati.
Un’altra impostazione fondamentale è la Politica di Overflow del Contesto. L’impostazione predefinita “mantieni il prompt di sistema, tronca la parte centrale” può compromettere alcuni gestori di memoria e agenti. Passare a Stop al limite assicura che il modello si fermi invece di manomettere il centro di un prompt strutturato. Gli utenti che integrano framework di memoria o strumenti simili a MemGPT hanno riportato molte meno anomalie scegliendo “Stop al limite”. È una soluzione semplice che preserva la struttura e previene la corruzione silenziosa di testo importante.
Le differenze tra versioni sono importanti. Alcuni utenti hanno notato che a partire da una certa build 0.3.24, l’interfaccia non salva più dimensioni di contesto superiori al massimo pubblicizzato, spingendoli a modificare file di configurazione nascosti o a utilizzare temporaneamente una build precedente che supportava valori manuali. La chiave è che modificare il campo numerico aggiorna spesso un parametro in runtime, mentre alcune voci JSON sono metadati per la visualizzazione e non influenzano la conversione del modello. Comprendere questa distinzione evita riquantizzazioni inutili o gestioni complicate dei file.
Per team che iniziano con LLM locali, una piccola guida riduce errori. Primo, verifica il massimo contesto documentato del modello. Secondo, imposta il campo numerico di LM Studio a quel massimo, anche se lo slider si ferma prima. Terzo, seleziona overflow “Stop al limite” per prompt strutturati. Infine, testa con un documento lungo sintetico per confermare che contenuti oltre il precedente limite siano ora riconosciuti e citati correttamente.
- 🧩 Se lo slider si ferma a 16k, digita il numero direttamente nel campo.
- 🛑 Preferisci Stop al limite quando serve struttura rigorosa.
- 🧪 Verifica con un prompt lungo di prova per confermare la modifica.
- 📂 Considera config.json limiti come metadati UI salvo diverse indicazioni nei documenti.
- 💡 Tieni nota della versione LM Studio e del changelog sul comportamento della lunghezza del contesto.
Questi passaggi si abbinano bene a valutazioni più ampie. Ad esempio, leggere analisi come Gemini contro ChatGPT e la recensione di ChatGPT 2025 aiuta a inquadrare le aspettative per la performance a lungo contesto attraverso ecosistemi diversi. Osservare dove i giganti del cloud danno rilievo al contesto guida anche le configurazioni locali.
| Azione 🔁 | Dove in LM Studio 🖥️ | Perché aiuta ✅ |
|---|---|---|
| Digita manualmente lunghezza contesto | Campo numerico accanto allo slider | Evita il limite UI a 16k 🪄 |
| Imposta overflow su “Stop al limite” | Impostazioni di inferenza | Previene troncatura a metà prompt 🧱 |
| Controlla metadati del modello | Pannello info modello | Conferma lunghezza massima pubblicizzata 📜 |
| Controllo versione | Informazioni o note di rilascio | Spiega i cambiamenti di salvataggio 🗂️ |
| Test con prompt lungo | Chat o vista composizione | Validazione empirica della nuova dimensione finestra 🧪 |
Per approfondimenti sulle abitudini di configurazione e confronti pratici, guide video sull’installazione di LLM locali sono utili.

Con questi controlli, i team possono spingere LM Studio oltre i valori predefiniti e proteggere i loro prompt da troncature invisibili.
Spingersi oltre i limiti di addestramento: scaling RoPE e lunghezza efficace del contesto
Estendere il contesto non è solo una questione di slider. Molti modelli basati su transformer si affidano a Rotary Positional Embeddings (RoPE) e LM Studio espone un parametro al caricamento che scala le informazioni posizionali. Aumentare questo fattore permette ai modelli di prestare attenzione a sequenze più lunghe rendendo l’encoding posizionale più granulare. È un trucco potente—ma non gratuito. Con l’aumento del fattore, la coerenza locale può degradare e alcuni modelli iniziano a generare allucinazioni a lunghezze estreme. Sapere quando usare lo scaling RoPE è importante quanto sapere come usarlo.
La documentazione di LM Studio descrive come un fattore di scaling modifichi la finestra effettiva. In pratica, ciò significa che un modello addestrato per 8k può operare a 16k–32k con perdita di qualità tollerabile, a seconda dell’architettura e quantizzazione. Quando gli utenti segnalano una build GGUF che mostra un massimo di 16k nell’interfaccia ma il modello originale promette 128k, spesso indica un disallineamento nei metadati. In questi casi, aumentare il valore numerico e validare con una conversazione lunga di test chiarisce il vero limite. Rapporti dalla community indicano inoltre che modifiche al valore—anche se evidenziate in rosso nell’interfaccia—possono comunque applicare la lunghezza desiderata al caricamento.
Fino a dove si può spingere? Dipende dalla famiglia del modello e dal meccanismo di attenzione. Approcci come attenzione a finestra mobile e design ibridi ricorrente/transformer tollerano contesti lunghi diversamente dalla semplice attenzione. L’interesse per alternative, inclusi modelli a spazio di stato, è cresciuto mentre i team esplorano sequenze più lunghe senza impennate di memoria. Discussioni su modelli a spazio di stato e uso della memoria evidenziano perché il contesto lungo non è solo un numero; è una questione di stabilità e architettura.
Il team di Maya ha usato con giudizio lo scaling RoPE per riepiloghi trimestrali. A 24k token le risposte restavano nitide. A 48k la latenza cresceva e i riassunti a volte dimenticavano primi dettagli, suggerendo rendimenti decrescenti. Hanno scelto 32k con augmentazione tramite retrieval, che manteneva qualità ed evitava rallentamenti massivi. La lezione: finestre più grandi dovrebbero integrare retrieval e chunking, non sostituirli.
- 🧮 Parti da uno scaling modesto (ad esempio, 1,5–2×) prima di aumentare ulteriormente.
- 🧭 Combina contesto lungo con retrieval affinché il modello veda solo fette rilevanti.
- 📉 Osserva cali di coerenza con conteggi token molto alti.
- 🧰 Considera quantizzazione e limiti VRAM quando allunghi la finestra.
- 🔍 Valida con test lunghi specifici del dominio anziché prompt generici.
Scritti comparativi come ChatGPT vs. Gemini nel 2025 e panoramiche come tappe nell’evoluzione di ChatGPT offrono un contesto più ampio su come i fornitori inquadrano la corsa al contesto lungo. Anche se il modello locale è diverso, i compromessi si riflettono nel settore.
| Scelta scaling RoPE 🧯 | Pro 🌟 | Contro ⚠️ | Quando usarlo 🎯 |
|---|---|---|---|
| 1,0× (default) | Comportamento stabile e prevedibile | Lunghezza massima limitata | Compiti critici per qualità ✅ |
| 1,5–2,0× | Contesto sensibilmente più lungo | Leggera perdita di coerenza | Report, analisi leggere di codice 📄 |
| 2,5–4,0× | Sessioni multi-doc ampie | Rischi di latenza e deriva | Ricerca esplorativa 🔬 |
| 4,0×+ | Sequenze estreme | Output instabili probabili | Benchmark ed esperimenti 🧪 |
L’intuizione pragmatica: lo scaling RoPE può estendere la portata, ma retrieval e prompt engineering spesso danno miglioramenti più stabili per token.
Quando la dimensione della finestra non si sposta: risoluzione dei problemi di contesto lungo in LM Studio
Occasionalmente, LM Studio resiste a una modifica. Gli utenti hanno segnalato uno slider “max 16k” per certe quantizzazioni, anche se il modello base pubblicizza molto di più. Altri hanno visto una build più recente impedire il salvataggio di valori più alti, inducendoli a usare temporaneamente una versione precedente o a digitare i valori direttamente nonostante i colori di avviso. Questi problemi sono frustranti ma risolvibili con una checklist sistematica.
Prima, conferma il massimo pubblicizzato del modello. Alcune schede community elencano erroneamente 16k per un errore di confezionamento, mentre il modello effettivo supporta 128k. Secondo, prova a scrivere il numero nel campo di testo; se diventa rosso ma carica, hai bypassato la limitazione dello slider. Terzo, imposta la politica di overflow su “Stop al limite” per evitare di corrompere un prompt di sistema ben strutturato. Quarto, verifica con un set lungo di paragrafi di test e chiedi al modello di riassumere sezioni iniziali, centrali e finali per dimostrare la piena visibilità.
Se LM Studio ancora rifiuta, considera se la variante di quantizzazione ha un limite rigido nei metadati. Alcune conversioni GGUF incorporano un contesto predefinito diverso dal modello originale. Poiché il limite può agire come metadati per la visualizzazione e non come tetto effettivo, il metodo del campo di testo spesso è sufficiente; comunque, controlla i log al caricamento per conferma. Assicurati anche che la VRAM sia sufficiente. Finestre molto grandi gonfiano la cache key-value, provocando rallentamenti o errori di memoria esaurita. Se i crash persistono, riduci il contesto, usa quantizzazione meno precisa o suddividi il compito in parti.
Oltre LM Studio, è saggio monitorare come i principali modelli gestiscono prompt lunghi in pratica. Analisi come ChatGPT vs. Claude e approfondimenti tipo come DeepSeek mantiene l’addestramento accessibile informano le aspettative. Il contesto lungo ha senso solo se il modello lo usa fedelmente; altrimenti, retrieval o una migliore struttura dei prompt possono battere l’aumento di dimensione pura.
- 🧰 Se lo slider si ferma a 16k, prova comunque il campo numerico.
- 🧯 Cambia l’overflow a “Stop al limite” per compiti strutturati.
- 🧠 Verifica la comprensione iniziale, centrale e finale con un prompt sintetico lungo.
- 🖥️ Controlla la VRAM; un contesto alto moltiplica la memoria della cache KV.
- 📜 Controlla i log al caricamento per la lunghezza di contesto applicata.
| Sintomo 🐞 | Probabile causa 🔎 | Rimedi 🛠️ |
|---|---|---|
| Slider limitato a 16k | Anomalia UI o metadati | Digita la lunghezza nel campo numerico ➕ |
| Avviso rosso al salvataggio | Blocco di validazione, non fermo rigido | Carica e controlla se si applica comunque 🚦 |
| OOM o rallentamenti | Esplosione cache KV | Riduci il contesto o usa quantizzazione leggera 🧮 |
| Perdita di struttura | Troncatura centrale | Imposta overflow su “Stop al limite” 🧱 |
| Disallineamento con documenti | Metadati di conversione | Controlla i log e fai un test con prompt lungo 🔍 |
Per i più visivi, tutorial su test e benchmarking di contesto lungo sono preziosi.

Con una checklist disciplinata, i limiti ostinati del contesto diventano un fastidio temporaneo e non un blocco.
Scegliere la dimensione giusta per la generazione locale di testo: guide, test e strategia
Non esiste una dimensione finestra universalmente migliore. La scelta giusta dipende dal compito, dalla famiglia di modelli e dall’hardware. Un assistente per la programmazione trae vantaggio da una finestra media più retrieval dei file più rilevanti. Un ricercatore legale potrebbe preferire una finestra più ampia ma comunque utilizzare chunking per evitare di sovraccaricare il modello con pagine irrilevanti. Un podcaster che redige riassunti di episodi da lunghi trascritti può combinare un contesto generoso con una suddivisione intelligente per mantenere la coerenza.
Un approccio pratico è il “ladder test”: inizia dal massimo documentato, poi scendi o sali controllando latenza e accuratezza. Usa input lunghi e specifici per il dominio e verifica che sezioni iniziali e finali siano entrambe riferite. Se il modello sembra dimenticare l’inizio con dimensioni più grandi, riduci la finestra o applica lo scaling RoPE con cautela. Quando sono indispensabili prompt ultra lunghi, affianca retrieval in modo che il modello veda una fetta filtrata invece dell’archivio completo.
Aiuta anche fare benchmark delle aspettative leggendo confronti come ChatGPT vs. GitHub Copilot e panoramiche di settore come la copertura del caso “bend time”. Questi riferimenti danno contesto su come ecosistemi diversi trattano input lunghi e flussi di lavoro per sviluppatori. Parallelamente, guide su temi operativi—come come gestire le API key—sottolineano come i dettagli di configurazione si riflettano in reali guadagni di produttività.
- 🪜 Usa i ladder test per trovare il punto ideale per il tuo hardware.
- 📚 Abbina finestre lunghe a retrieval e chunking per maggior precisione.
- ⏱️ Monitora le variazioni di latenza con l’aumentare della finestra; regola di conseguenza.
- 🧭 Preferisci “Stop al limite” per prompt fragili e strutturati.
- 🧪 Valida la qualità con task che riflettano carichi di lavoro reali.
| Caso d’uso 🎬 | Contesto suggerito 📏 | Politica di overflow 🧱 | Note 🗒️ |
|---|---|---|---|
| Assistente per codice | 8k–24k | Stop al limite | Abbina a retrieval a livello di file 💼 |
| Revisione legale | 32k–64k | Stop al limite | Chunk per sezioni; mantieni le citazioni visibili 📖 |
| Trascrizioni podcast | 16k–48k | Stop al limite | Riassumi per segmento, poi unisci 🎙️ |
| Sintesi di ricerca | 24k–64k | Stop al limite | Scaling RoPE con validazione attenta 🔬 |
| Chat generale | 4k–16k | Stop al limite | Archivia i giri più vecchi, recupera se serve 💬 |
Questi playbook si integrano con prospettive di mercato più ampie—vedi analisi come innovazioni nei sistemi di ragionamento e una panoramica su app niche AI chatbot per come vari strumenti spingono o limitano i flussi di lavoro a lungo contesto. Il metodo è chiaro: regola la dimensione della finestra in base al lavoro e poi verifica con test che riflettano la realtà.
Note reali dalla community: versioni, metadati e pratiche sicure
Il feedback della community ha cristallizzato diverse verità sulla modifica della finestra di contesto in LM Studio. Un filo ricorrente descrive uno scenario “Q4KM mostra un massimo di 16k” che in realtà è un problema di metadati più che un limite rigido. Un altro osserva che la casella numerica accetta valori oltre lo slider, anche se indicati in rosso, e che questi valori si applicano al caricamento. Gli utenti confermano anche che la lunghezza del contesto in alcune configurazioni influisce più sulla visualizzazione che sulla conversione, il che spiega perché modifiche apparentemente inefficaci cambiano la lunghezza a runtime.
Il comportamento di versione merita attenzione. Una particolare build 0.3.24 ha reso più restrittivo il salvataggio di valori sopra il massimo, spingendo alcuni a tornare a una build precedente che consentiva inserimenti manuali. Indipendentemente dalla versione, la pratica più solida è digitare il valore target, impostare overflow su “Stop al limite” e validare con input lunghi. In caso di dubbi, fidati dei log, non dello slider. Chiarezza su cosa sia metadato e cosa vincolo applicato fa risparmiare ore.
Hardware e pianificazione sono altrettanto importanti. Finestre molto grandi espandono la cache KV e rallentano le risposte. Per lavoro prolungato, o si abbassa il contesto o si combina contesto moderato con retrieval. Articoli di guida strategica—come il ruolo di NVIDIA nel potenziare l’infrastruttura AI—ricordano ai team che l’ottimizzazione delle prestazioni è un esercizio end-to-end. Per gli operatori pratici, liste come codici errore comuni di ChatGPT offrono un utile confronto in fase di troubleshooting.
Infine, è utile confrontare le ipotesi con comparazioni più ampie. Leggere come ChatGPT si confronta con Perplexity o esaminare trend di accesso regionali aiuta a radicare le aspettative sull’uso del contesto lungo oltre un singolo strumento. Mentre LM Studio offre un controllo granulare in locale, abitudini importate da modelli cloud a volte richiedono aggiustamenti per adattarsi a hardware locale e realtà di quantizzazione.
- 📌 Considera sospetti i limiti UI “16k max”; conferma con log e test.
- 🧭 Preferisci inserimenti numerici manuali agli slider se discordanti.
- 🧱 Usa “Stop al limite” per proteggere prompt strutturati e agenti.
- 🧮 Monitora VRAM e quantizzazione; finestre lunghe possono essere costose.
- 🧪 Valida con input lunghi, specifici e realistici.
| Insight community 🗣️ | Cosa significa 💡 | Passo operativo 🚀 |
|---|---|---|
| Slider si blocca presto | Probabile disallineamento UI/metadati | Immetti valore manuale, poi testa 📏 |
| Riquadro rosso funziona comunque | Avviso di validazione, non enforcement | Carica modello e controlla log 🚦 |
| Config vs conversione | Alcune voci sono solo metadati | Non ricampionare; regola runtime 🧰 |
| Variabilità tra versioni | Comportamento variato tra build | Tieni a portata una versione stabile 🗃️ |
| Costo del contesto lungo | Cache KV cresce con i token | Adatta la finestra, usa retrieval 🧠 |
Per una panoramica più ampia, comparazioni come OpenAI vs. Anthropic e editoriali come scelte strategiche di talento in tecnologia inquadrano perché la fluidità nella configurazione è importante quanto la scelta del modello. Il takeaway duraturo: verifica, testa e documenta le impostazioni che realmente influenzano il tuo carico di lavoro.
{“@context”:”https://schema.org”,”@type”:”FAQPage”,”mainEntity”:[{“@type”:”Question”,”name”:”Can the context window be increased beyond the slider cap in LM Studio?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Yes. Click the numeric field next to the slider and type the desired token count. Even if the box turns red, LM Studio frequently applies the value at load time. Confirm by checking logs and testing with a long prompt.”}},{“@type”:”Question”,”name”:”Which overflow policy is safest for structured prompts?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Stop at limit. It prevents mid-prompt truncation, protecting system prompts, function schemas, and tool formats. This setting is particularly useful for agent-style workflows and memory-heavy sessions.”}},{“@type”:”Question”,”name”:”Does RoPE scaling guarantee good long-context performance?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”No. RoPE scaling can extend effective context but may reduce coherence at very high lengths. Use modest scaling, validate with real tasks, and combine with retrieval for reliable results.”}},{“@type”:”Question”,”name”:”Why do some models show 16k max when the card says 128k?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”That mismatch often reflects metadata in the conversion package. Try entering a higher value manually and validate the applied length at runtime; treat the slider as advisory, not authoritative.”}},{“@type”:”Question”,”name”:”How to choose the right window size for local text generation?”,”acceptedAnswer”:{“@type”:”Answer”,”text”:”Use ladder tests: start with the documented max, observe latency and quality, then adjust. Pair moderate windows with retrieval and set overflow to Stop at limit for structured work.”}}]}Can the context window be increased beyond the slider cap in LM Studio?
Sì. Clicca sul campo numerico accanto allo slider e digita il conteggio token desiderato. Anche se la casella diventa rossa, LM Studio applica spesso il valore al caricamento. Conferma controllando i log e testando con un prompt lungo.
Which overflow policy is safest for structured prompts?
Stop al limite. Previene la troncatura a metà prompt, proteggendo prompt di sistema, schemi di funzione e formati di strumenti. Questa impostazione è particolarmente utile per flussi agent-style e sessioni con molta memoria.
Does RoPE scaling guarantee good long-context performance?
No. Lo scaling RoPE può estendere il contesto efficace ma può ridurre la coerenza a lunghezze molto elevate. Usa uno scaling modesto, valida con task reali e combina con retrieval per risultati affidabili.
Why do some models show 16k max when the card says 128k?
Questo disallineamento spesso riflette metadati nel pacchetto di conversione. Prova a inserire un valore più alto manualmente e valida la lunghezza applicata a runtime; considera lo slider come indicativo, non vincolante.
How to choose the right window size for local text generation?
Usa i ladder test: inizia dal massimo documentato, osserva latenza e qualità, poi aggiusta. Abbina finestre moderate a retrieval e imposta overflow su Stop al limite per lavori strutturati.



OpenAI vs Microsoft: Differenze Chiave tra ChatGPT e GitHub Copilot nel 2025
Divisione Architetturale nel 2025: Accesso Diretto al Modello vs Orchestrazione Enterprise RAG La differenza più significativa tra ChatGPT di OpenAI...


Quale sarà la migliore AI per creare un curriculum impressionante nel 2025?
Quale sarà la migliore AI per creare un curriculum impressionante nel 2025? Criteri che distinguono i vincitori dalla massa Nei...


Newsearch nel 2025: cosa aspettarsi dalla prossima generazione di motori di ricerca online
Newsearch nel 2025: l’IA generativa trasforma i motori di ricerca online in assistenti La ricerca non è più una lista...


Chya spiegato: benefici, usi ed effetti collaterali nel 2025
Chya spiegata nel 2025: benefici per la salute basati su evidenze, antiossidanti e densità nutrizionale Chya—più comunemente nota come chaya...


aggiornamento xr: le principali notizie e approfondimenti vr per il 2025
Aggiornamento XR 2025: Notizie Enterprise VR, Segnali ROI e Svolte Settoriali L’aggiornamento XR nelle imprese mostra un passaggio decisivo dai...


Come padroneggiare il gioco del clicker della barra spaziatrice nel 2025
Fondamenti del Clicker sulla Barra Spaziatrice: CPS, Feedback Loop e Padronanza nel Primo Gioco I giochi clicker sulla barra spaziatrice...


i bubble letter: idee creative e tutorial per principianti
Come Disegnare una Lettera i Bubble: Tutorial Passo-Passo per Principianti Assoluti Iniziare con la lettera i bubble minuscola è un...


Presentazione di una versione gratuita di ChatGPT progettata specificamente per gli educatori
Perché una versione gratuita di ChatGPT per educatori è importante: spazio di lavoro sicuro, controlli amministrativi e strumenti didattici mirati...


Una panoramica completa del panorama tecnologico di Palo Alto entro il 2025
Piattaformizzazione guidata dall’AI nel panorama tecnologico di Palo Alto: le operazioni di sicurezza reinventate Il panorama tecnologico di Palo Alto...


è davvero così difficile AP Physics? cosa dovrebbero sapere gli studenti nel 2025
La Fisica AP è Davvero Così Difficile nel 2025? Dati, Tassi di Superamento e Cosa Conta Davvero Chiedi a una...


ChatGPT Servizio Interrotto: Utenti Sperimento Interruzioni Durante Problemi Cloudflare | Hindustan Times
Servizio ChatGPT Interrotto: Interruzione di Cloudflare Causa Blackout Globali e Errori 500 Ondata di instabilità ha attraversato il web mentre...


Top Writing AIs del 2025: una comparazione completa e guida per l’utente
Le Migliori AI di Scrittura del 2025: Prestazioni a Confronto e Casi d’Uso Reali Scegliere una AI di scrittura nel...


Comprendere la persistenza dell’immagine: cause, prevenzione e soluzioni
Comprendere la persistenza dell’immagine vs burn-in dello schermo: definizioni, sintomi e dinamiche delle immagini residue sul display La persistenza dell’immagine...


Puoi cambiare la finestra di contesto in lmstudio?
Modificare la finestra di contesto in LM Studio: cos’è e perché è importante Il termine finestra di contesto descrive quanta...


Come ottenere l’ora corrente in swift
Swift Essentials: Come Ottenere l’Ora Corrente con Date, Calendar e DateFormatter Ottenere l’ora corrente in Swift è semplice, ma i...


Come i rilevatori di vape stanno trasformando la sicurezza nelle scuole nel 2025
Come i rilevatori di vape stanno trasformando la sicurezza scolastica nel 2025: visibilità basata sui dati senza deriva da sorveglianza...


L’IA Alimenta Delusioni? Crescono Preoccupazioni tra Famiglie ed Esperti
L’IA sta alimentando deliri? Famiglie ed esperti tracciano un modello preoccupante Le segnalazioni di Deliri rinforzati dall’IA sono passate da...


Come creare e gestire ambienti Python con conda env create nel 2025
Conda env create nel 2025: costruire ambienti Python isolati e riproducibili passo dopo passo L’isolamento pulito è la base di...


Sblocca il Potere della Chat di Gruppo ChatGPT Gratis: Una Guida Passo dopo Passo per Iniziare
Come Ottenere l’Accesso Gratuito e Avviare una Chat di Gruppo ChatGPT: Una Guida Passo Passo per Iniziare ChatGPT Group Chat...


Come massimizzare i tuoi benefici dalle mie valutazioni nel 2025
Come massimizzare i tuoi benefici dalle mie valutazioni nel 2025: Strategia, ROI ed Esecuzione Le valutazioni 2025 hanno valore solo...
-

 Modelli di IA2 days ago
Modelli di IA2 days agoScegliere tra Google Bard e ChatGPT di OpenAI: quale soluzione AI è giusta per te nel 2025?
-

 Modelli di IA21 hours ago
Modelli di IA21 hours agomodel vietnamite nel 2025: nuovi volti e stelle nascenti da seguire
-
Tecnologia8 hours ago
Una panoramica completa del panorama tecnologico di Palo Alto entro il 2025
-
17 hours ago
Sblocca il Potere della Chat di Gruppo ChatGPT Gratis: Una Guida Passo dopo Passo per Iniziare
-

 Tecnologia3 days ago
Tecnologia3 days agoLa tua carta non supporta questo tipo di acquisto: cosa significa e come risolverlo
-

 Modelli di IA3 days ago
Modelli di IA3 days agoOpenAI vs Tsinghua: Scegliere tra ChatGPT e ChatGLM per le tue esigenze di IA nel 2025